(논문 요약) Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models (Paper)
핵심 내용
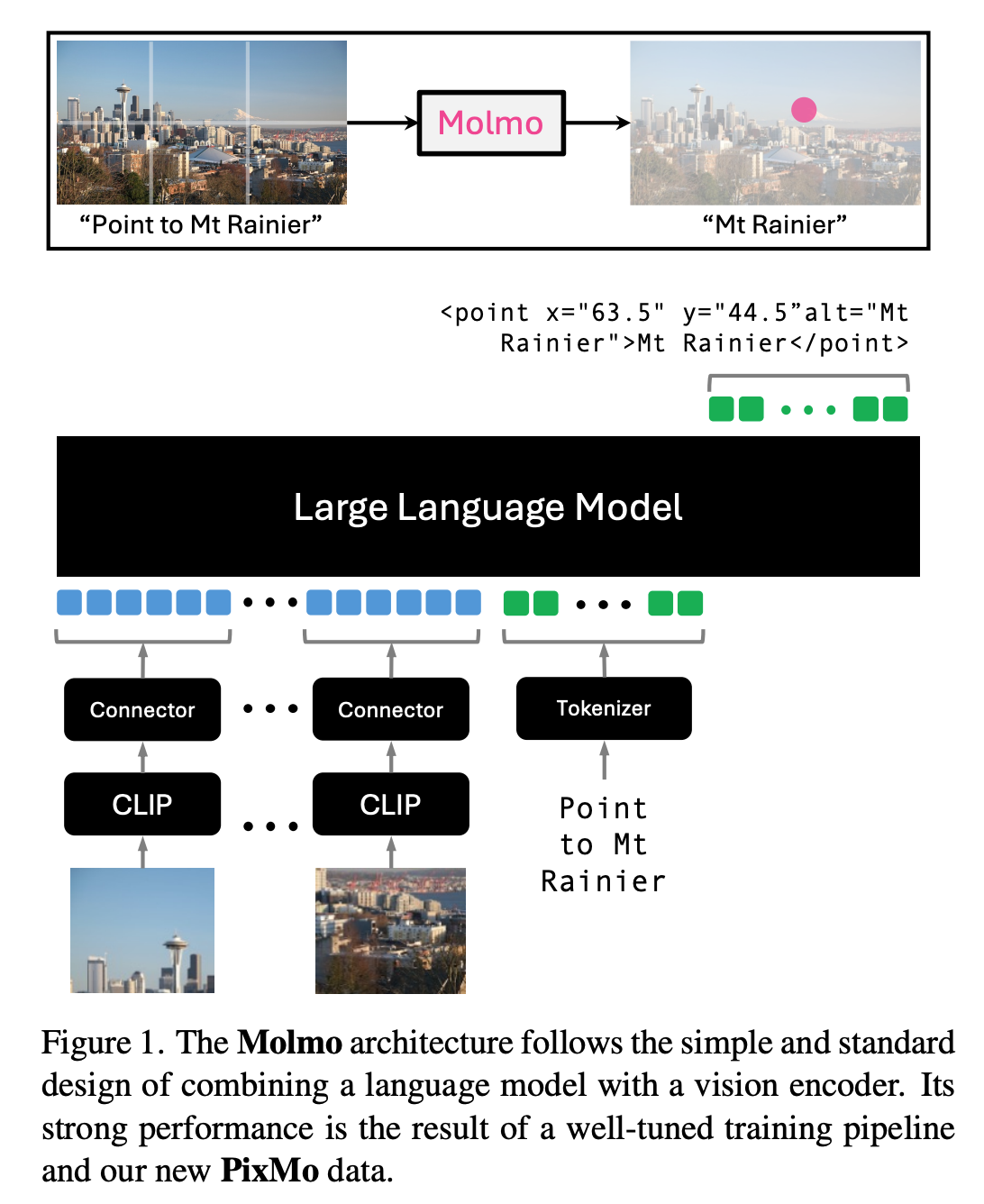
- Architecture
- input image 를 multiscale, multi-crop images 로 변환
- vision encoder: ViT-L/14 336px CLIP model
- vision -> language feature conversion: MLP and pooling
- (decoder only) LLM: OLMo-7B-1024
- Training
- Phase 1: pretraining with caption data
- ∼70 high-level topics (e.g. street signs, memes, food, drawings, websites, blurry photos)
- 712k distinct images with ~1.3M captions
