(논문 요약) Aya Vision: Expanding the worlds AI can see (Blog)
핵심 내용
- Architecture
- 8B model: SigLIP2-patch14-384 (vision encoder) + connector + C4AI Command R7B (LLM)
- 32B model: SigLIP2-patch14-384 (vision encoder) + connector + Aya Expanse (LLM)
- Image
- input: 364x364
- patch size: 28x28
- output: 13x13
- 364x364 보다 큰 경우 aspect-ratio 고려하여 resize
- 학습 데이터 생성
- synthetic annotations
- translation and rephrasing (english -> others)
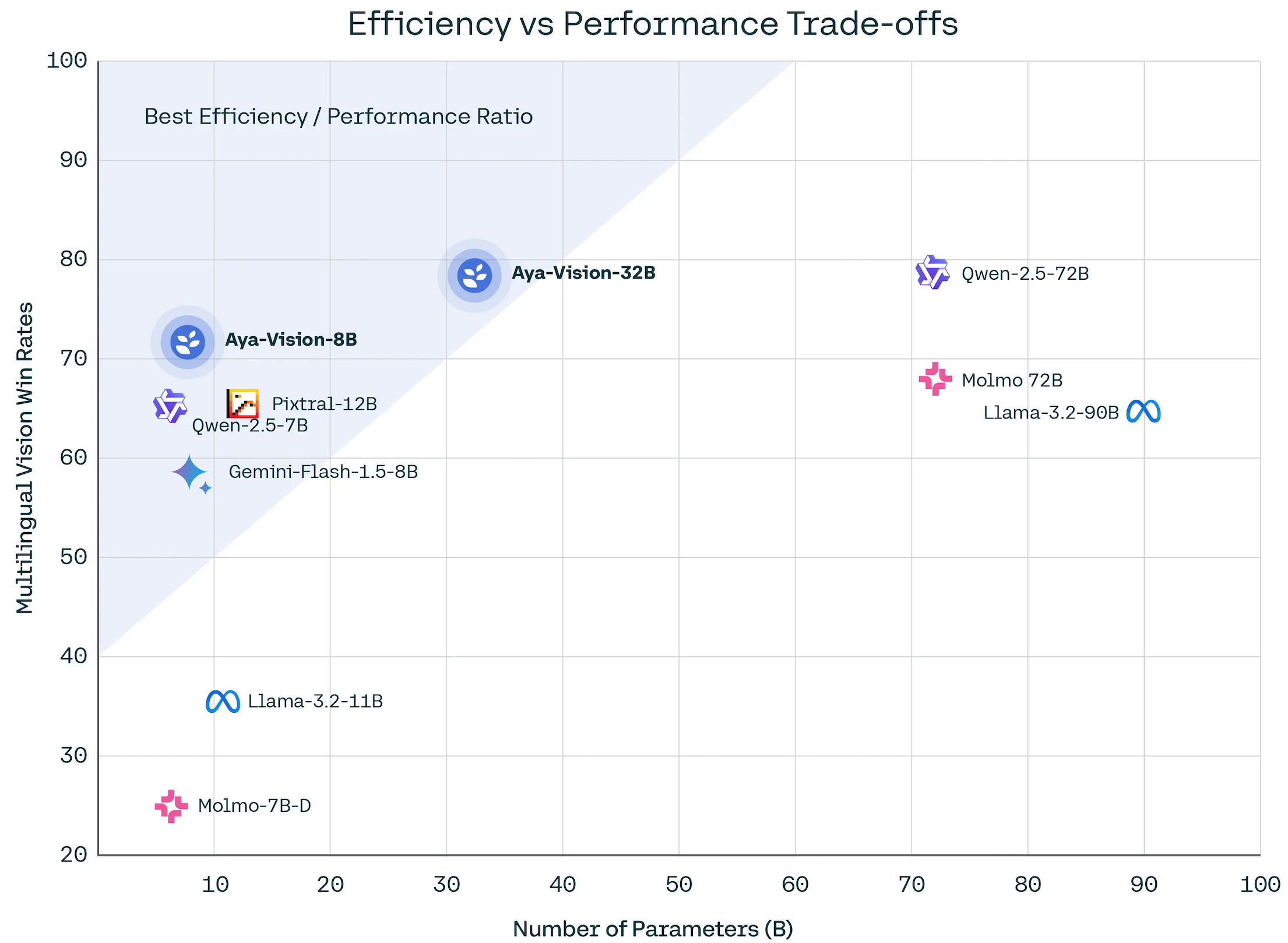
성능