(논문 요약) Training Language Models to Self-Correct via Reinforcement Learning (Paper)
핵심 내용
첫번째 response 에 대해서, 이를 수정하여 2번째 response 생성
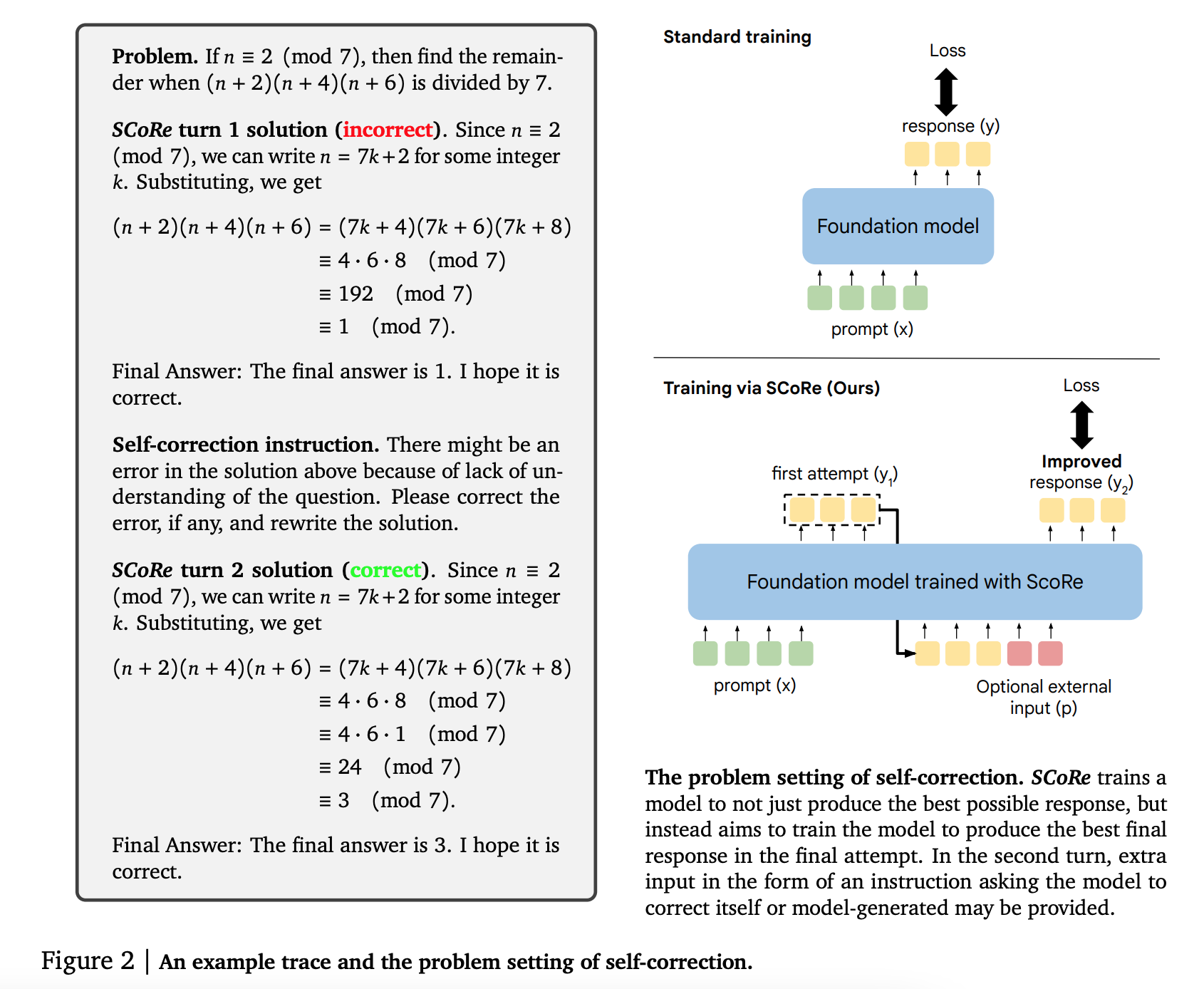
학습
- reward: 논문에서 자세히 안나오고, 예시로 string-matching based answer checking function 같은 oracle reward 가 존재한다고 가정.
