(논문 요약) Compute Optimal Scaling of Skills: Knowledge vs Reasoning (Paper)
실험 세팅
데이터 구분
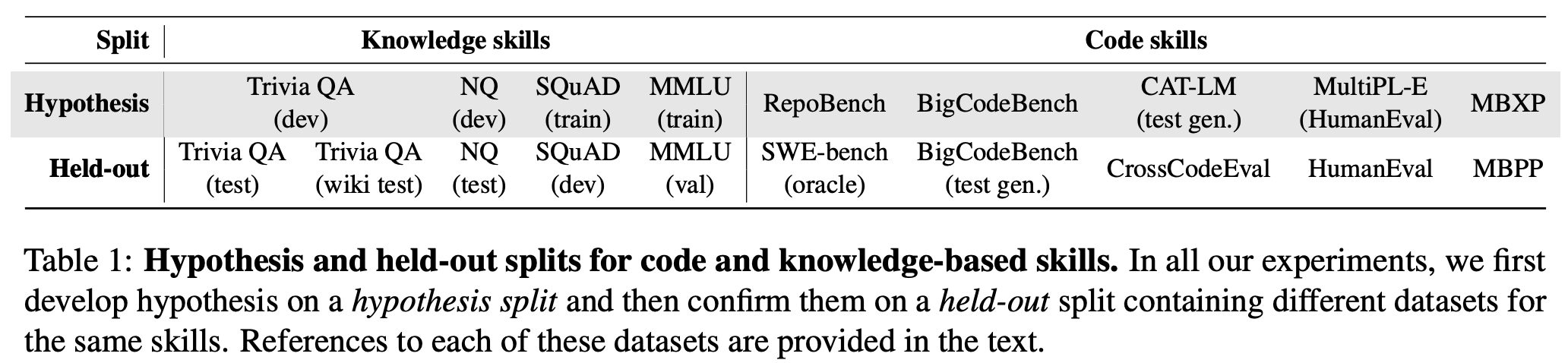
Isoflop curves: 같은 계산량 (FLOP) 에서 model size 와 data size 를 변화시키면서 loss 측정 후
- FLOPS $\approx$ 6 $\times$ model size $\times$ data size (fixed updates)
- train set 혹은 hold-out set 의 loss
- 최적값을 2차 함수 근사 후 찾음
Isoflop curves
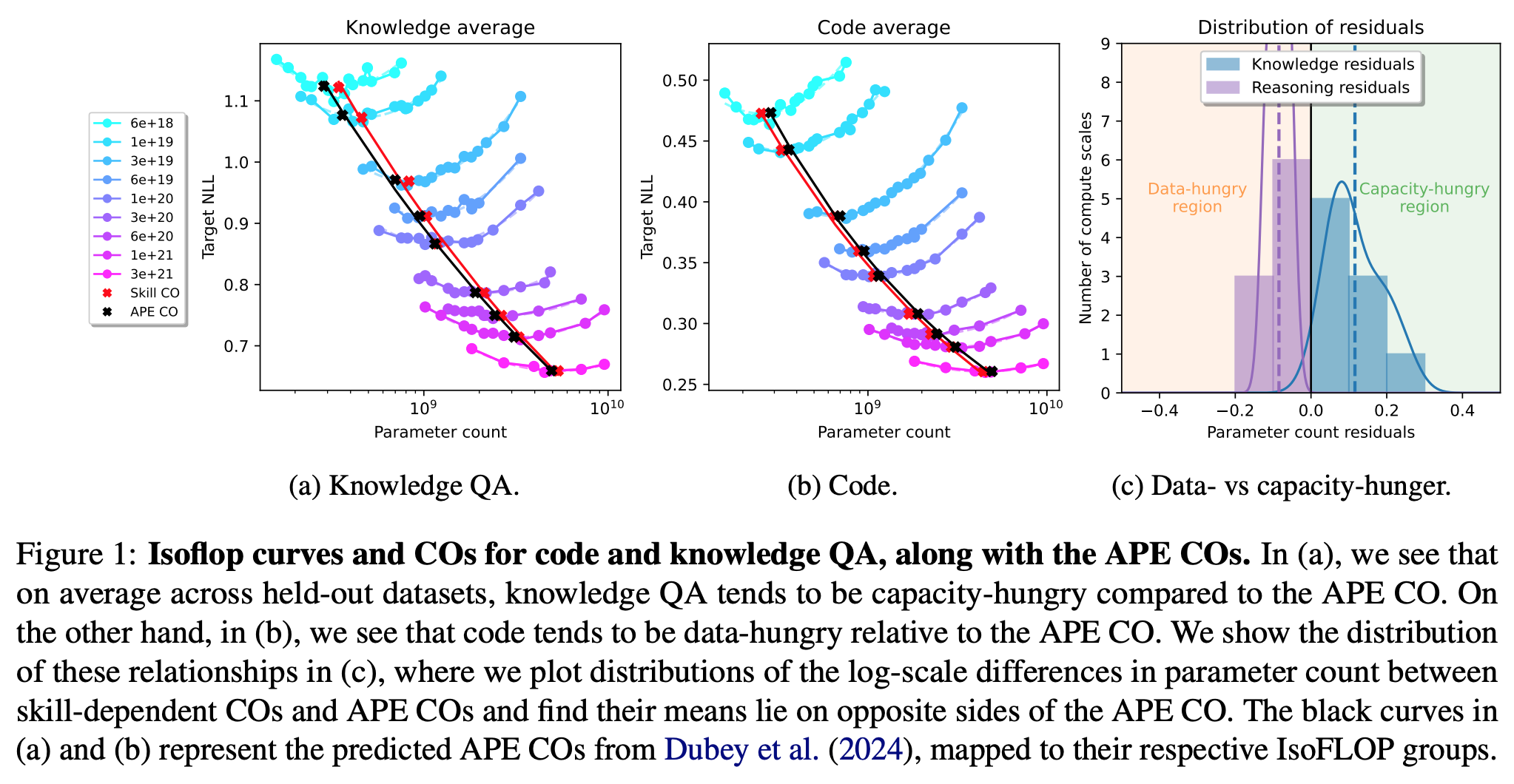
- model size: 40M ~ 8B
