(논문 요약) Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs (Paper)
핵심 내용
o1 과 같은 reasoning 특화 모델은 token 을 많이 사용함.
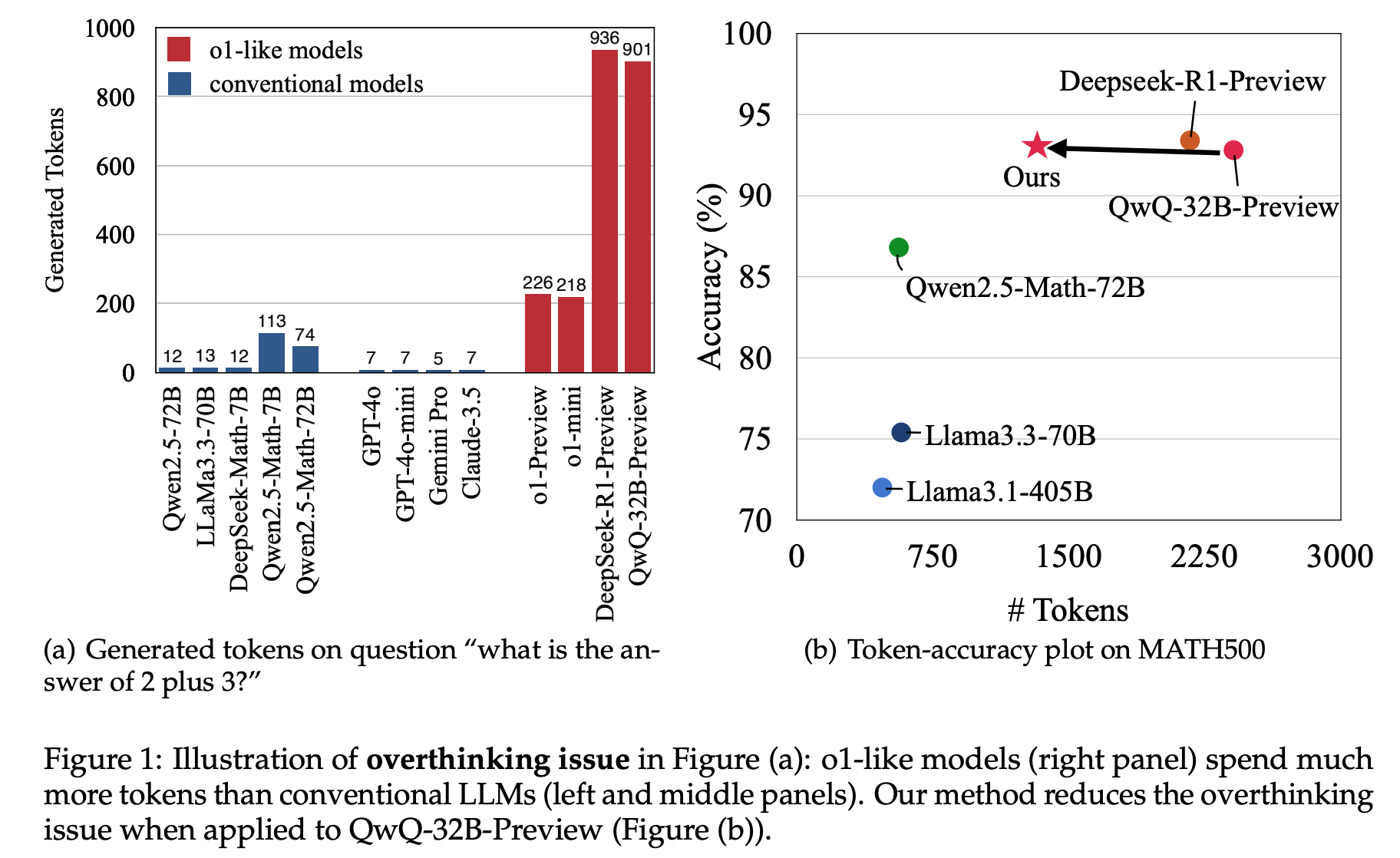
