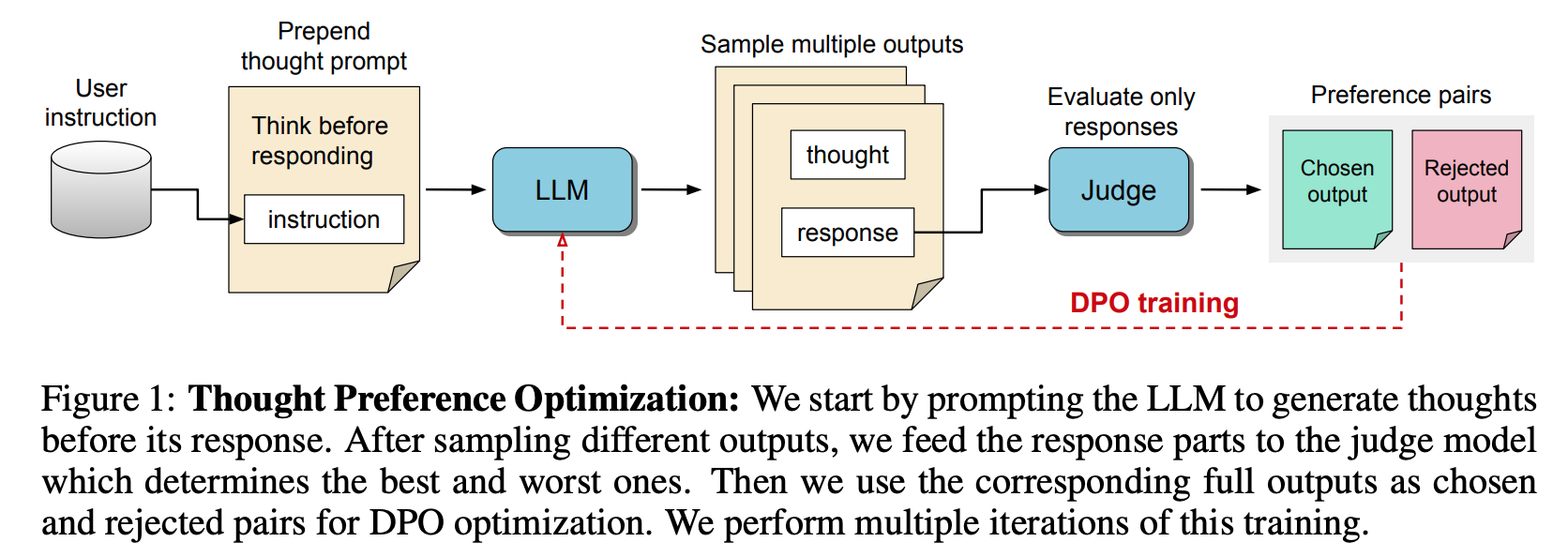
(논문 요약) THINKING LLMS: GENERAL INSTRUCTION FOLLOWING WITH THOUGHT GENERATION (paper)
핵심 내용
- fixed LLM judge 로 response 만으로 preference 를 결정.
- $K=8$ 개 output 중 가장 좋은 것과 나쁜 것을 preference data 로 활용.
- Judge: Self-Taught Evaluator (STE) and ArmoRM 사용.
실험 결과
- AlpacaEval (Length Controlled), Arena-Hard
- GPT4 (gpt-4-1106) as a judge
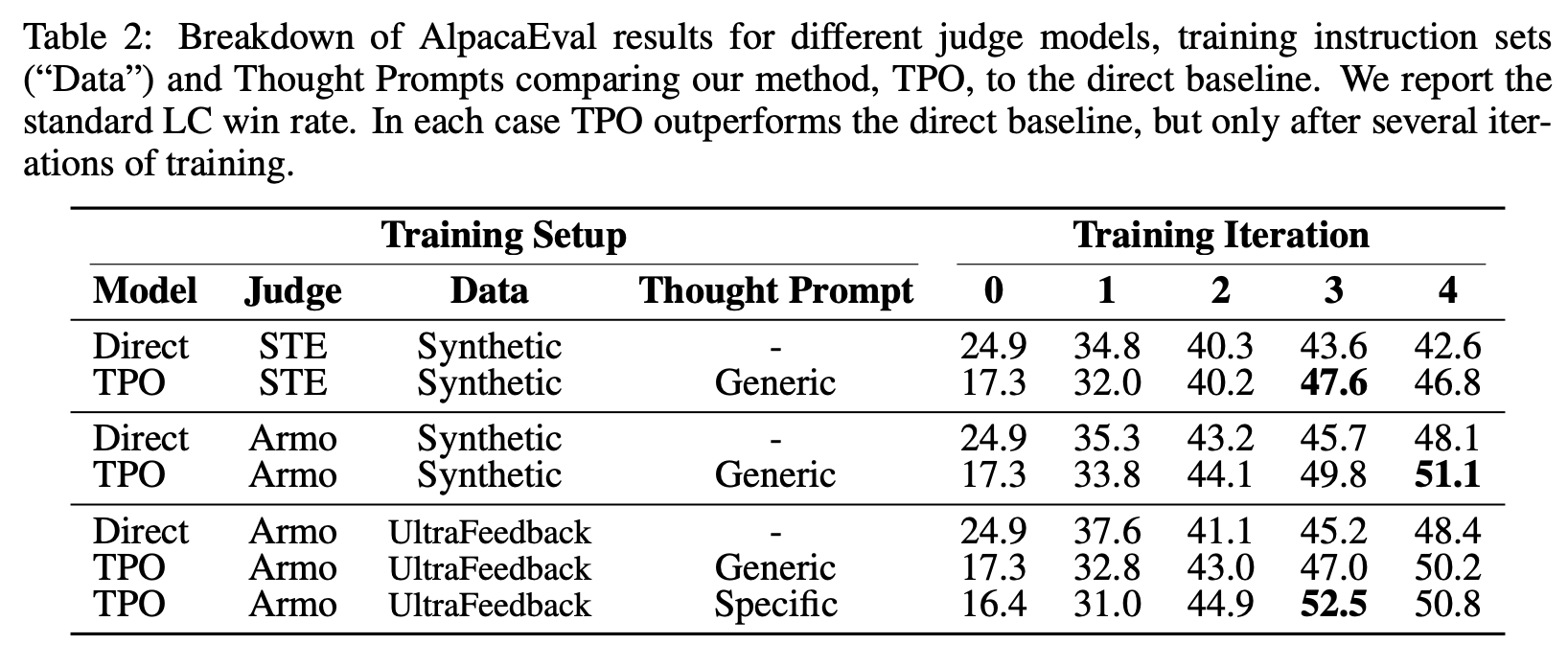
- GPT4 (gpt-4-1106) as a judge