(논문 요약) Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling (Paper)
핵심 내용 및 실험 결과
- weaker but cheaper 모델로 reasoning 데이터 생성시,
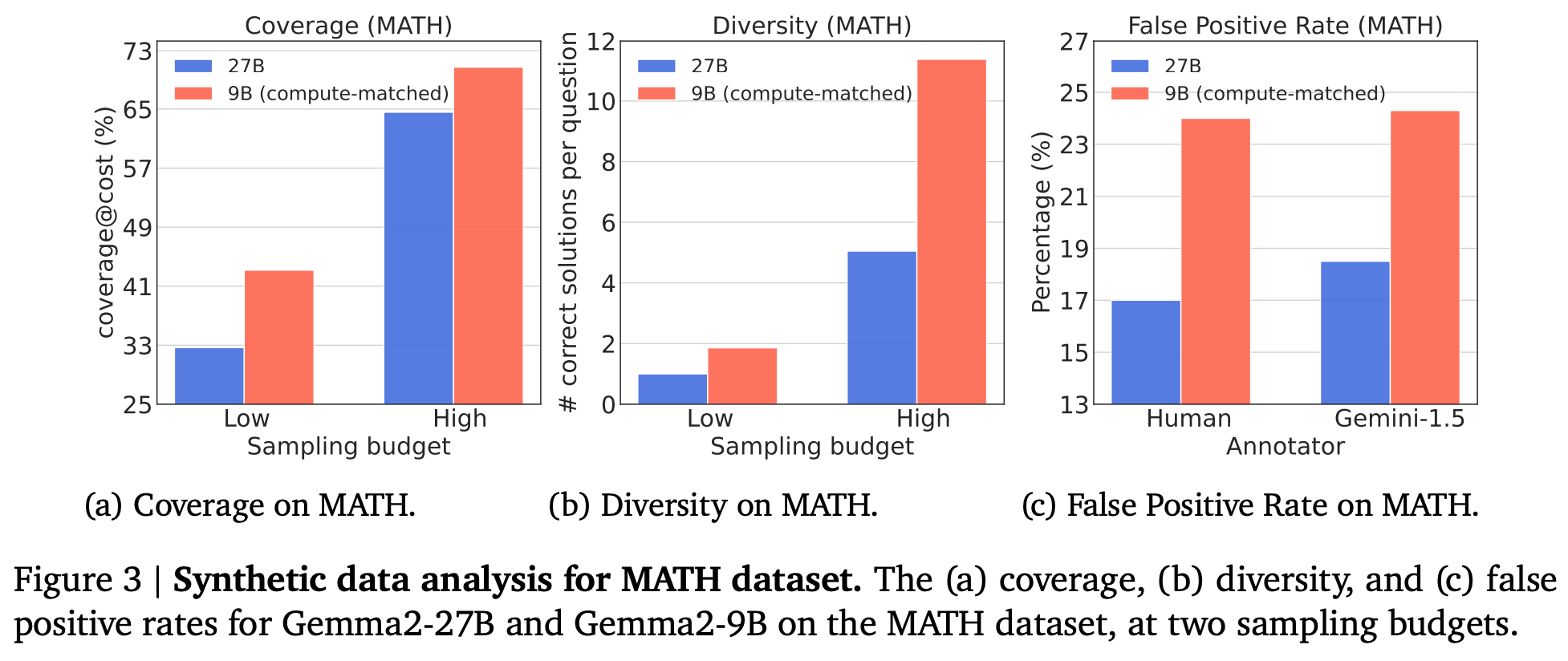
