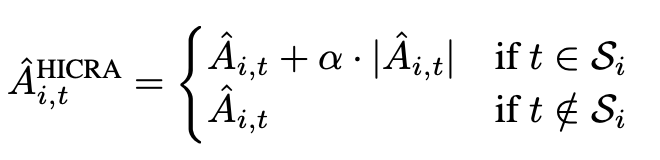(논문 요약) EMERGENT HIERARCHICAL REASONING IN LLMS THROUGH REINFORCEMENT LEARNING (Paper)
핵심 내용
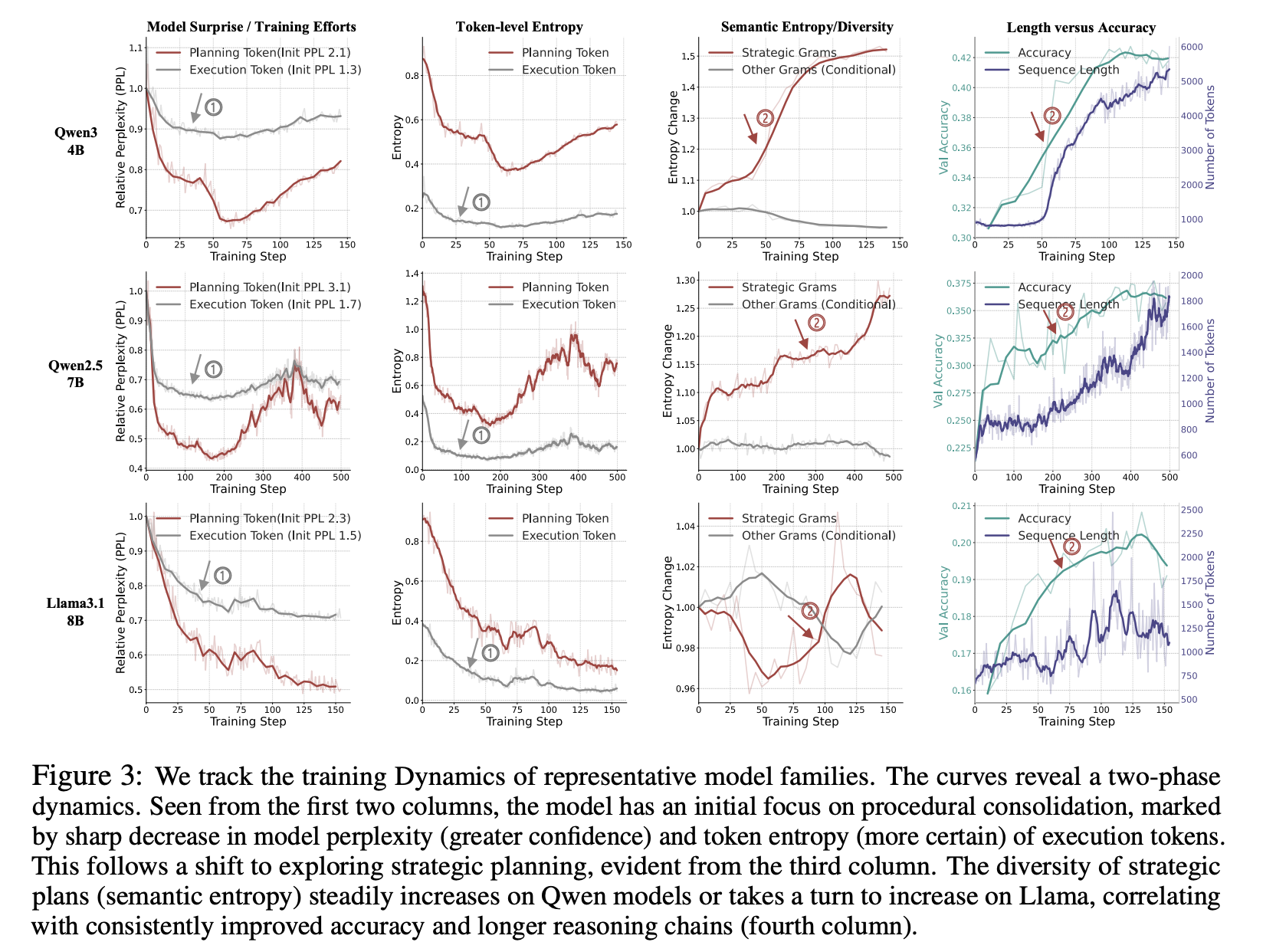
- RL 학습시 low level execution tokens 가 먼저 안정화됨.
- arithmetic calculations
- variable substitutions
- direct application of known formulas
- high-level strategic tokens 는 계속해서 학습됨.
- deduction (e.g., we can use the fact that)
- branching (e.g., let’s try a different approach)
- backtracing (e.g., but the problem mentions that)
- HICRA reward: $\alpha=0.2$ 을 설정하여, advantage 가 양수일때 strategic tokens 의 비중을 높이고, 음수일때 낮춤.