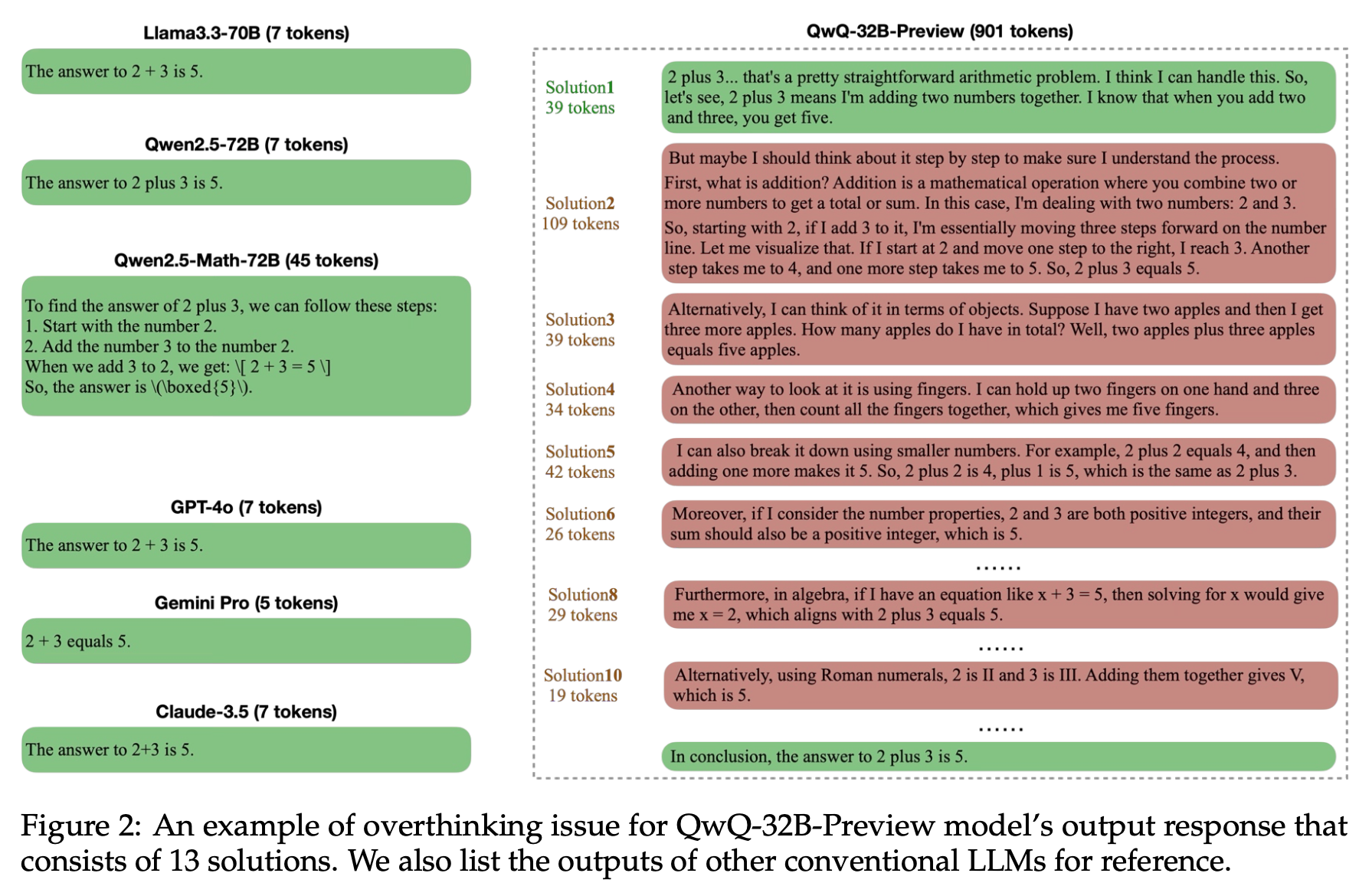
짧은 정답을 생성하여, SFT 혹은 preference optimization.
실험 결과
- 스스로 생성한 데이터를 사용하여, 짧아지면서 성능은 유지 가능.
