(논문 요약) Inference-Time Scaling for Generalist Reward Modeling (paper)
핵심 내용
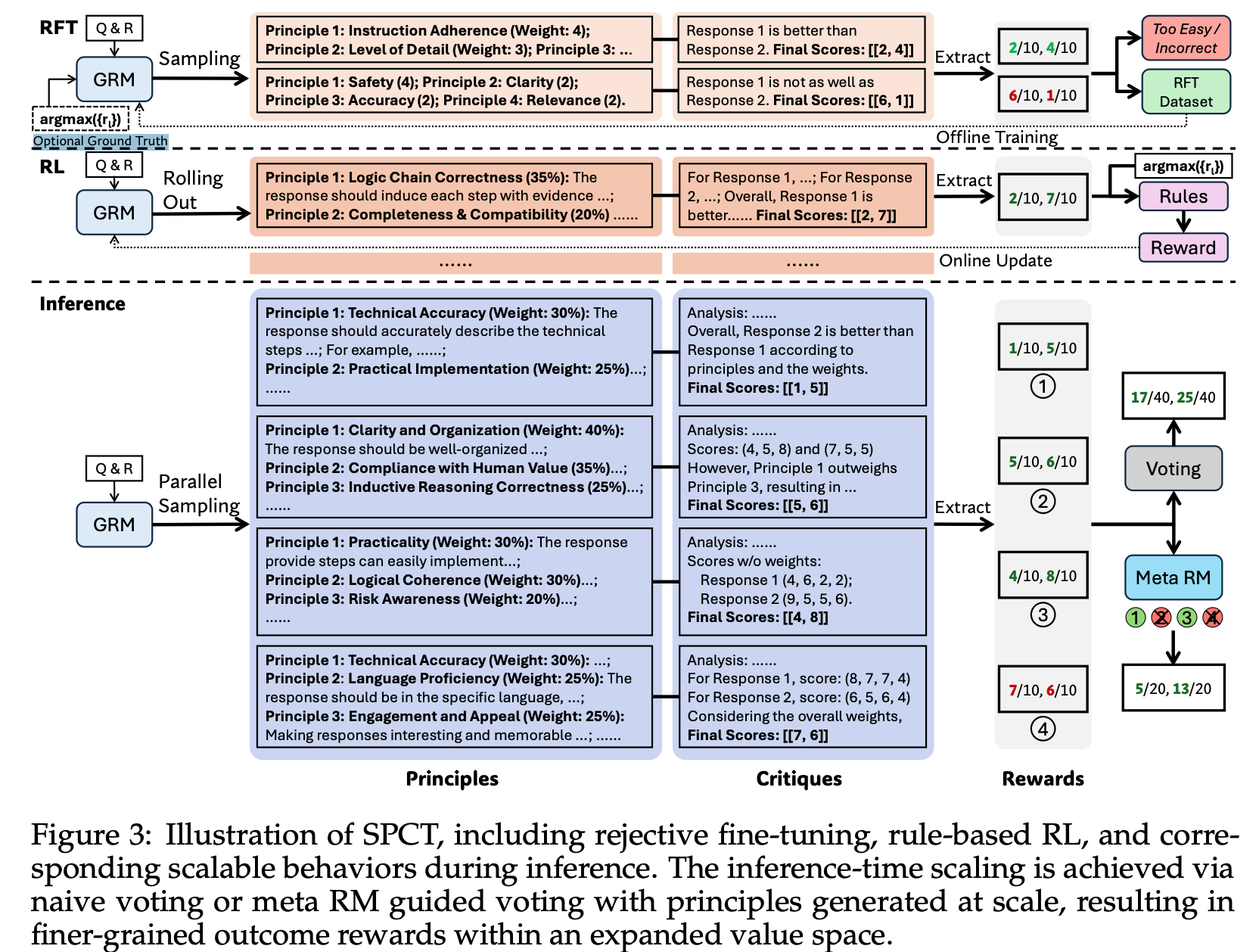
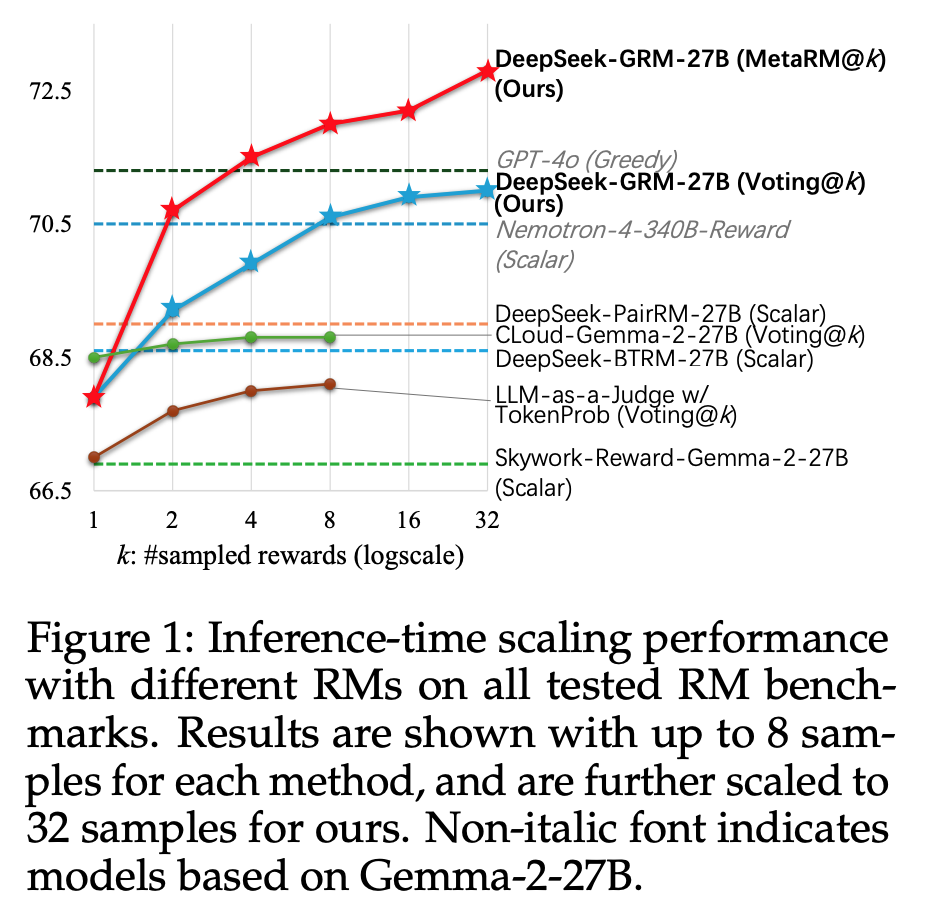
- GRM (generalist reward model): (principles, critiques) 생성하고 이후 per-response scores 생성
- Gemma-2-27B 를 post-train
- meta RM: GRM’s 의 sampled trajectories 를 filter 하기 위해 별도로 학습된 모델
- GRM 과 마찬가지로 Gemma-2-27B 를 별도의 trajectories 로 post-train
- binary cross entropy 사용하여 학습
- 실험에서는 $k$ 개 trajectories 중, 상위 $k/2$ 개를 남김