(논문 요약) SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features (paper)
핵심 내용
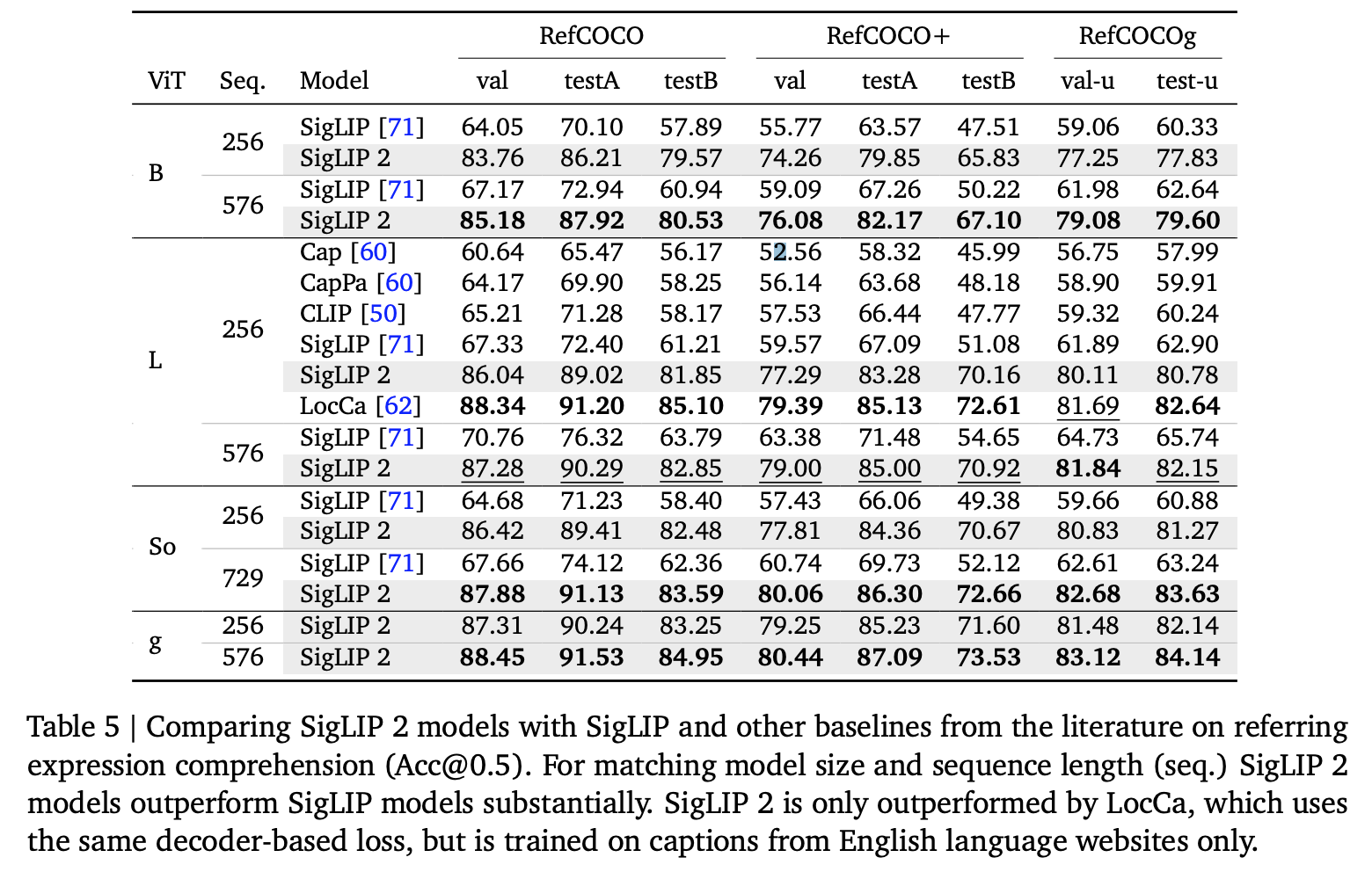
