(논문 요약) olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models (paper)
핵심 내용
PDF 의 metadata 를 prompt 에 같이 넣어서 OCR 학습.

학습 데이터
- Poppler 로 PDF -> images
- PyPDF 로 text blocks, images, positions 정보 추출
- GPT4o 에 key-value 추출 query
- 학습: Qwen2-VL-7B-Instruct 부터 SFT (H100 8개)
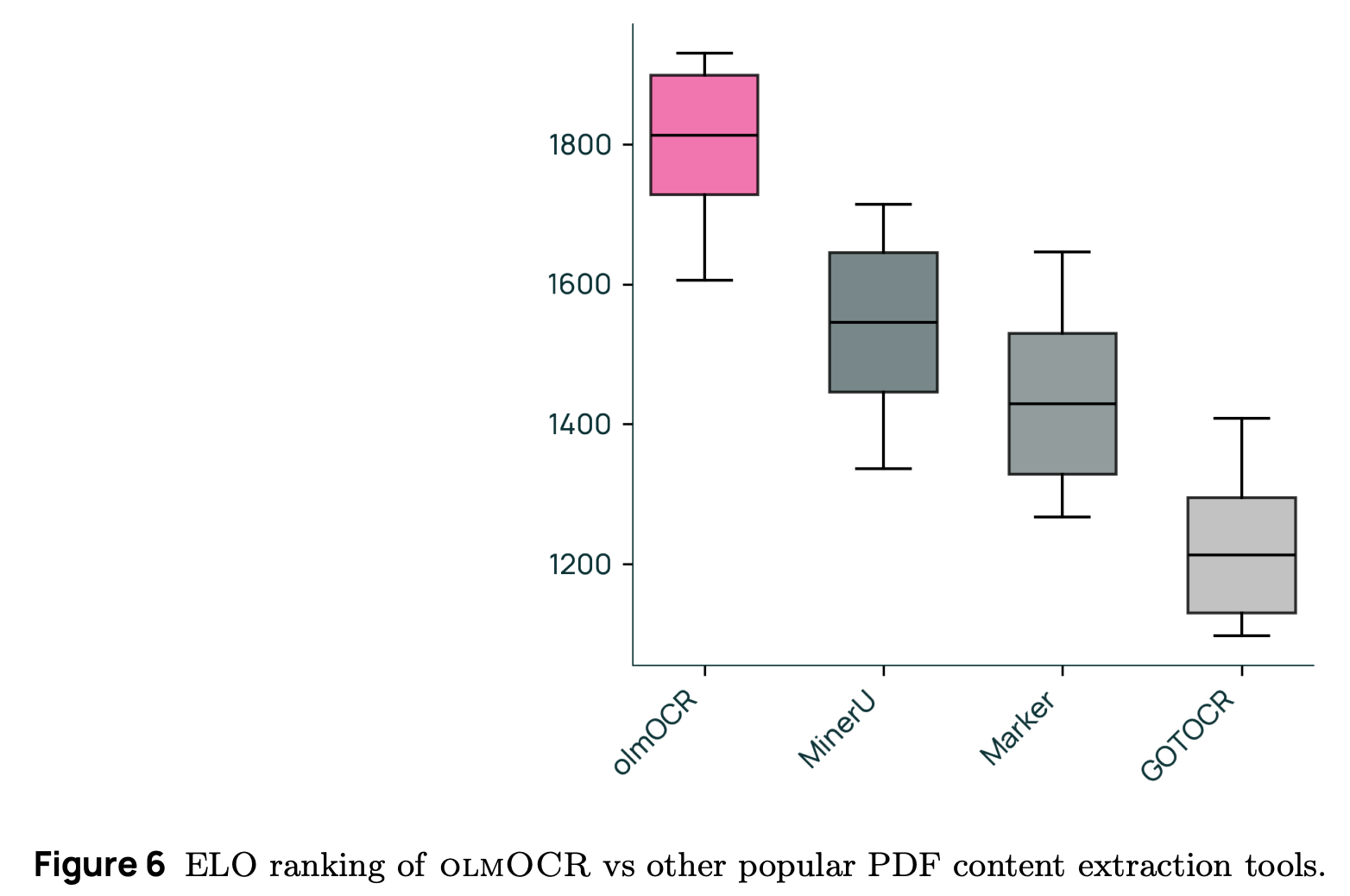
성능