(논문 요약) Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers (Paper)
핵심 내용
Heterogeneous Pre-trained Transformers (HPT): pretrain a large, shareable trunk of a policy neural network to learn a task and embodiment agnostic shared representation

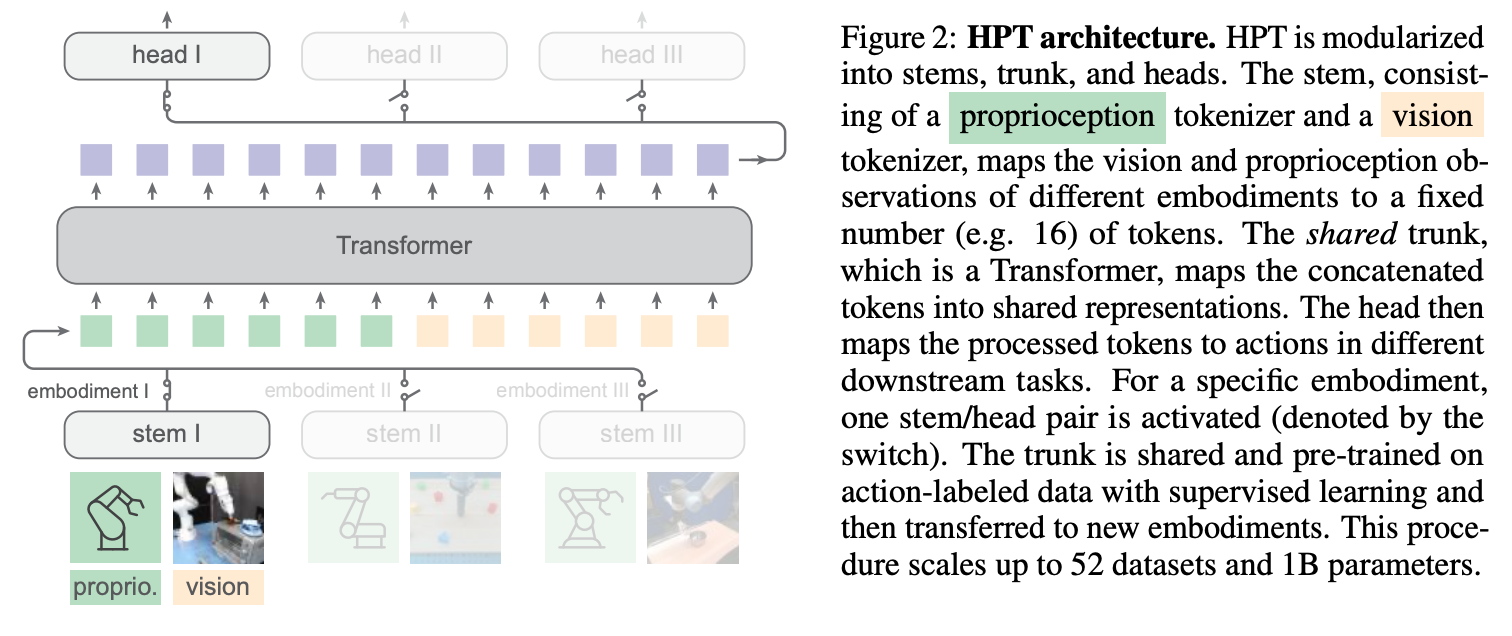
Architecture
