(논문 요약) SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training (Paper)
핵심 내용
- 2개 benchmark 에서 실험.
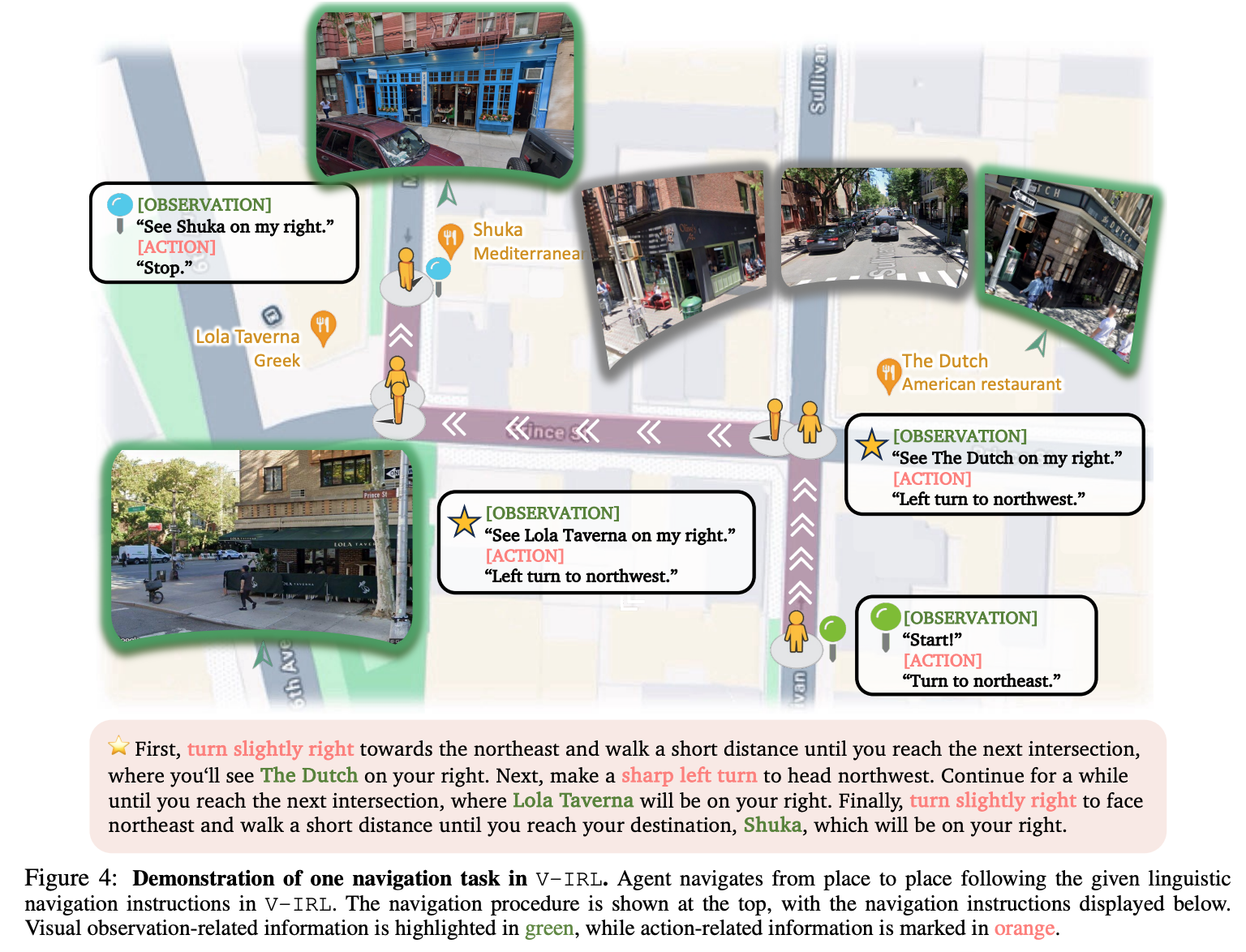
GeneralPoints: arithmetic reasoning card game
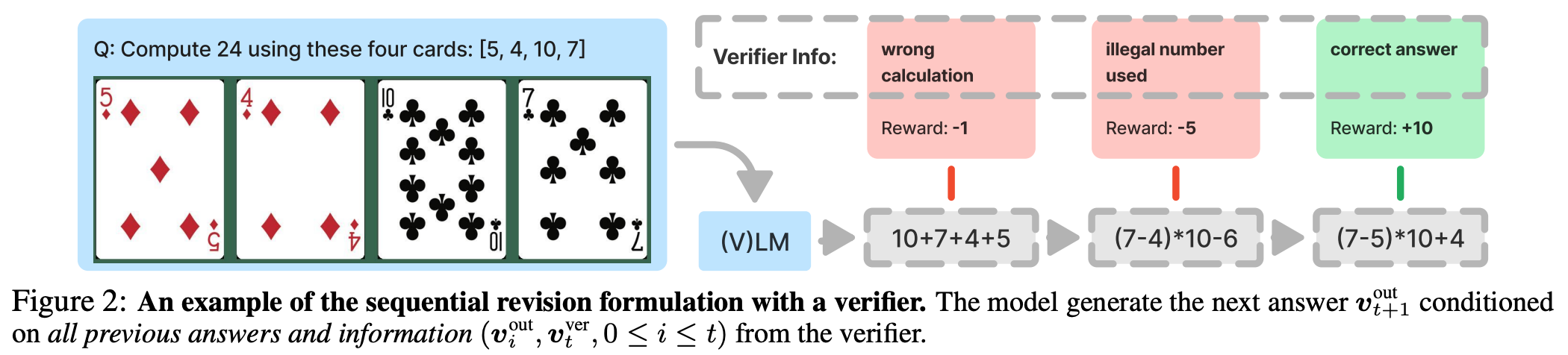
V-IRL: real-world navigation environment
- RL 이 SFT 보다 Out-of-Distribution 에서 성능이 좋음.
