(논문 요약) Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation (Paper)
핵심 내용
- understanding encoder 로 SigLIP, generation encoder 로 VQ tokenizer 사용.
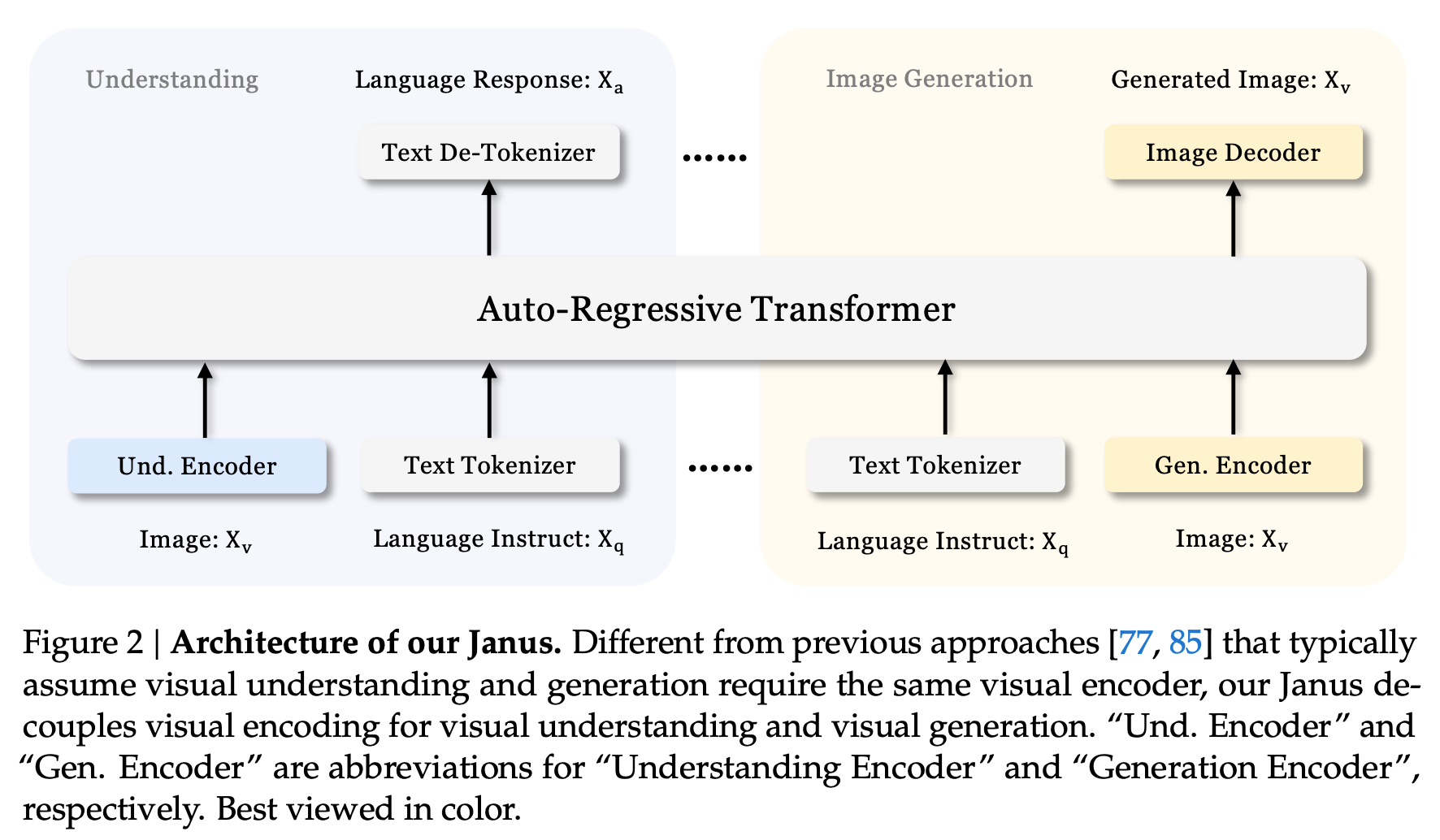
학습
- autoregressive loss
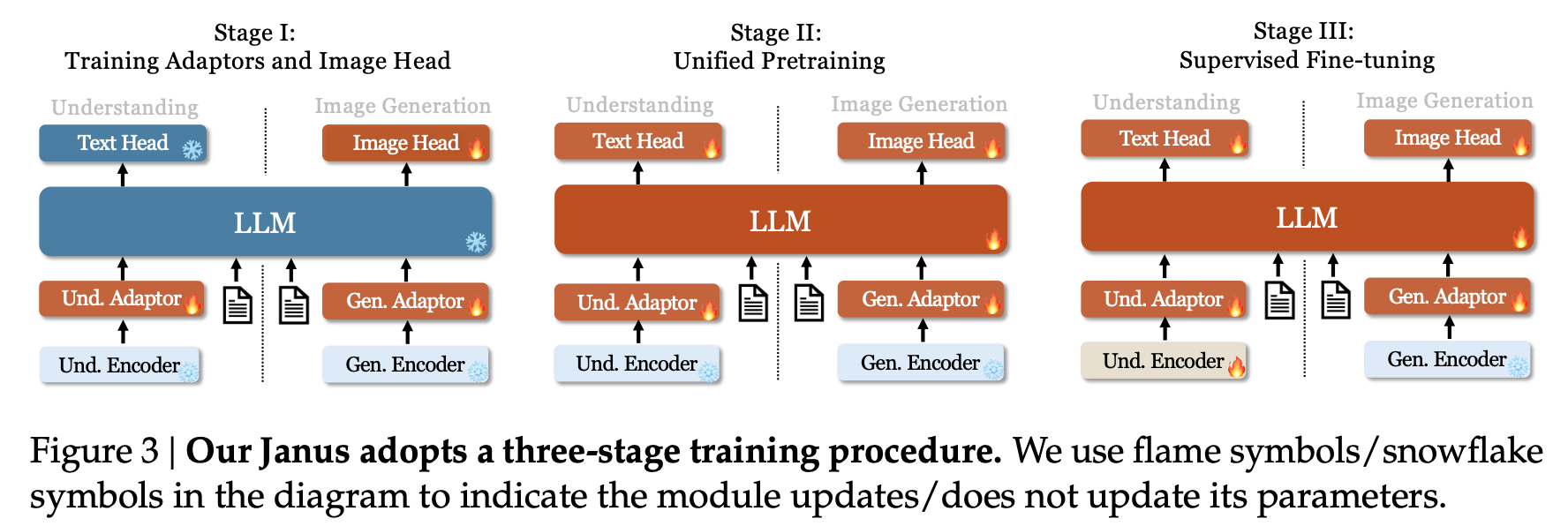
- Unified Pretraining
- Data: pure text data, multimodal understanding data, visual generation data
- 먼저, ImageNet-1k 로 simple visual generation training (inspired by Pixart paper)
- 그리고 나서, general text-to-image data 로 학습.
- Supervised Fine-tuning
- Data: pure text dialogue data, multimodal understanding data, visual generation data
실험 결과
