(논문 요약) π0.5: a Vision-Language-Action Model with Open-World Generalization (Paper)
핵심 내용
- Vision Language Action model
- high-level subtask 생성후 action 생성 (FAST action tokenizer)
- pre-trained SigLIP (400M) + Gemma (2.6B) 활용
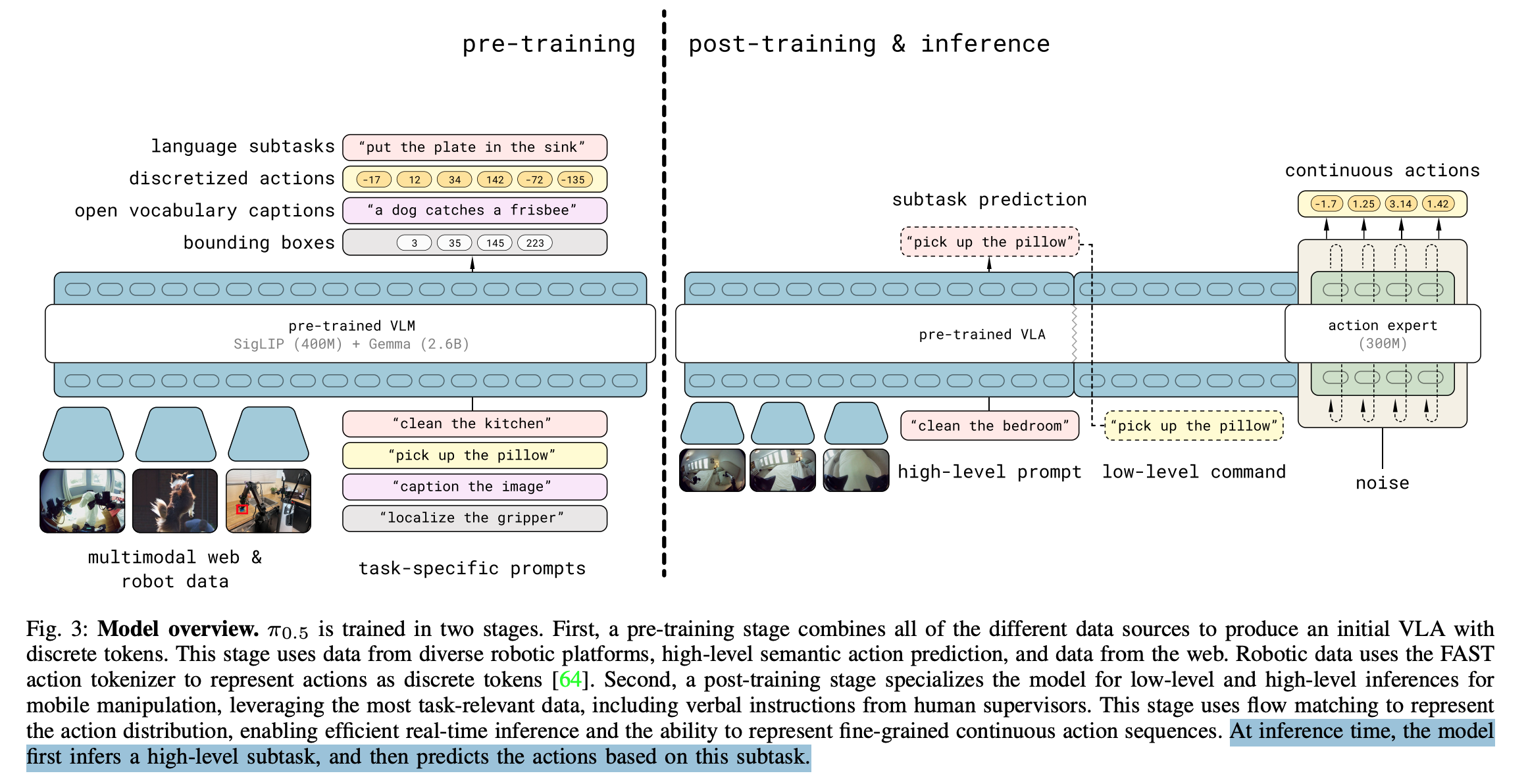
- Data
- pretrain
- Diverse Mobile Manipulator data: ~400H data of mobile manipulators performing household tasks in about 100 different home environments
- Diverse Multi-Environment non-mobile robot data
- Cross-Embodiment laboratory data
- High-Level subtask prediction
- Multi-modal Web Data (public data)
- post-train
- Diverse Mobile Manipulator data
- Diverse Multi-Environment non-mobile robot data
- pretrain
- 학습
- pretrain, post-train 시, language 는 cross entropy loss
- post-train 시, action 은 flow-matching loss
- pretrain 280k steps, post-train 80k steps