- higher coverage ($M$개 outputs 생성시, $k$개 골랐을때 정답을 포함할 확률)
- higher diversity (average # of unique correct solutions with $k$ outputs)
- higher false positive rates (incorrect reasoning even with correct answers)
- 더 싸게 모델 학습 가능
- test 데이터: MATH, GSM-8K
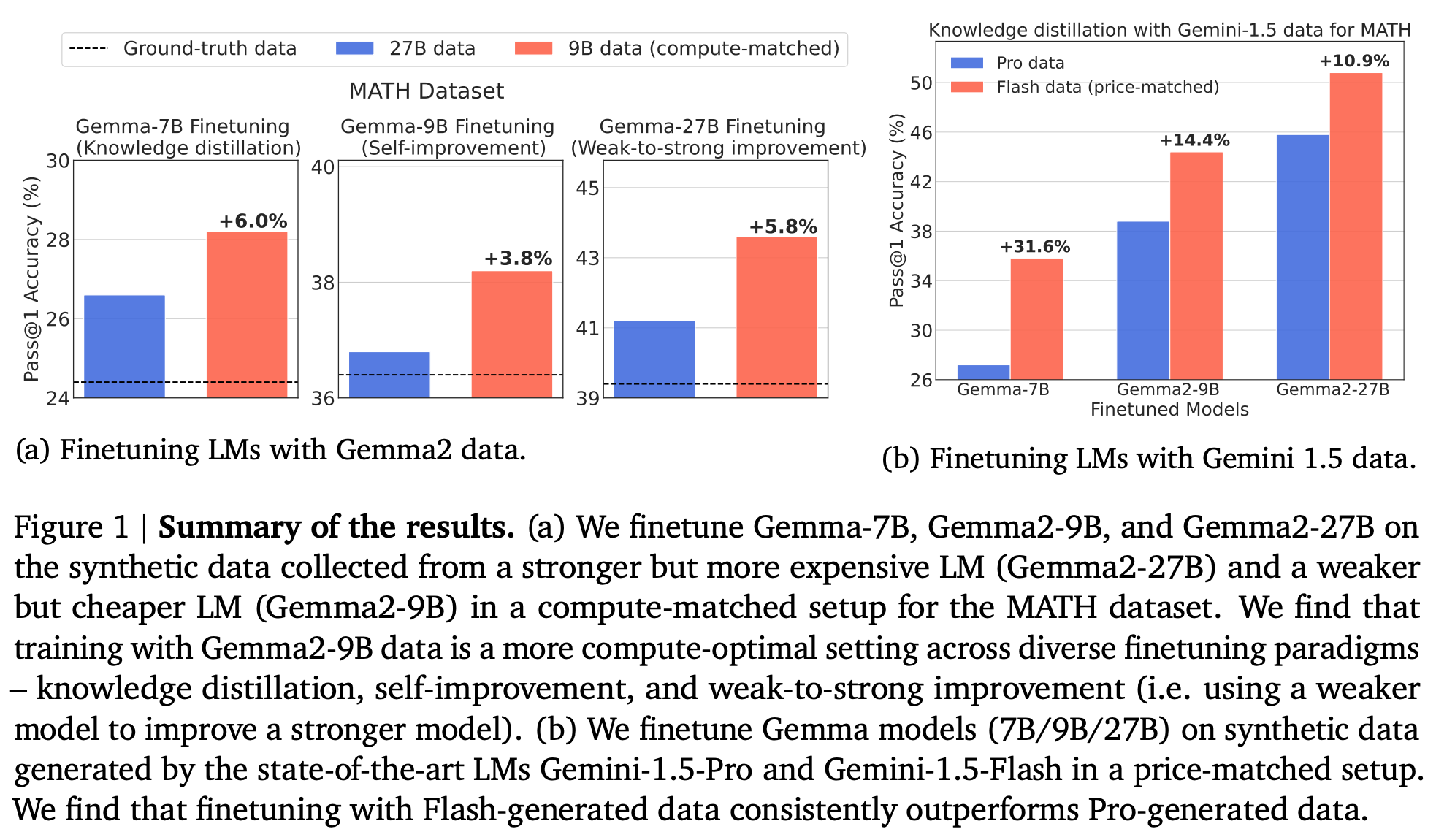
generated outputs 비교