- skill CO: 데이터 셋의 Compute Optima
- APE CO: 전체 데이터에서 구한 (aggregate performance estimators) Compute Optima
- pretrain data mix
- 58.4% documents: factual knowledge
- 19.9%: code
- 21.7%: 나머지
연산량 고정 후, 데이터 비율 ablation
- FLOP = $6\times 10^{18}$
Code 데이터, knowldege 데이터 upsample
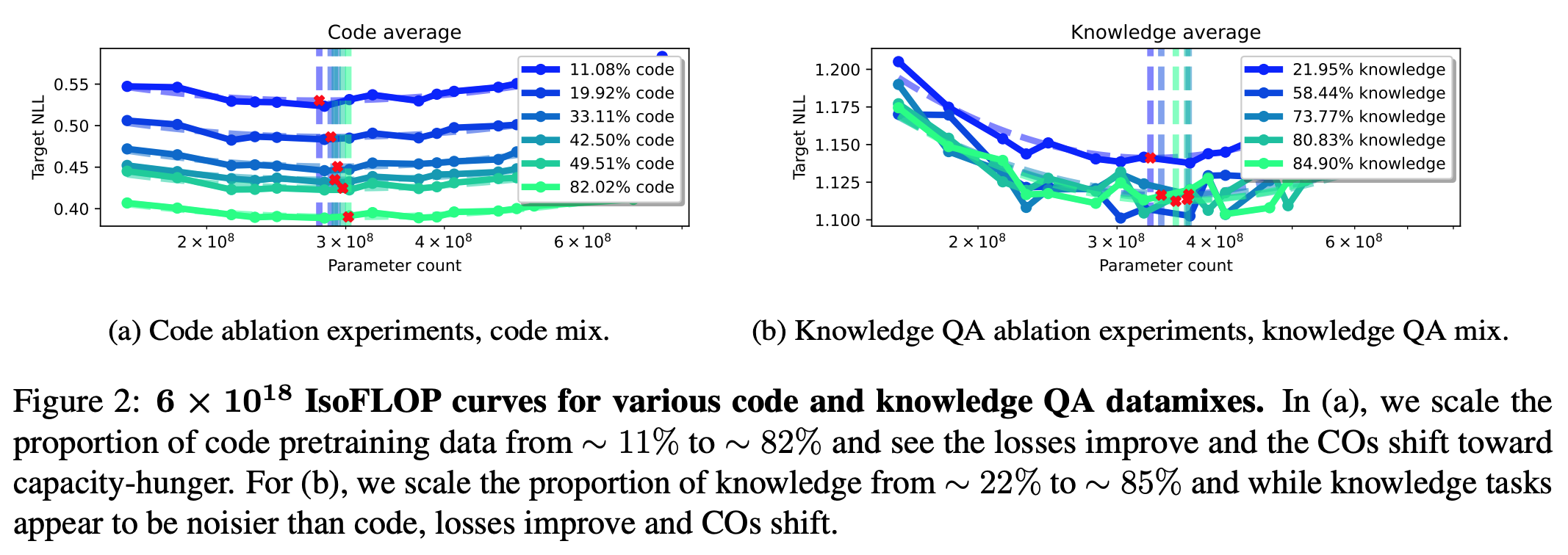 - loss 가 낮아지며 최적의 모델 사이즈가 늘어남. - code 의 경우, 그 경향성이 더 강함. - knowldege 의 경우가, 데이터 비율을 높일때 필요한 최적의 모델 사이즈가 더 큰 폭으로 늘어남.
