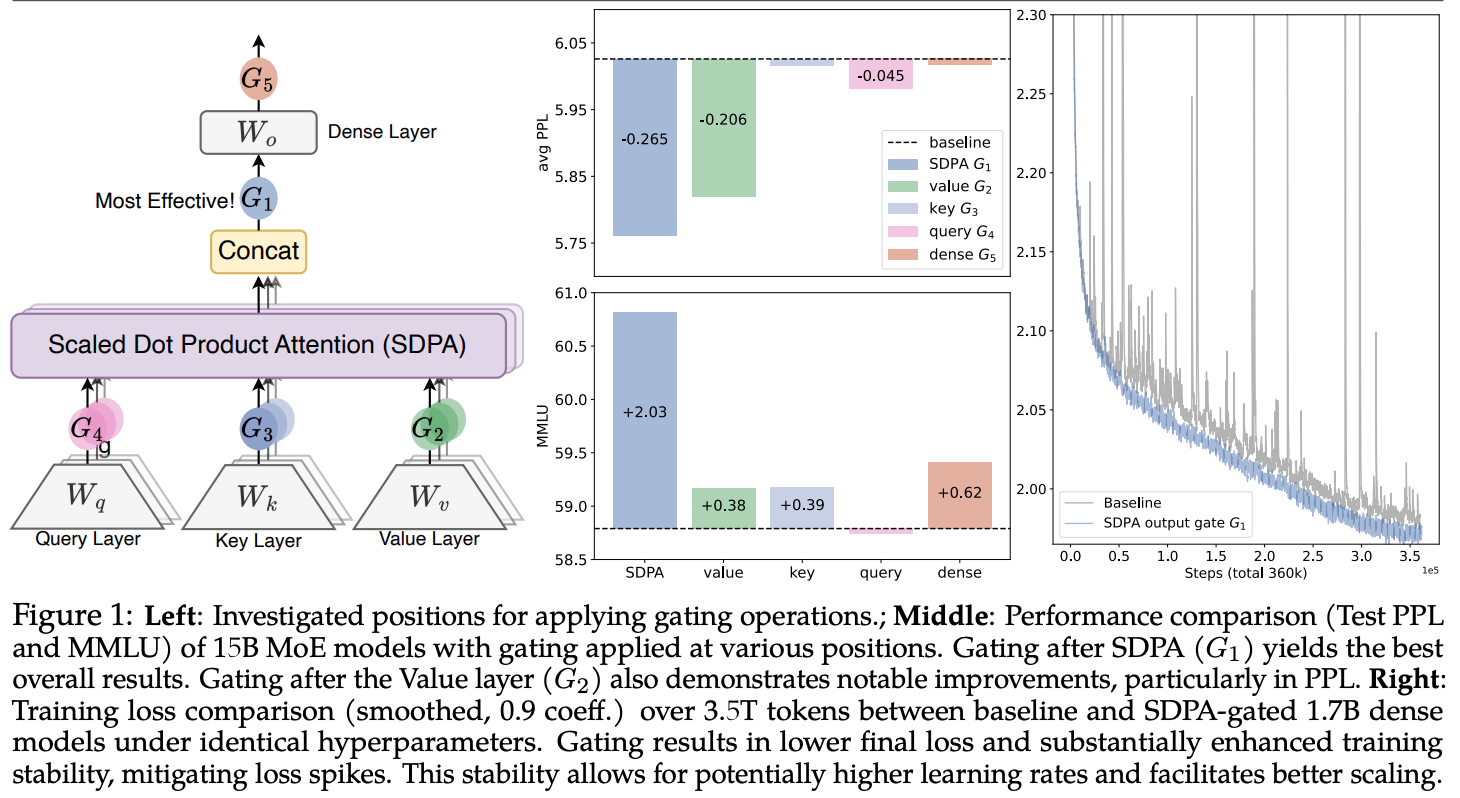
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free(paper)
- head 의 output 에 query-dependent sparse gating sigmoid 추가
- $Y’=Y\odot \sigma(XW_{\theta})$
- $X$: hidden states after pre-normalization
- $Y$: output
- elementwise
- headwise
- $Y’=Y\odot \sigma(XW_{\theta})$
- 효과
- attention sink (excess attention on the first token) 를 줄임
- loss spikes 를 줄임