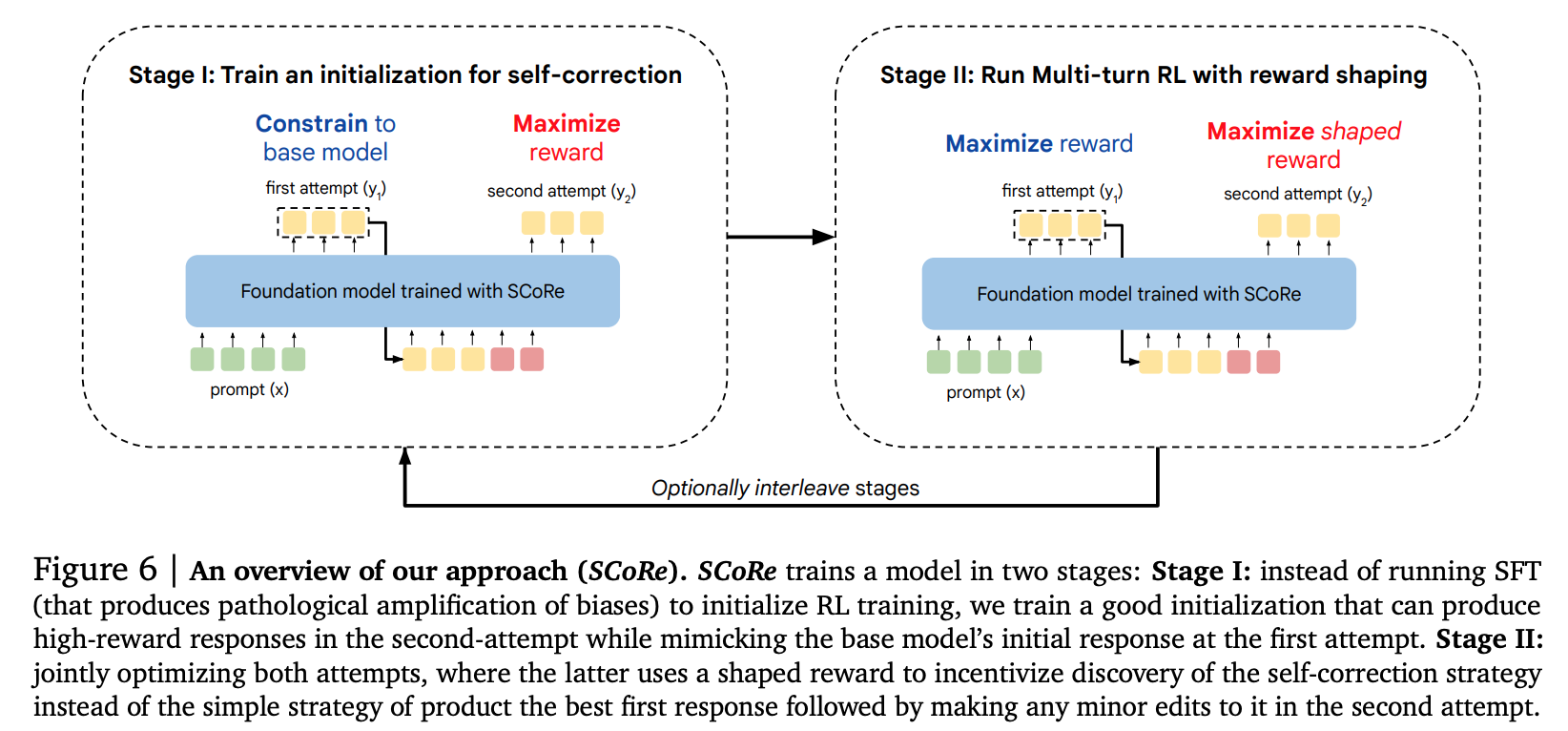
- stage 1:
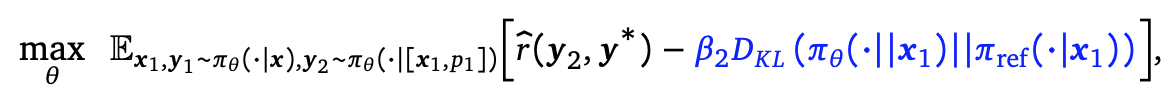