- loss 가 낮아지며 최적의 모델 사이즈가 늘어남. - code 의 경우, 그 경향성이 더 강함. - knowldege 의 경우가, 데이터 비율을 높일때 필요한 최적의 모델 사이즈가 더 큰 폭으로 늘어남.
데이터 비율을 높일때 최적의 모델 사이즈
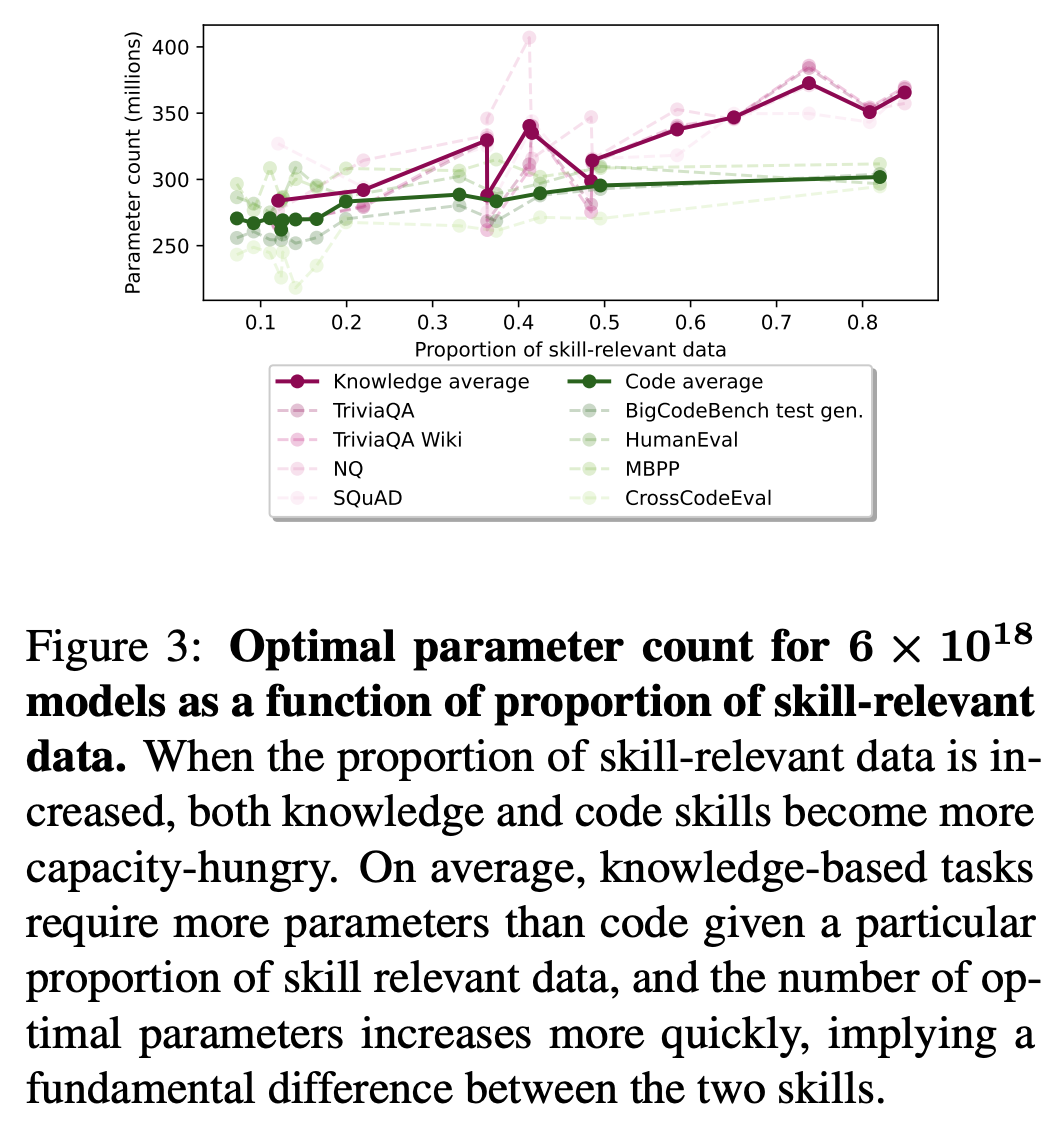
code, knowldege 데이터의 비율 조절하면서 최적의 모델 사이즈 추정
