(논문 요약) What matters when building vision-language models? (Paper)
핵심 내용
- Vision-Language Model 에서 pre-trained models, architecture choice, data, and training methods 최적화 실험.
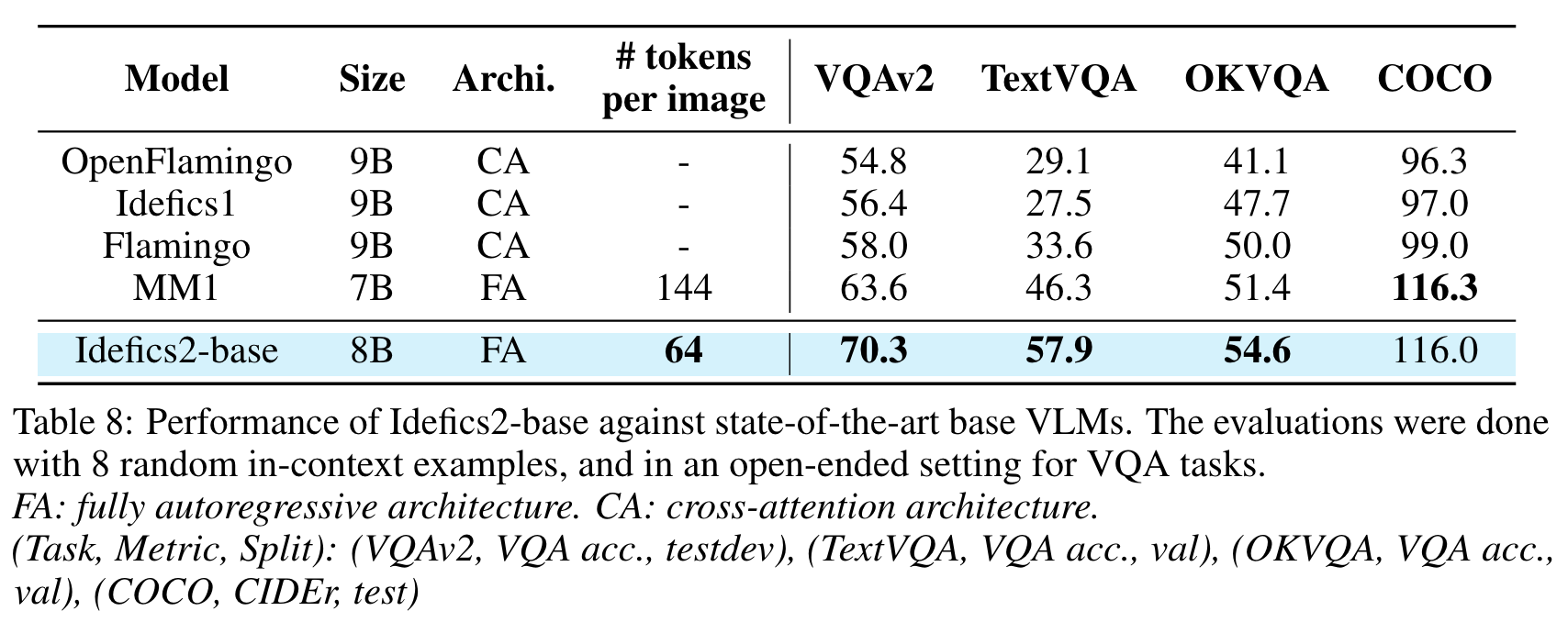
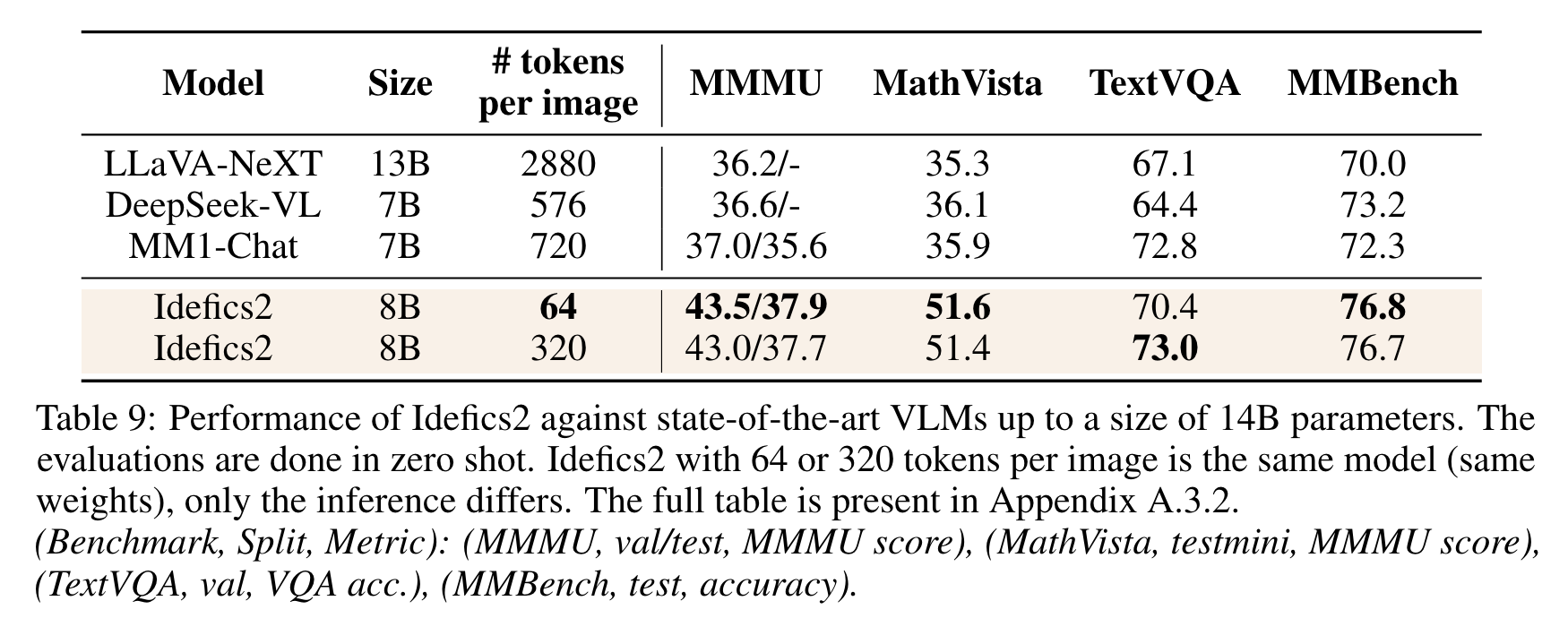
- 4개 dataset 에서의 성능 비교
- VQAv2: general visual question answering
- TextVQA: OCR abilities
- OKVQA: external knowledge
- COCO: captioning
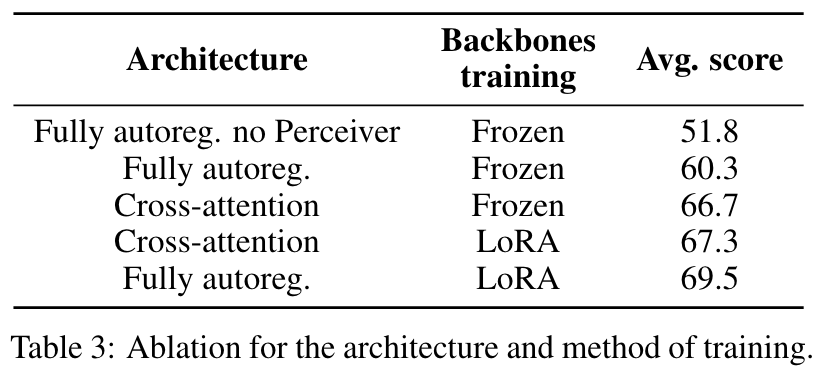
- backbone ablation
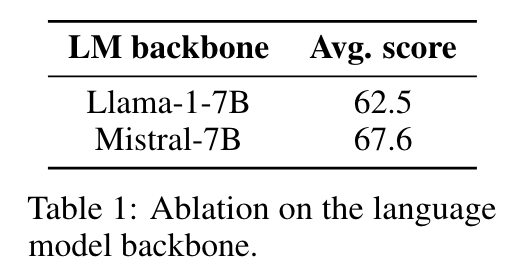
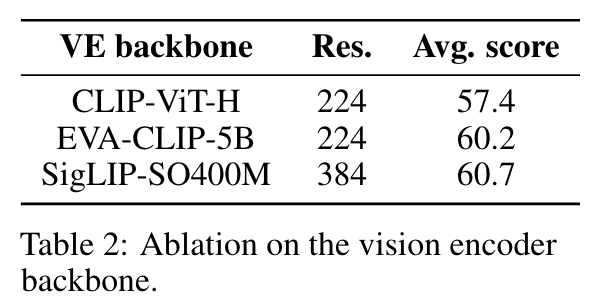
