(논문 요약) Mixture-of-Agents Enhances Large Language Model Capabilities (Paper)
핵심 내용
- vision-language-action 모델
- 970k real-world robot demonstrations (Open X-Embodiment dataset)
- Parameter Efficient FineTuning 으로 new task 학습
조금 움직이고 다시 조금 움직이며 동작 (데모 동영상은 배속)

- archiectue
- 600M visual encoder (SigLIP and DinoV2 - channelwise-concat)
- 2-layer MLP projector
- 7B Llama2
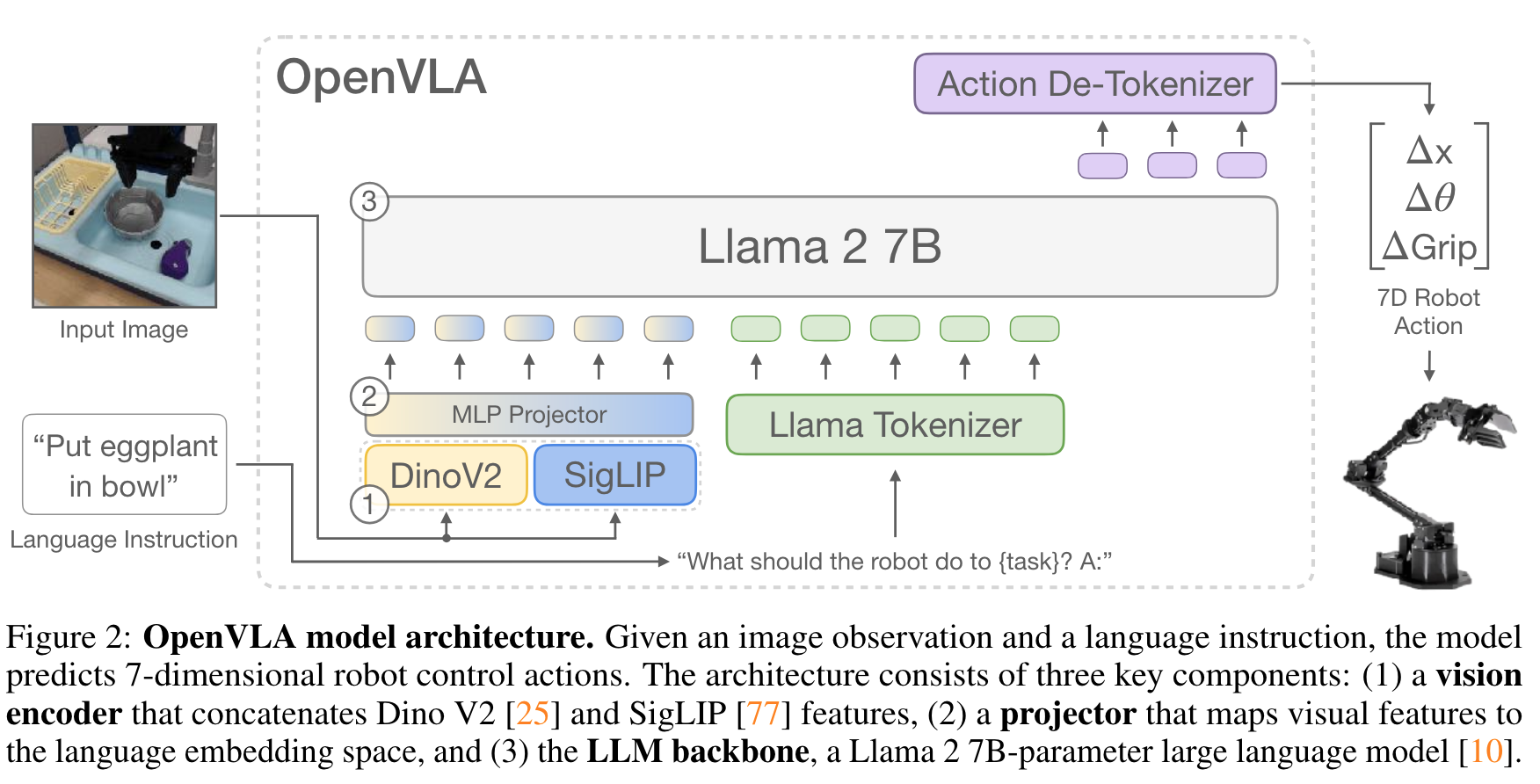