- stage 2:
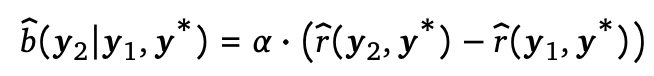
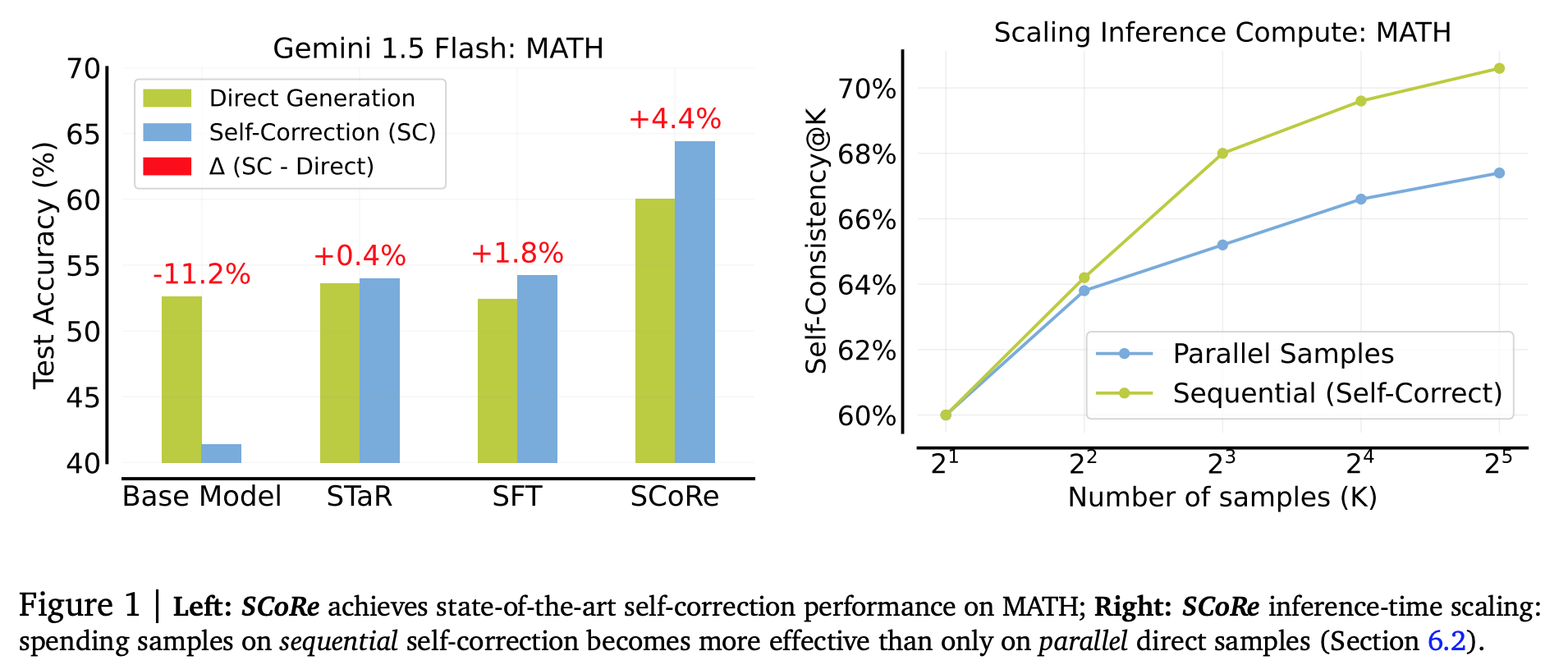
실험 결과