(논문 요약) LLAMA-OMNI: SEAMLESS SPEECH INTERACTION WITH LARGE LANGUAGE MODELS (paper)
핵심 내용
- Llama-3.1-8B Instruct 에서 speech 인식 가능하도록 추가 학습.
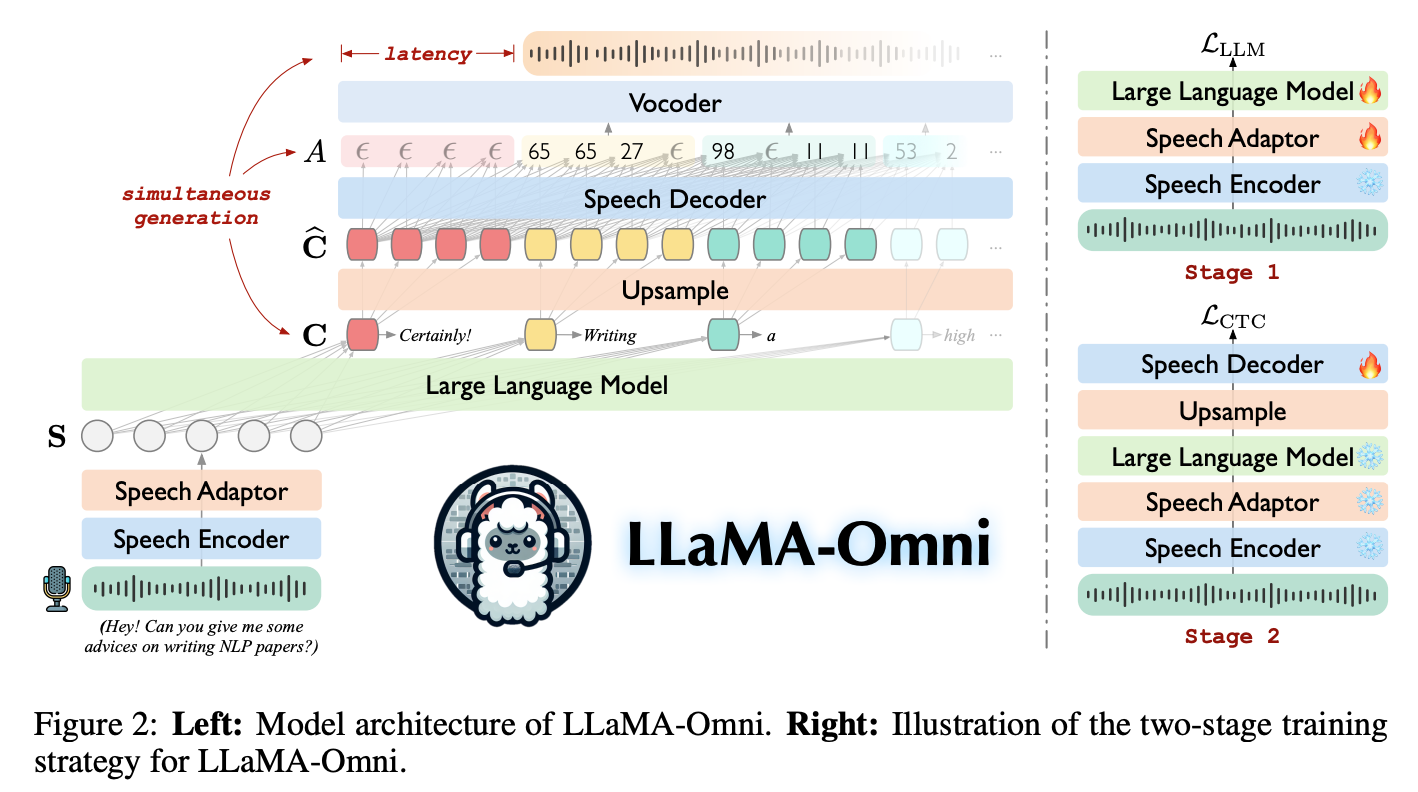
- speech encoder: Whisper-large-v3 (frozen)
- speech adapter: linear(relu(linear(reshape(x))))
- reshape 은 $L\times 1$ 을 $(L/k) \times k$ 로 shape 변환 (sequence 길이를 $L$ 에서 $L/k$ 로 줄이는 효과)
- (HuBERT: continuous representations of the speech -> discrete cluster indices 로 변환)
- speech decoder: LLaMA 와 같은 architecture 로, LLM 의 hidden states -> sequence of discrete cluster indices 로 변환
- vocoder: discrete units -> waveform 변환 (HiFi-GAN vocoder 모델 사용)
- 학습
- phase 1: voice -> text 학습 (speech adaptor, LLM weights)
- phase 2: voice -> voice 학습 (speech decoder weights)
- Instruct S2S-200K 데이터셋
- (speech instruction, text response, speech response) 형태
- 50K (sample from Alpaca dataset) + 150K (sample from UltraChat dataset)
- (text instruction, text response) 을 전처리 한뒤, TTS 모델로 음성 생성
- speech instruction: CosyVoice-300M-SFT 모델 사용
- speech response: VITS 모델 사용 (trained on LJSpeech dataset)
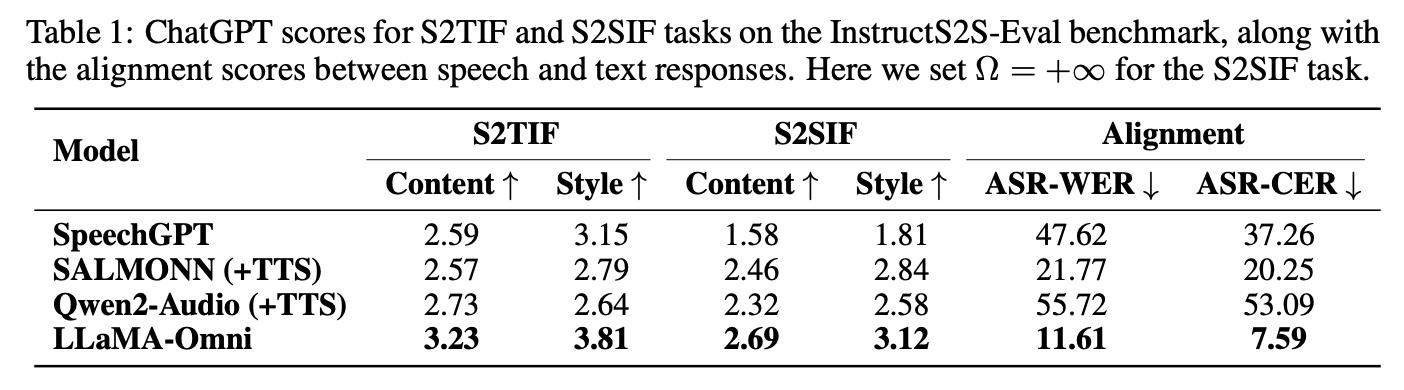
실험 결과