- robot action
- discretized action space (1st and 99th quantile for each variable in training data)
- data curation
- Open X dataset: >70 individual robots, >2M robot trajectories
- Open X-Embodiment dataset: 다음 기준으로 Open X 에서 샘플
- coherent input and output space across all training
- balanced mix of embodiments, tasks, and scenes
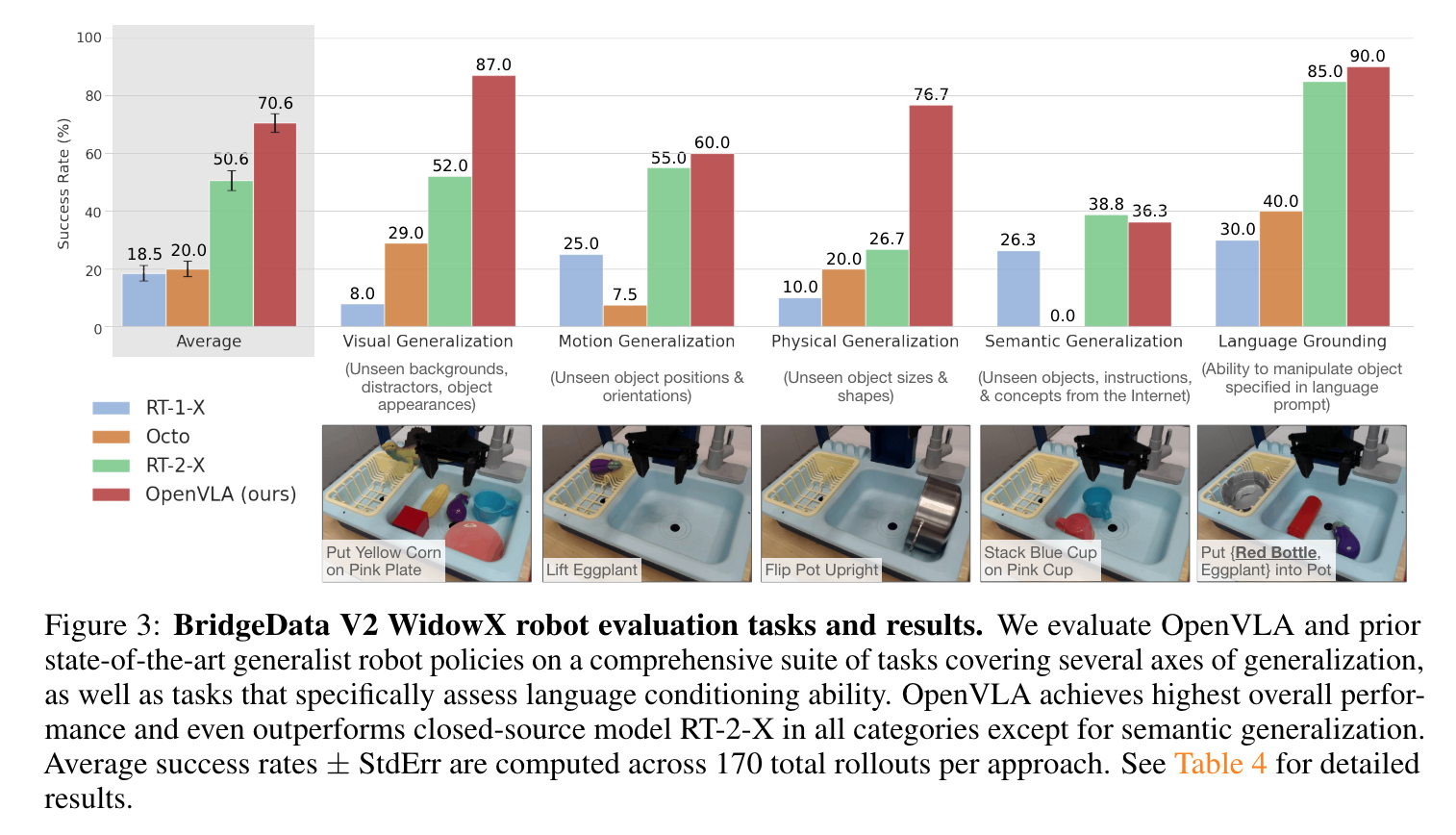
- 결과