(블로그 요약) Qwen2.5 VL (blog)
데이터에 관한 내용은 없음.
모델 수정 사항
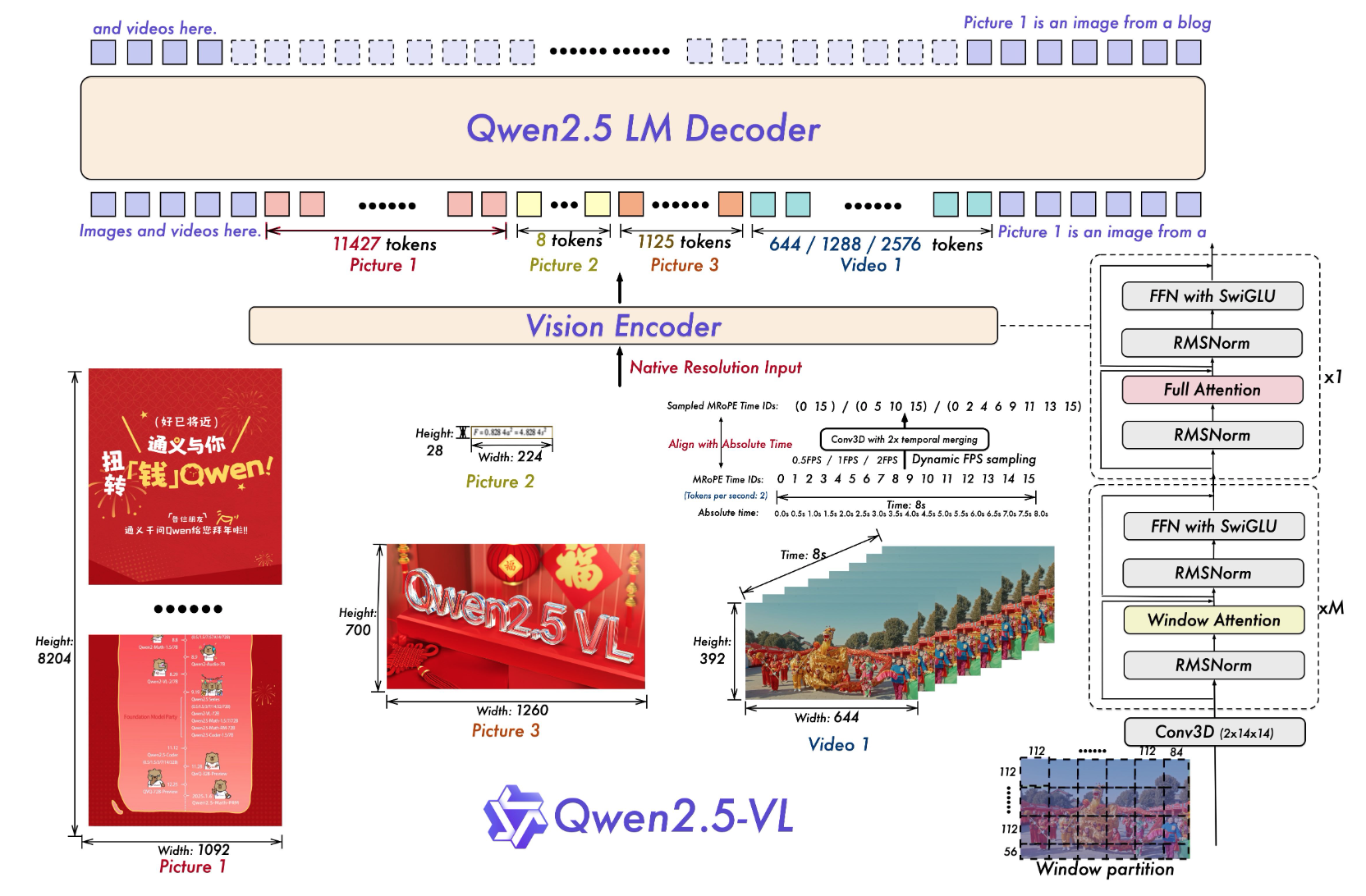
- coordinate 은 pixel 좌표 그대로 사용 (0~1 스케일 사용하지 않음).
- patch size: 28 x 28
- video 의 경우, 3D conv 사용
- ViT 를 scratch 부터 학습
- (LLM 에서 사용하는) RMSNorm, SwiGLU 사용
- (처리 속도 향상 목적) window attention 사용
- CLIP -> vision-language model alignment -> end-to-end training