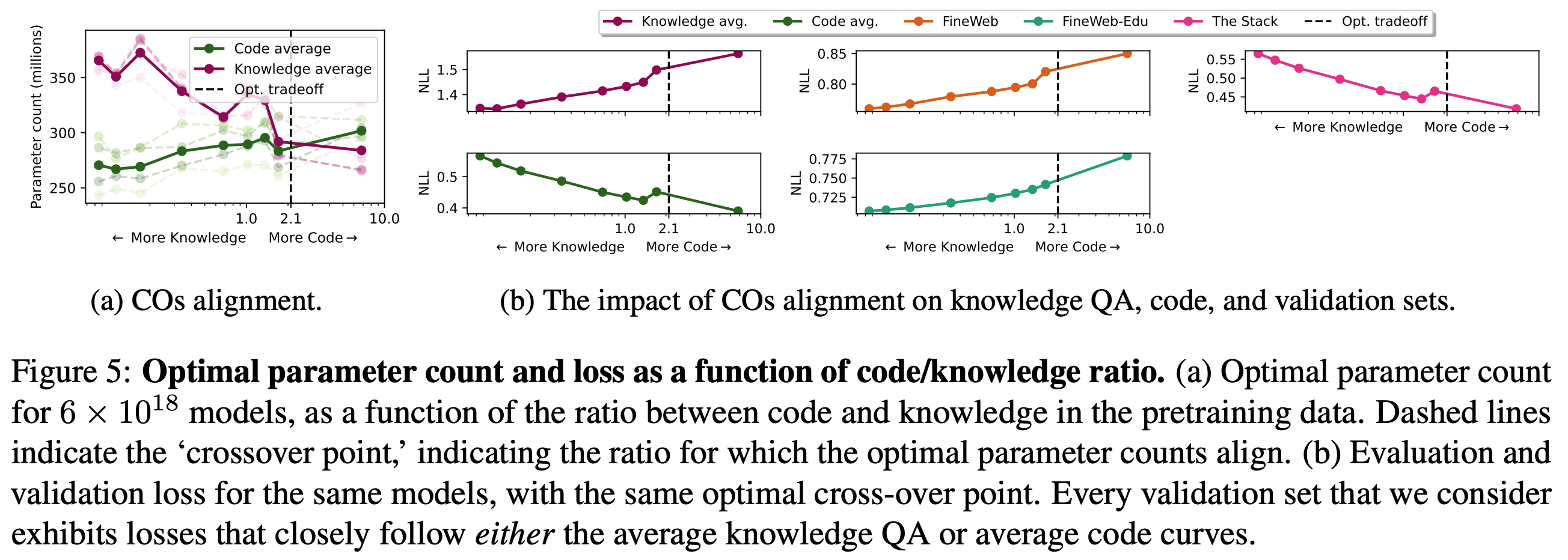
- knowledge 의 경우가, 데이터 비율이 높을때 필요한 최적의 모델 사이즈가 더 큼.
- Eval loss 는 각 데이터 별로 code 혹은 knowledge 경향성을 보임.
개별 데이터 셋으로 봤을때
- knowledge 의 경우가, 데이터 비율이 높을때 필요한 최적의 모델 사이즈 더 큼.
- 같은 연산량에서도, knowledge 의 경우가, 최적의 모델 사이즈 더 큼.