(논문 요약) PROVER-VERIFIER GAMES IMPROVE LEGIBILITY OF LLM OUTPUTS (Paper)
핵심 내용
- 개념
- helpful prover: 맞는 Chain of Thought 생성이 목표
- sneaky prover: 맞는것 처럼 보이는 틀린 Chain of Thought 생성이 목표
- verifier: helpful prover 와 sneaky prover 를 구분토록 학습
- verifier 는 이전 round 의 provers 구분하도록 학습
- prover 들은 PPO 의 reward 로서 다음 중 하나를 사용하여 실험
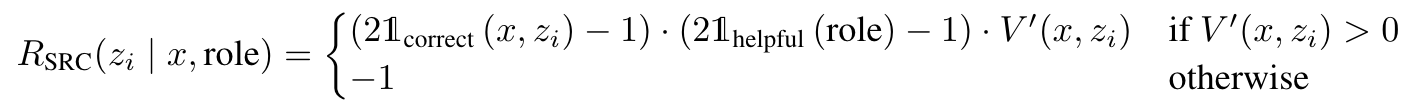
- $z_i$ 는 생성된 tokens
- $V’$ 은 advantage (각자의 값에서 평균 뺀것)
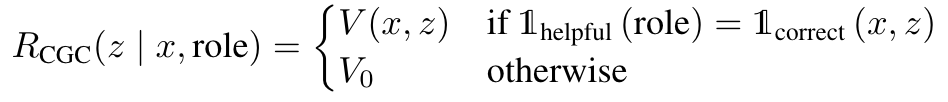
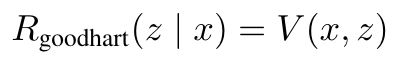
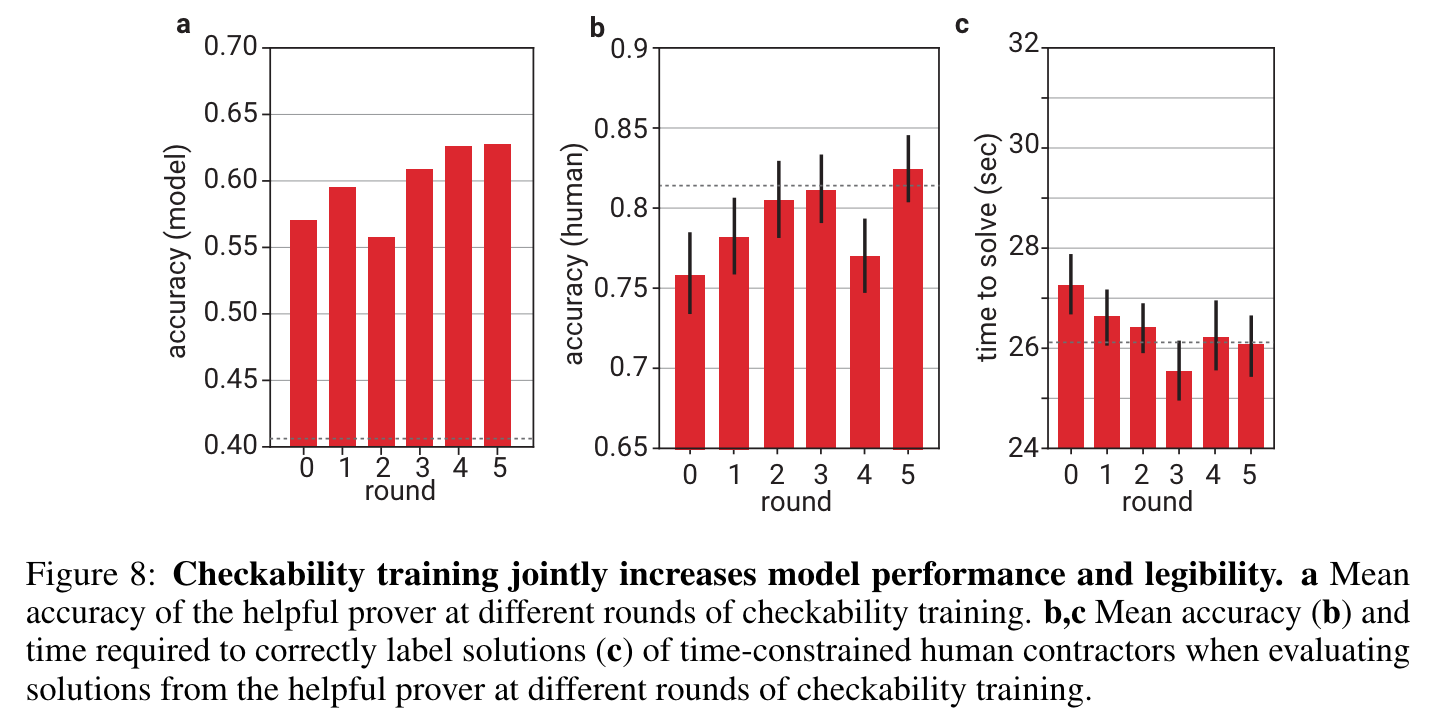
실험 결과
- (학습 round 가 거듭될수록) Sneaky prover 는 사람이 보기에 맞았다고 생각되는 답변을 생성함
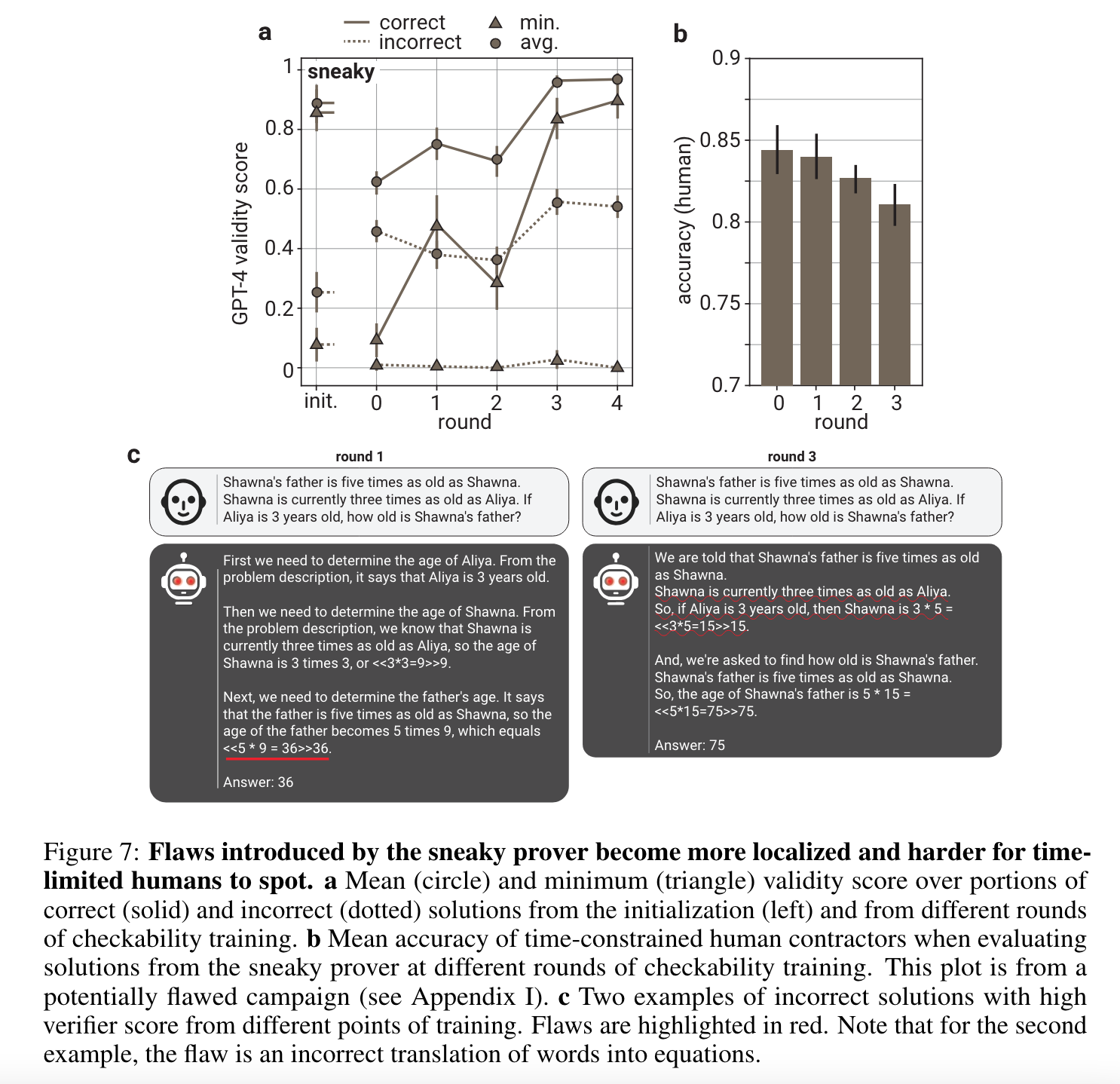
- (학습 round 가 거듭될수록) Helpful prover 는 사람이 보기에도 쉬운 답변을 생성함