(논문 요약) Ovis: Structural Embedding Alignment for Multimodal Large Language Model (paper)
핵심 내용
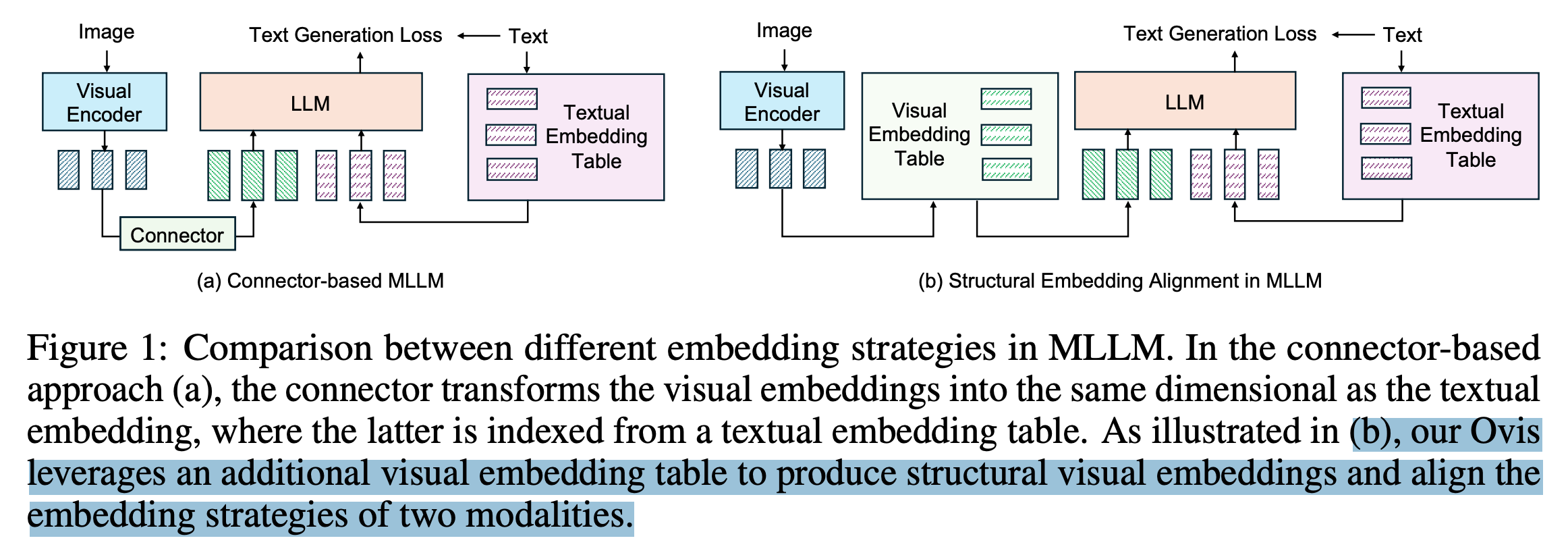
- Connector 대신, Embedding Table 을 학습시킴.
- visual encoder 에서 $f\in\mathbb{R}^K$ 생성
- text embedding 의 차원 $D$ 와 같은 차원을 갖는 $K$ 개의 기저 ($E\in\mathbb{R}^{K\times D} $)를 활용하여 projection ($v=f^T E$)
- 학습
- LLM, ViT 고정 후, COYO 와 같은 image, caption data 로 projection + embedding table 학습
- LLM 고정, ViT, projection, embedding table 를, stage 1 의 데이터와 ShareGPT4V-Pretrain 로 학습
- 전체 파라미터를 LLaVA-Finetune 과 같은 instruction-tuning 데이터로 학습
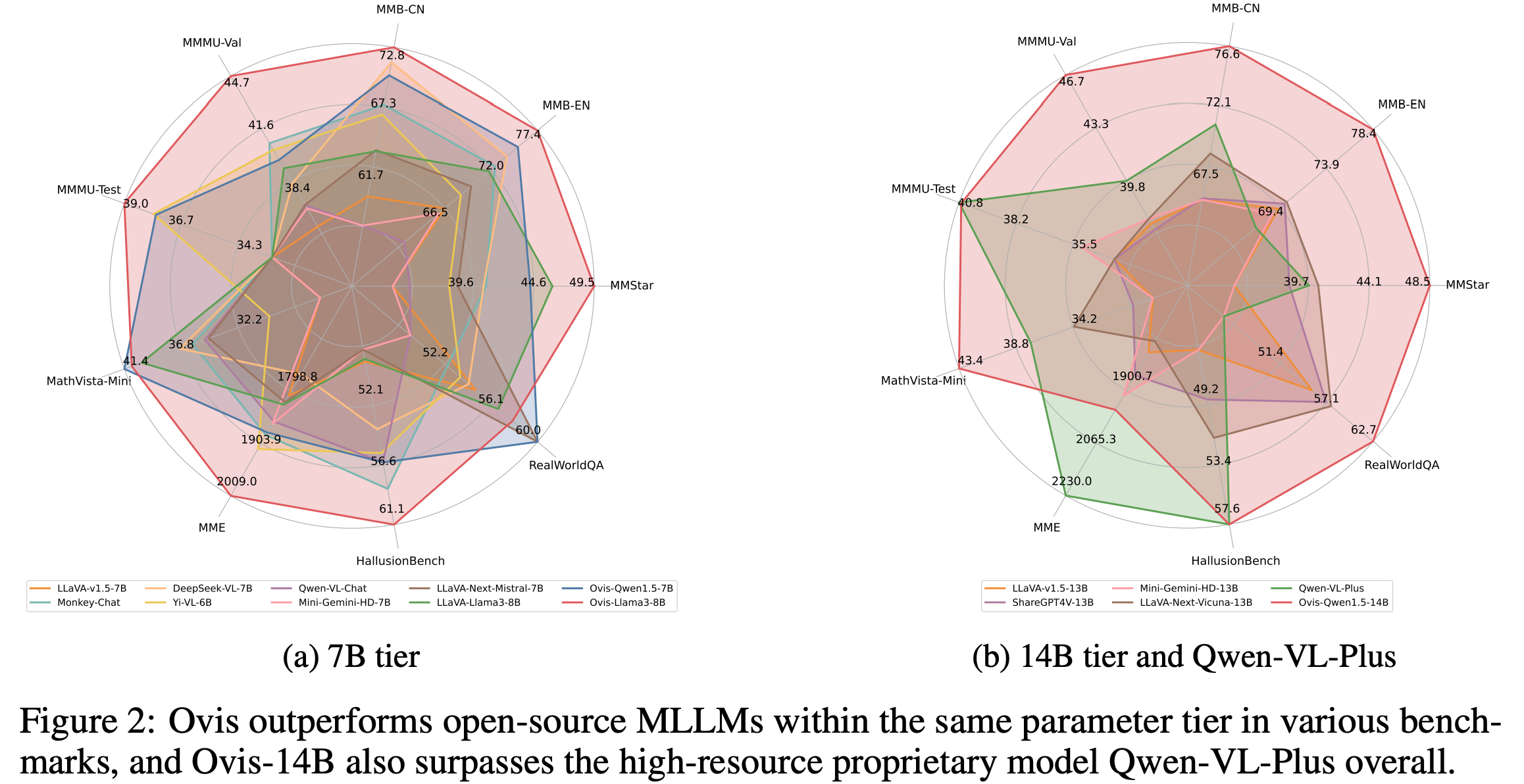
성능