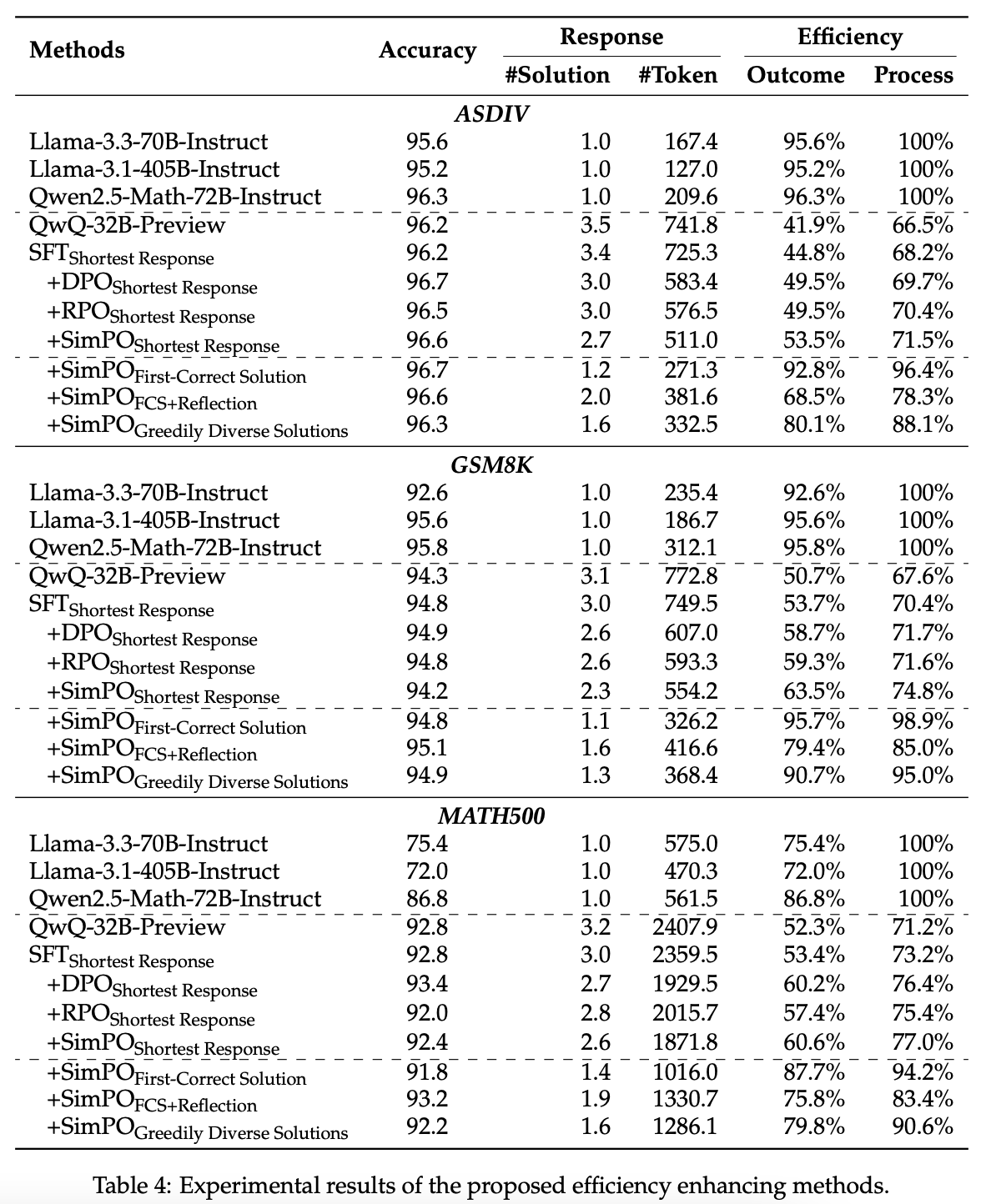
- temperature=1 에서, 10번 생성
- shortest response 등을 positive example 로 두고, longest response 를 negative 로 둠.