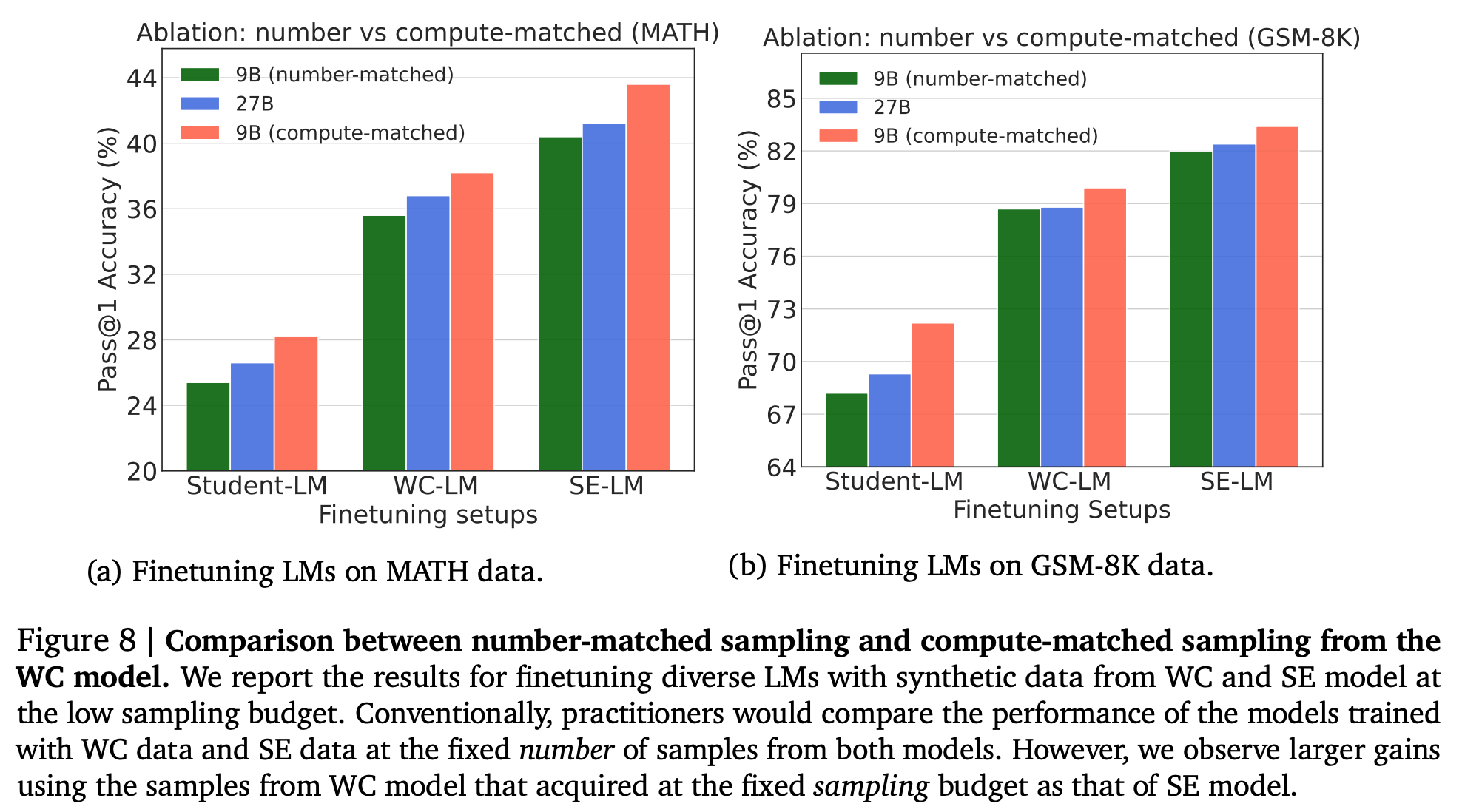
weaker but cheaper 모델로 같은 개수를 뽑아서 학습하면 성능은 낮음
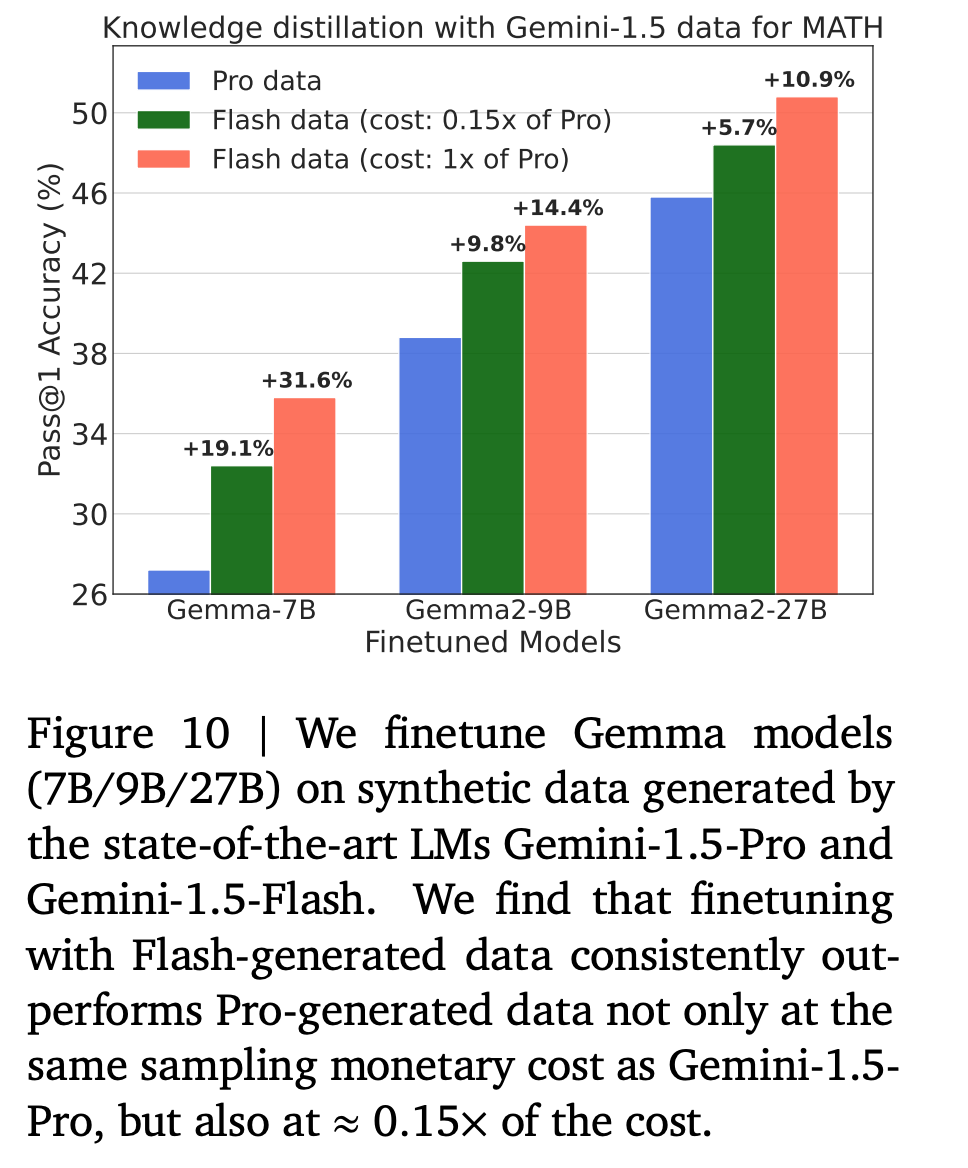
SOTA (Gemini-1.5-Pro, Gemini-1.5-Flash) 로 데이터 생성