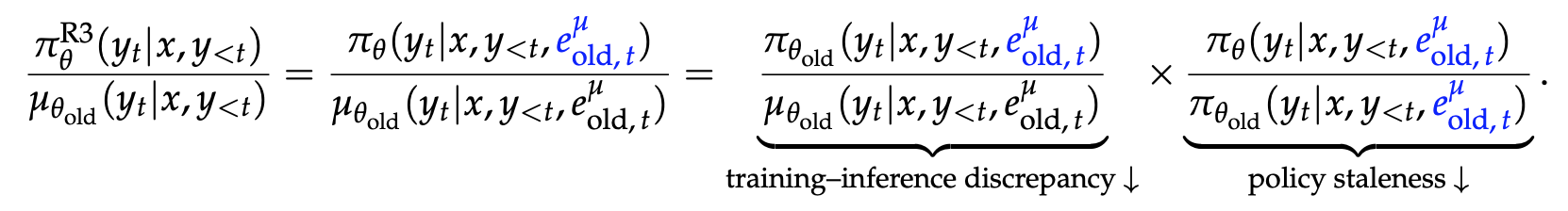(논문 요약) Stabilizing Reinforcement Learning with LLMs: Formulation and Practices (paper)
핵심 내용
- first-order approximation to the sequence-level
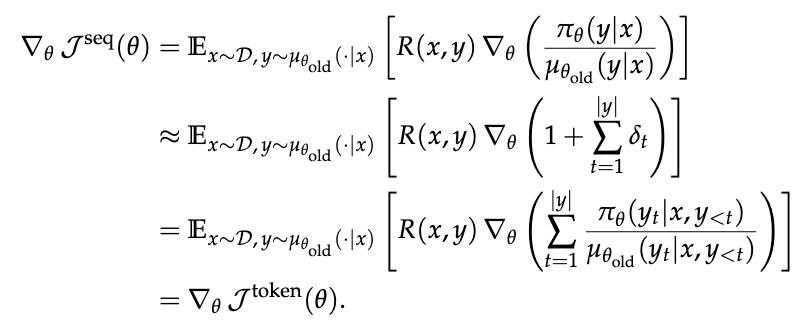
- training 과 inference 시 experts routing 이 다름.
- precisions (e.g., BF16 vs FP8)
- batch-dependent ops
- 작은 차이가 top-k expert choice 를 다르게 할수 있음.
Vanilla Routing Replay (R2)
- old training engine 의 experts routing 을 사용.
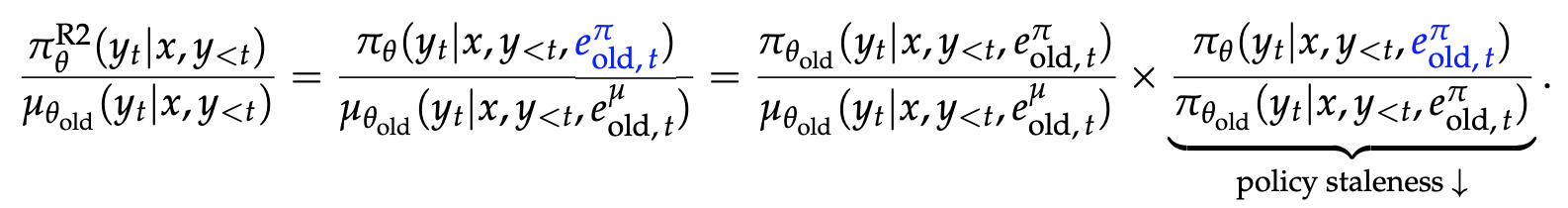
Rollout Routing Replay (R3)
- old inference engine 의 experts routing 을 사용.