- CLIP loss (siglip-v1) 에 EMA distillation 과 autoregressive loss 추가
- 학습 데이터: WebLI dataset (10B images, 12B alt-texts, 109 languages, google-proprietary)
성능
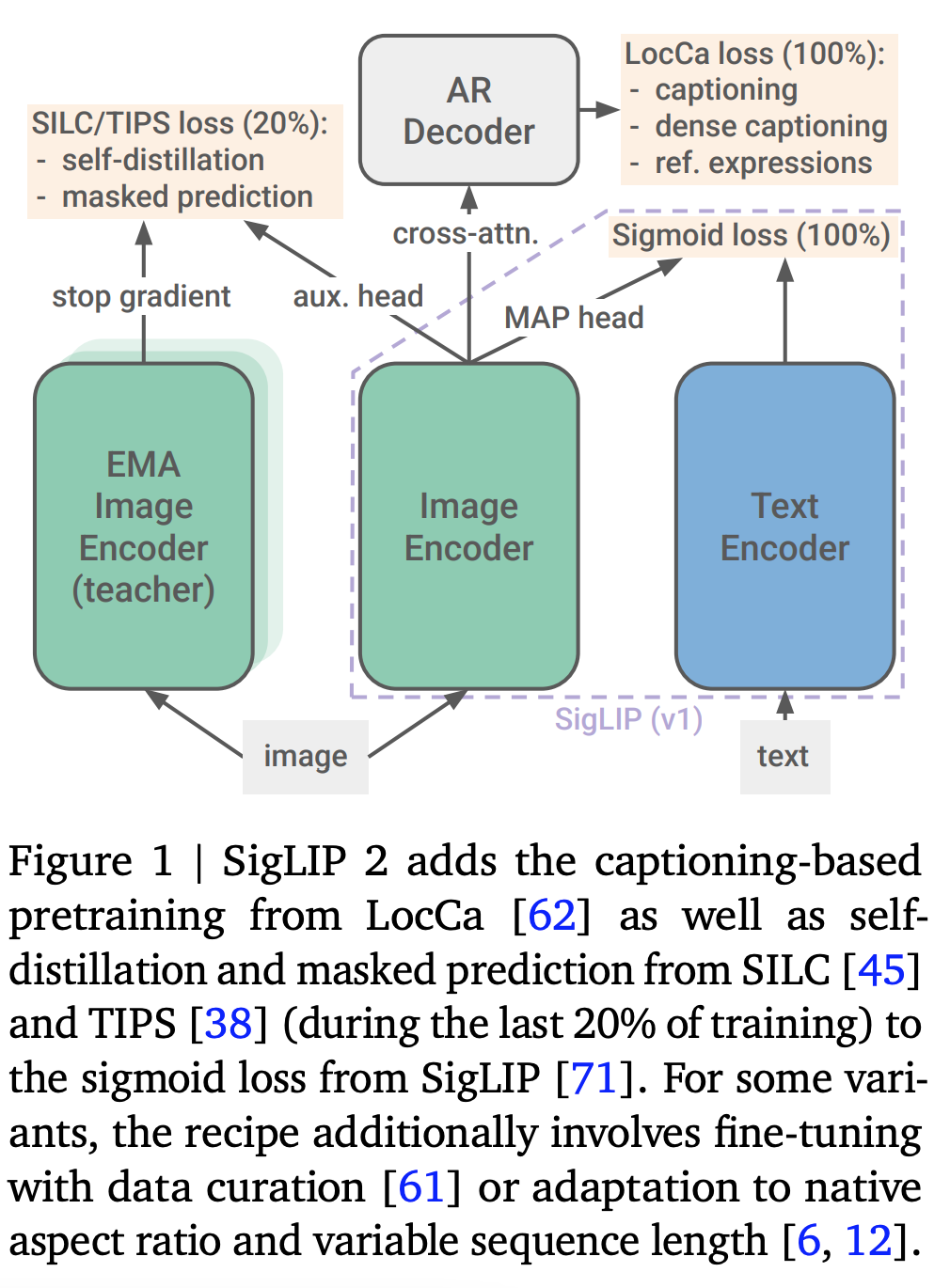
- 0-shot classification
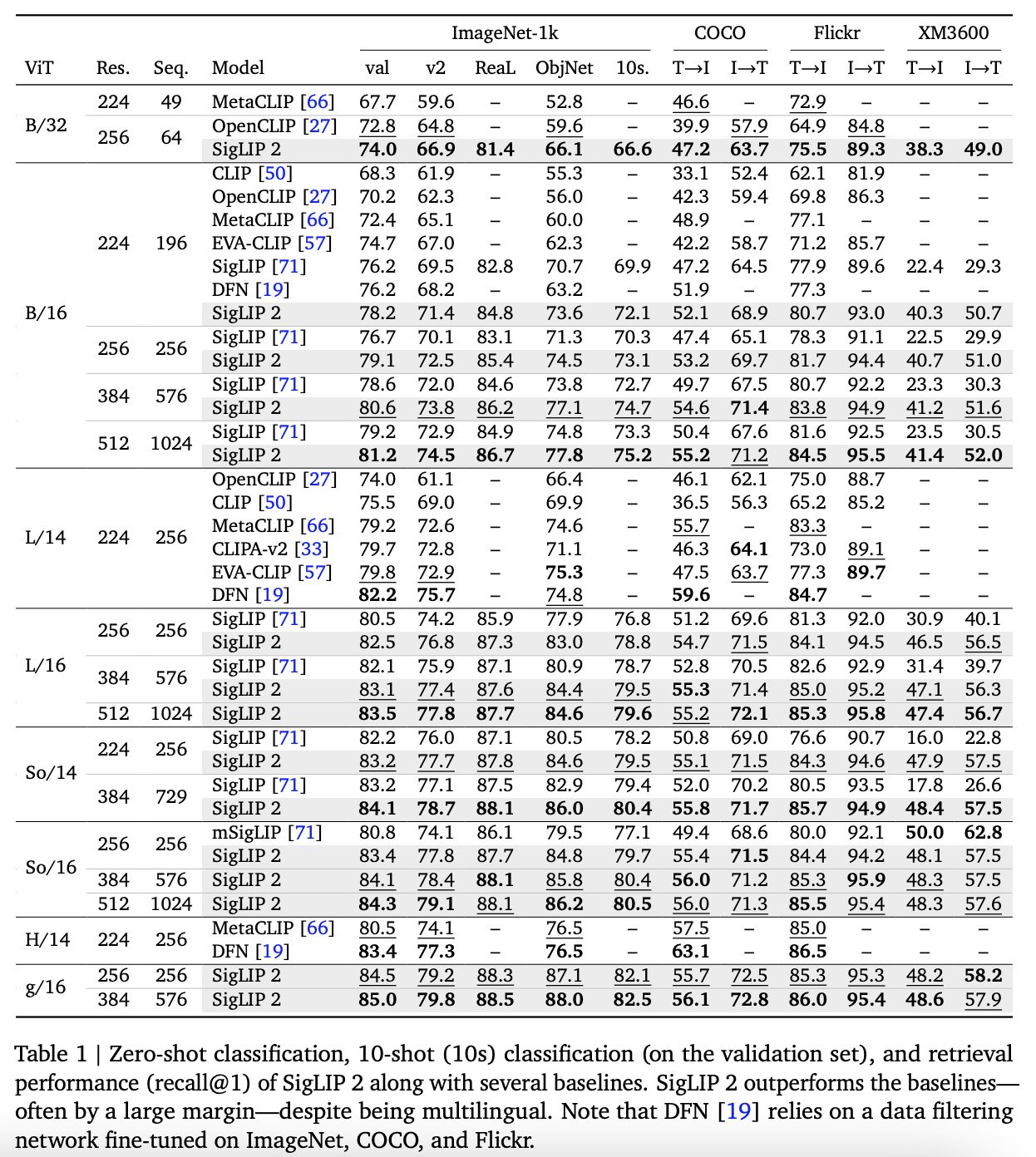