- Fully-Autoregressive, LoRA 가 가장 나음.
- visual token 많이 필요 없음.

- 이미지는 aspect ratio 유지하는 대신 정사각형이 나음.

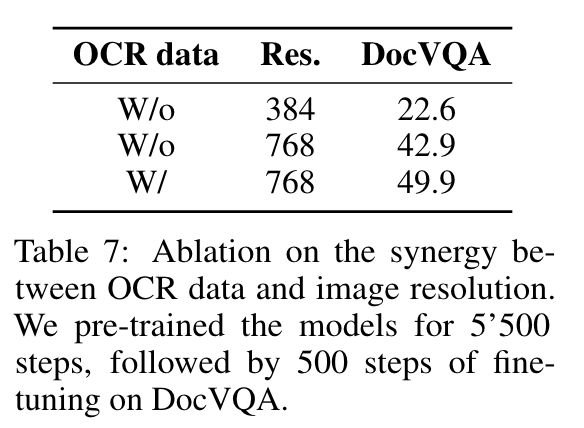
- ocr 학습해야 DocVQA 잘함.
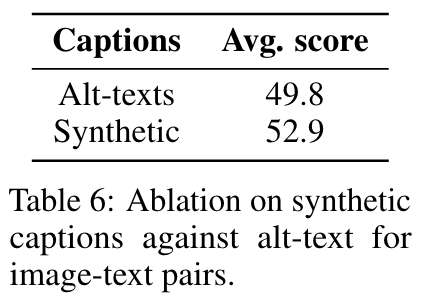
모델로 text generation 해도 데이터 추가하는게 도움됨.
- 학습
- stage 1: train on OBELICS, an open web-scale image-text documents with 350M images and 115B text (max 384-pixel image)
- stage 2: train on PDF documents (max 980-pixel image)
- lr=1e-4, 2 epochs (1.5B images + 225B text tokens)
- chat scenario 를 위해 large batch 로 a few hundred steps 학습 (LLaVA-Conv, ShareGPT4V)
실험 결과