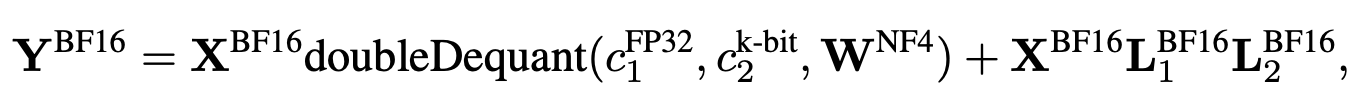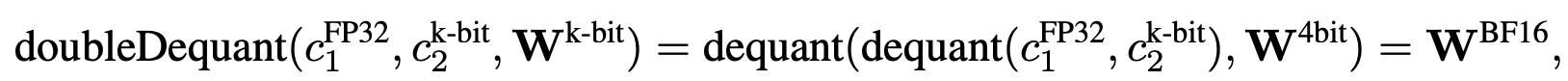Skip to main content
Link
Menu
Expand
(external link)
Document
Search
Copy
Copied
Jaemin's Arxiv
Book
Code Review
Computer Vision
Economy
ETF 가격 지표앱 개발
Quantitative Finance with Python
Language Model
Agents
Alignment
Analysis
Application
Architecture
Code and Math
Compute Efficiency
Data
Distributed Training
Embedding
Foundation Model
Hallucination
RAG
Training
Life
Realtor
Reinforcement Learning
Robot
Thoughts
Vision Language Model
(논문 요약) QLORA; Efficient Finetuning of Quantized LLMs
(논문 요약) QLORA: Efficient Finetuning of Quantized LLMs
(Paper)
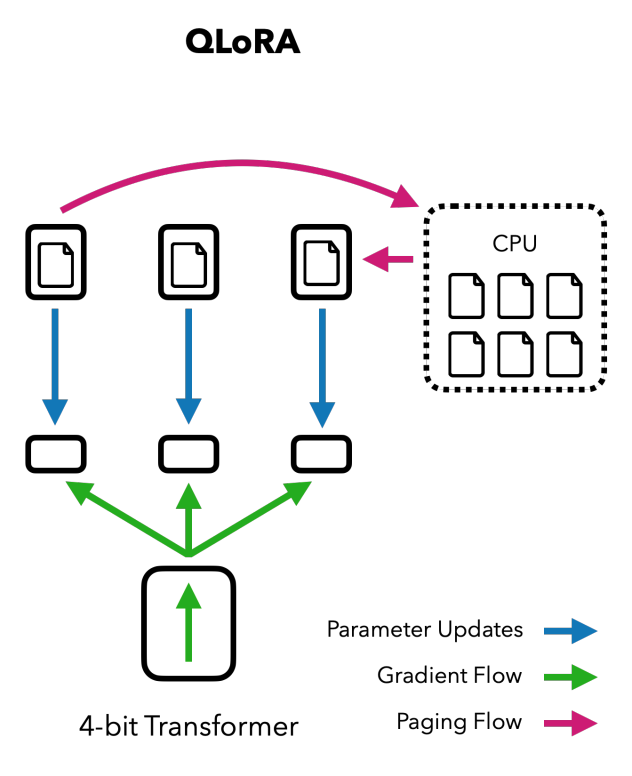
핵심 내용
base model weights:
4
-bit
lora:
16
-bit
optimizer:
32
-bit
double-quanitzation: quantized constants 들을 묶어서 다시 quantize