- Phase 2: supervised finetuning with various datasets
- PixMo-AskModelAnything: 73k images, 162k question-answer pairs
- PixMo-Points: 428k images, 2.3M question-point pairs
- PixMo-CapQA: LLM 에 caption 을 주고 생성된 214k question-answer pairs (165k images)
- PixMo-Docs: generated code (2.3M question-answer pairs)
- PixMo-Clocks: analog clocks with question-answers (826k pairs)
- Academic datasets
- Phase 1: pretraining with caption data
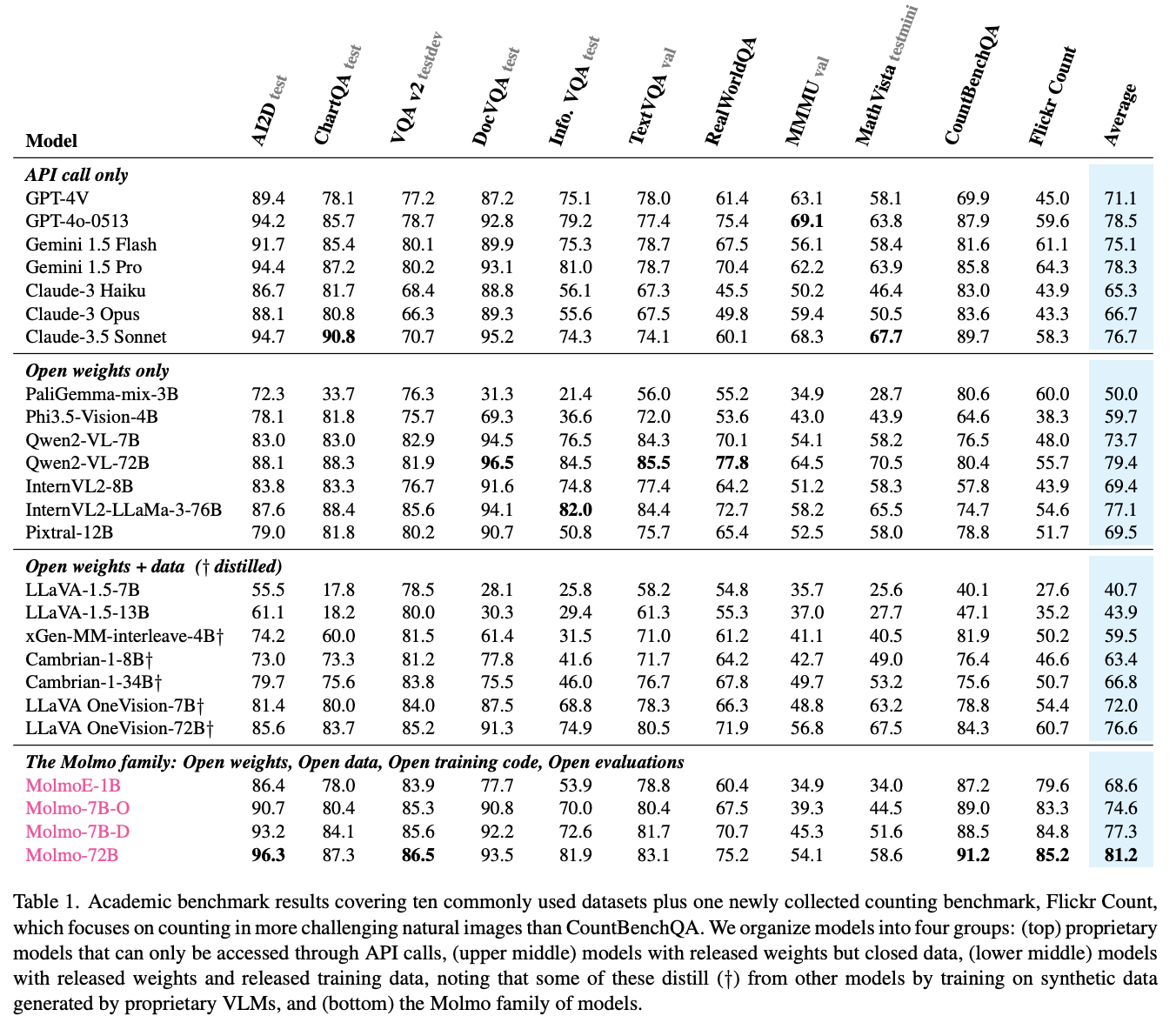
실험 결과