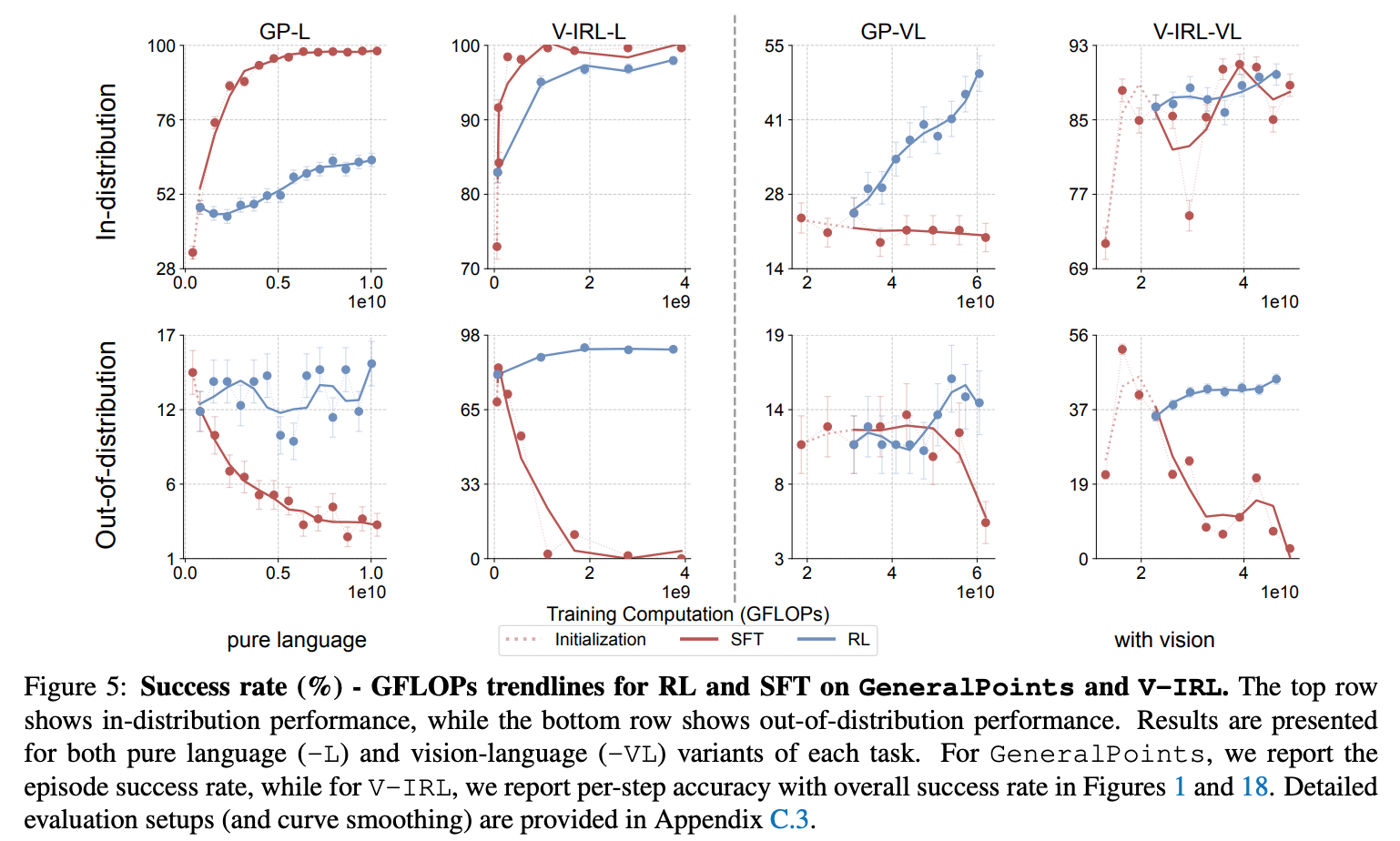
- RL (PPO) especially when trained with an outcome-based reward, generalizes in both the rule-based textual and visual environments.
- SFT, in contrast, tends to memorize the training data and struggles to generalize out-of-distribution in either scenario.
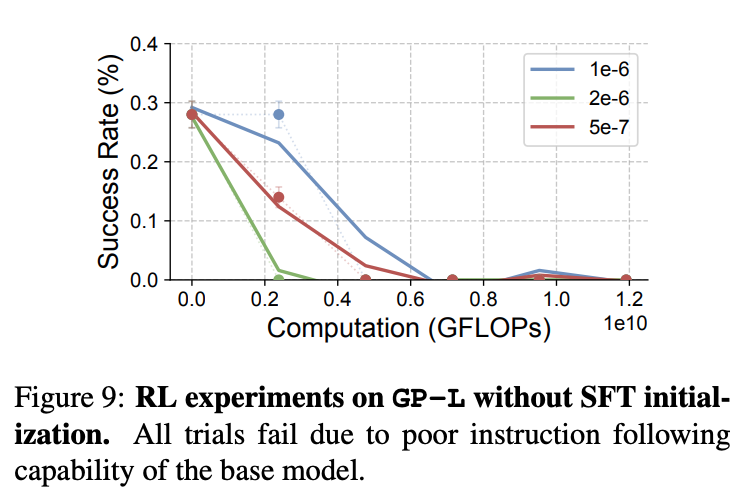
- SFT 로 학습해서 instruction following 하는 모델을 RL 돌려야 효과가 있음.