(논문 요약) DOES RLHF SCALE? EXPLORING THE IMPACTS FROM DATA, MODEL, AND METHOD (Paper)
핵심 내용
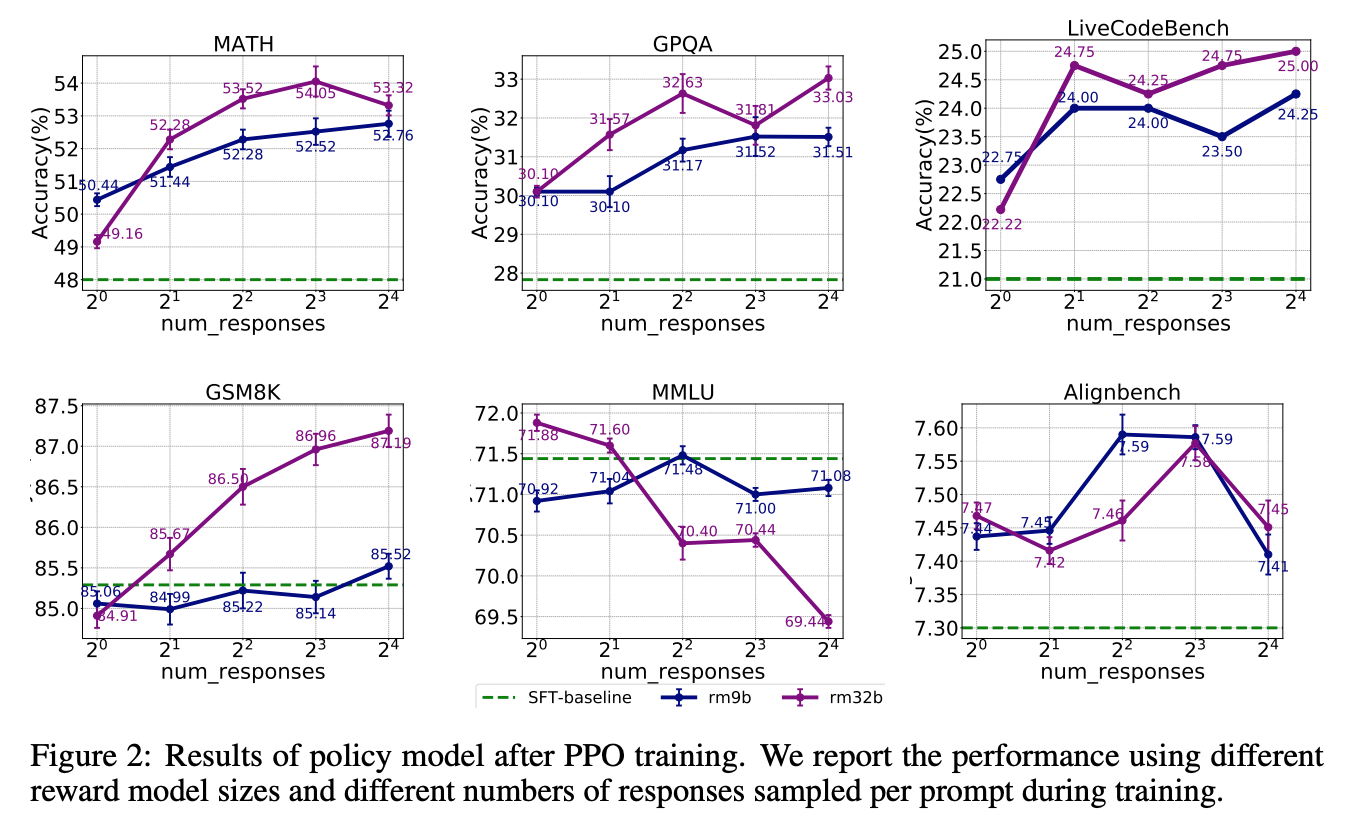
- Increasing data diversity and volume improves reward model performance.
- More response samples per prompt boost performance initially but quickly plateau.
- Larger reward models offer modest gains in policy training.
- Larger policy models benefit less from RLHF with a fixed reward model.
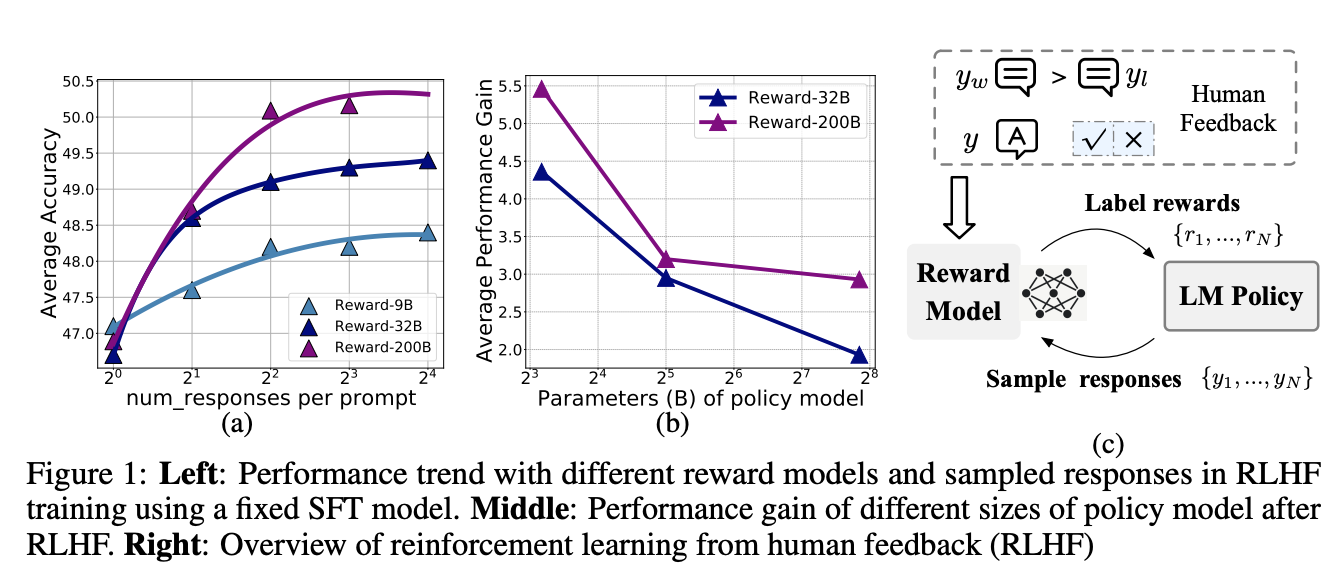
- task 에 따라 성능 추이가 다름.