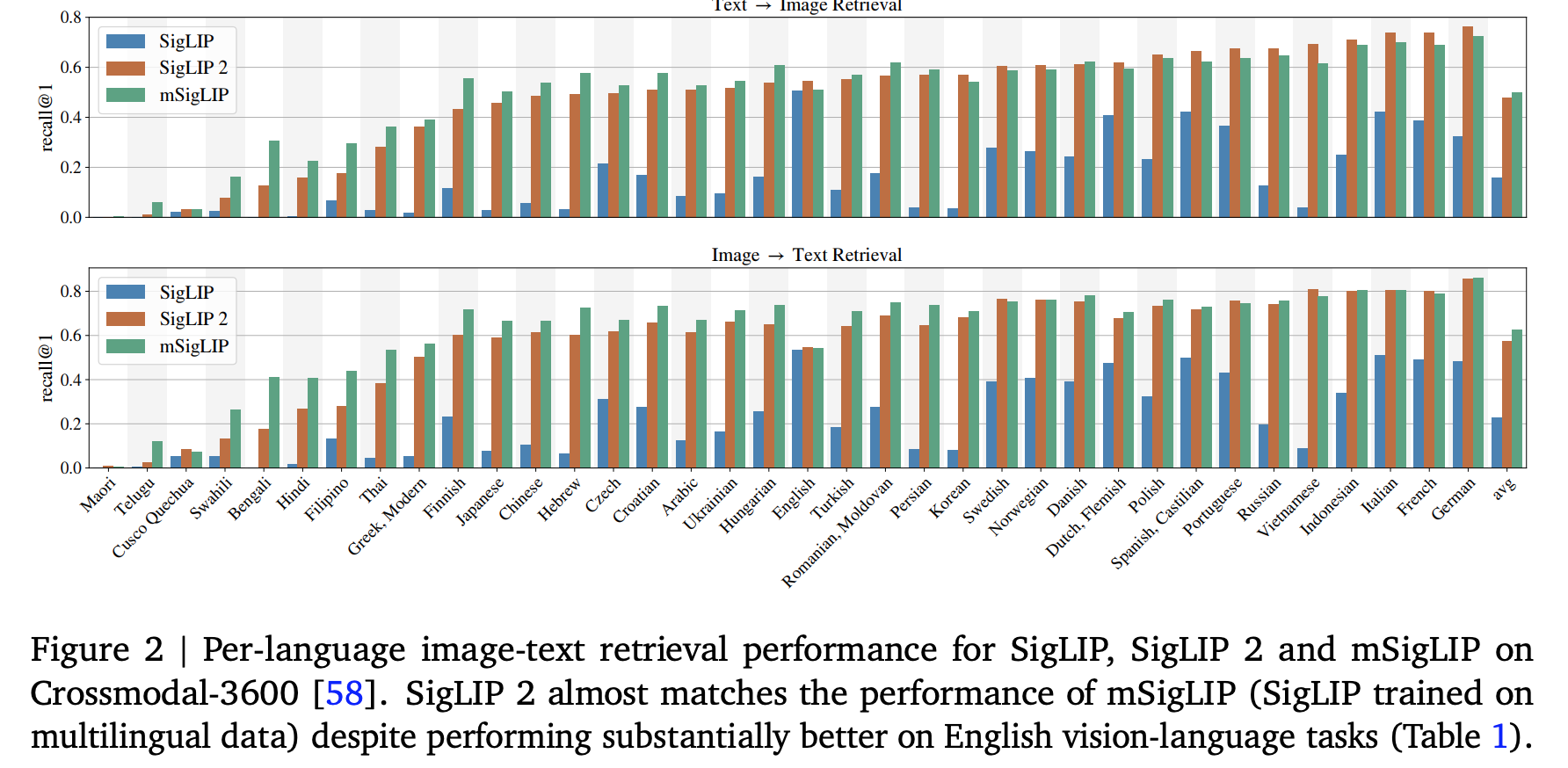
- Image retrieval 에서 SigLIP, SigLIP 2, mSigLIP 비교
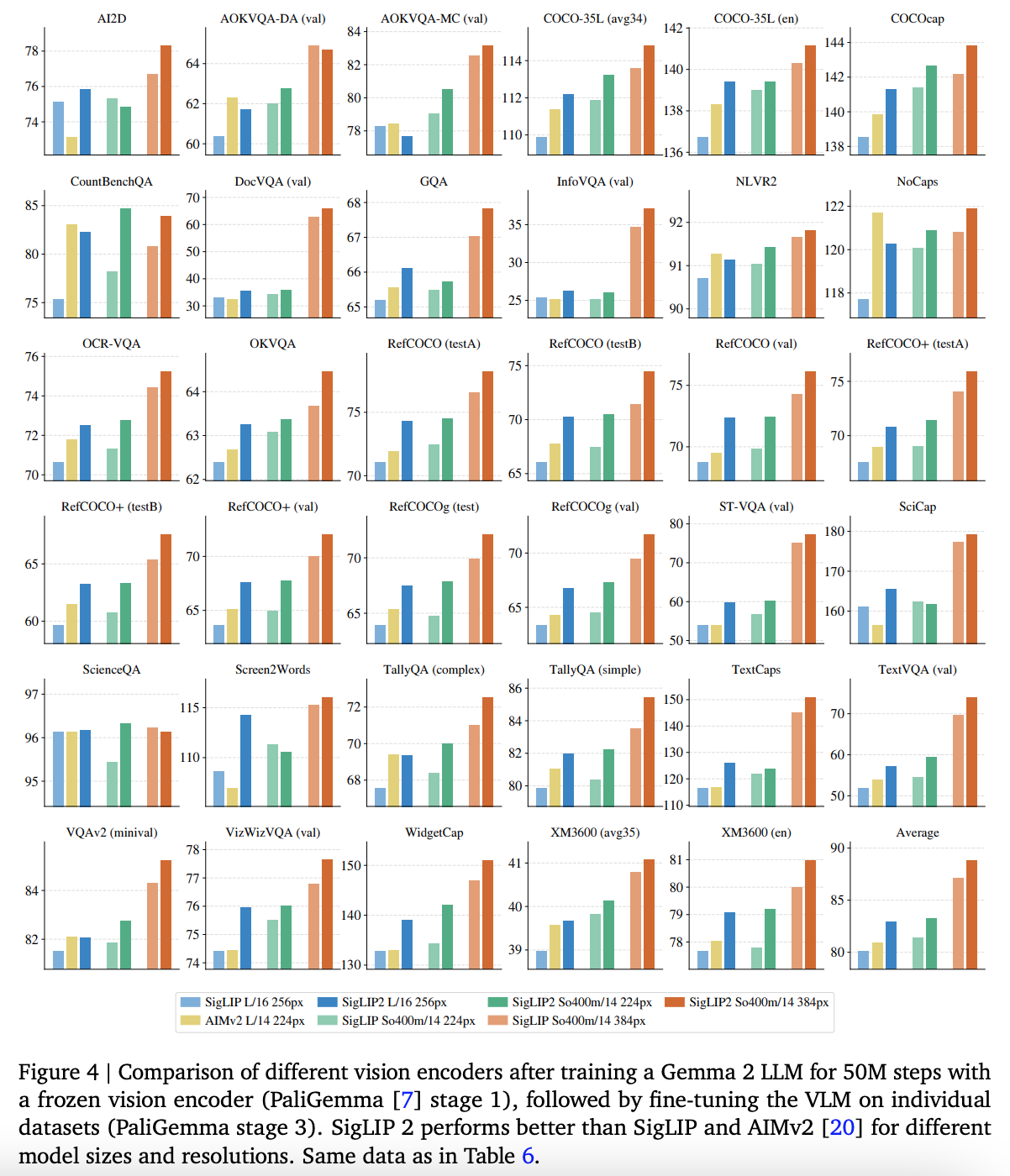
- Gemma 2 LLM 붙이고 학습 시, SigLIP, SigLIP 2, mSigLIP 성능 비교
- 6-layer transformer decoder 붙이고 mix of all RefCOCO variants 데이터로 학습 후, SigLip 과 SigLip 2 성능 비교