- input: proprioception + camera inputs
- output: action tokens
- 개별 로봇팔의 input 을 step 에서, output 을 head 에서 처리
- 가운데 transformer 는 공용
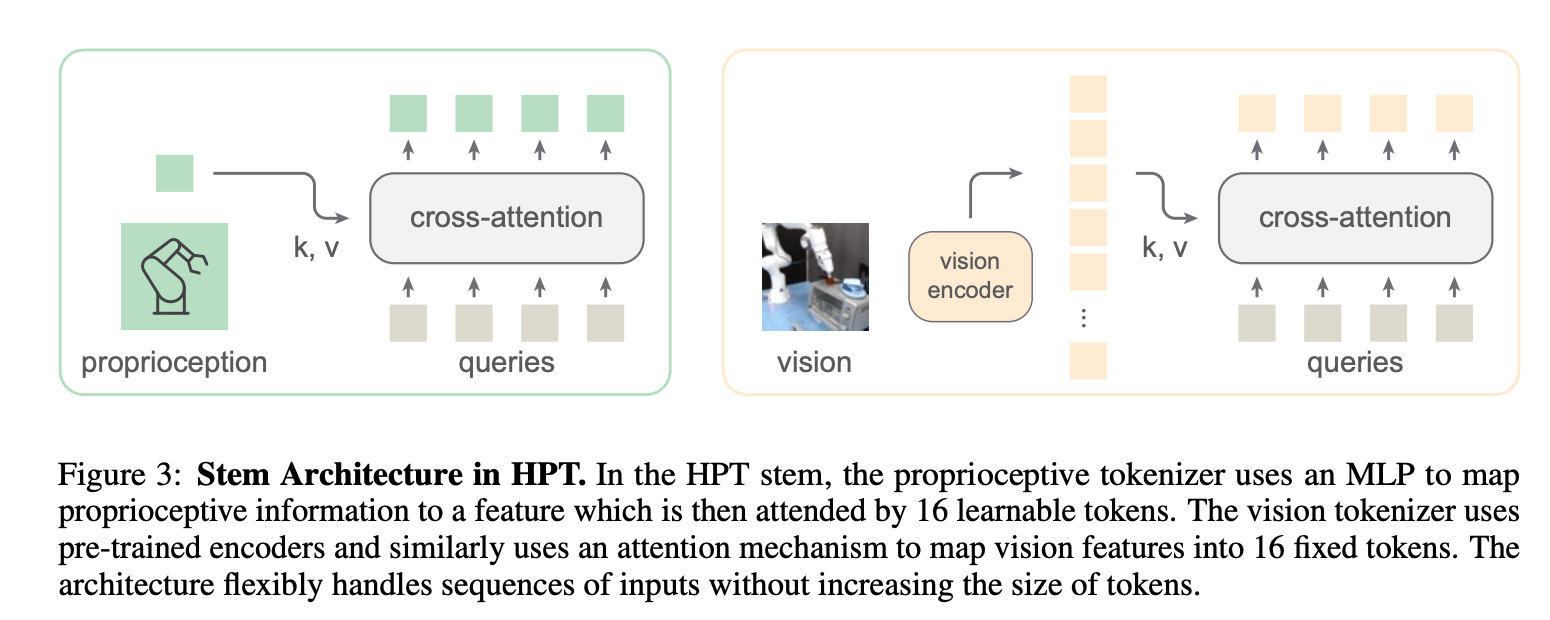
- step 에서, proprioception 는 MLP, vision 은 encoder 로 feature 만든뒤, learnable quries 로 attnetion.
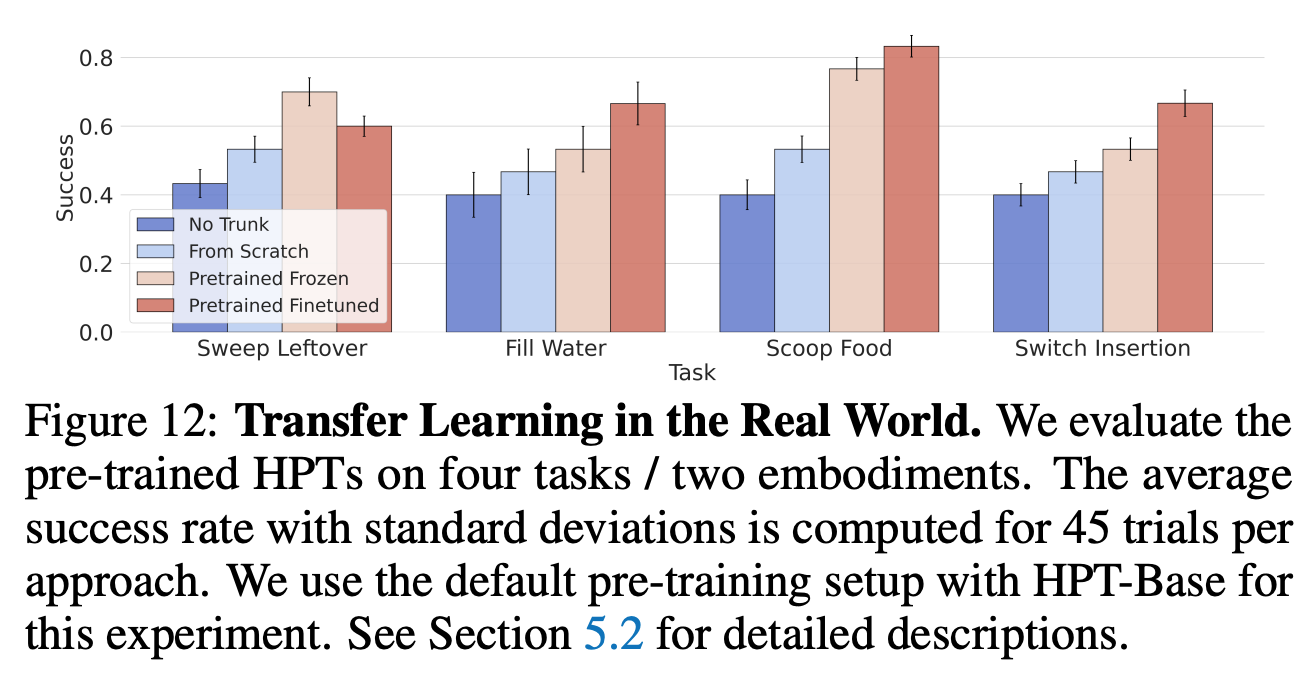
실험 결과
- pretraining 효과가 있음.