(논문 요약) Qwen3 Technical Report (paper)
핵심 내용
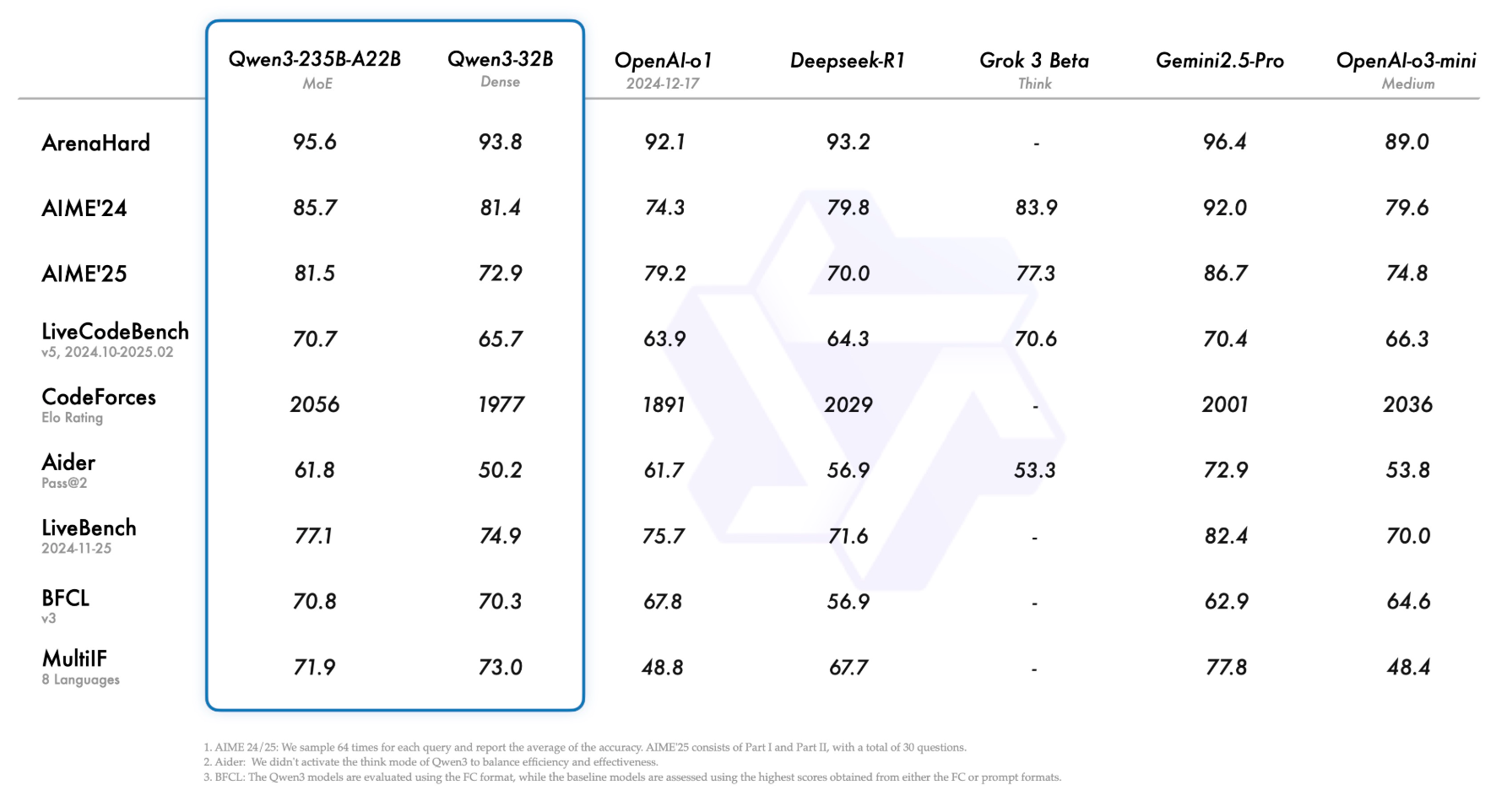
- openai-o1, Gemini 2.5 pro 에 크게 뒤지지 않는 benchmark 성능
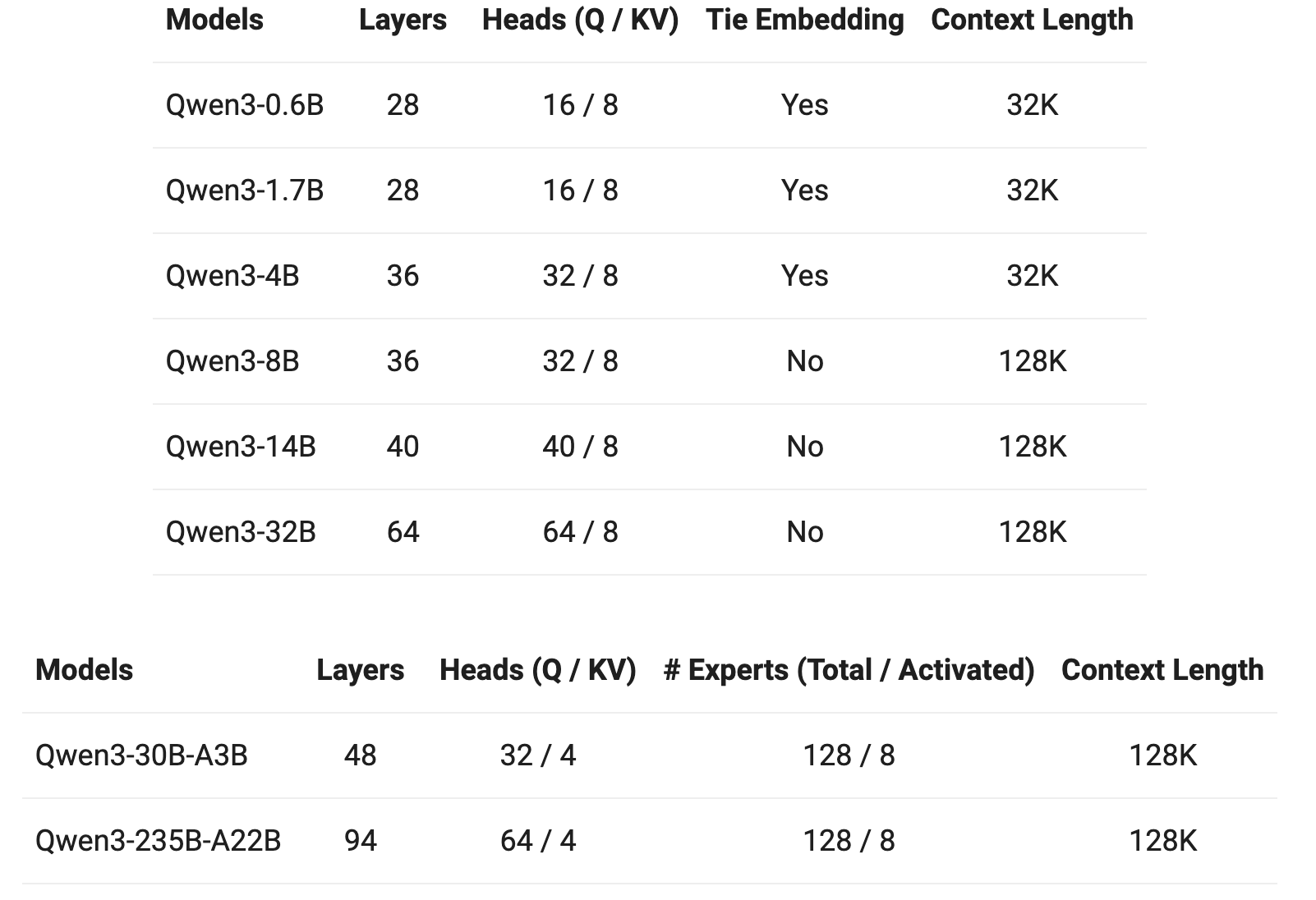
- Architecture
- grouped query attention
- SwiGLU
- Rotary Positional Embedding
- RMSNorm with pre-normalization
- QK-Norm
- KQV bias 없앰.
- MoE layer 에서 shared experts 없앰.
- pretrain
- 119개 언어, 36T token (Qwen2.5 에서는 18T)
- Qwen2.5-VL 로 이미지 인식후, Qwen2.5 로 refine 한 데이터: 수 T tokens
- Qwen2.5, Qwen2.5-Math, Qwen2.5-Code 로 생성한 데이터: 수 T tokens
- General Stage (S1): 30T tokens (context length of 4K tokens)
- Reasoning Stage (S2): 5T tokens (STEM, coding, reasoning)
- Long-Context Stage (S3): context length of 32K (16K~32K 75%, 4K~16K 25%)
- few shot evaluation 진행.
- 119개 언어, 36T token (Qwen2.5 에서는 18T)
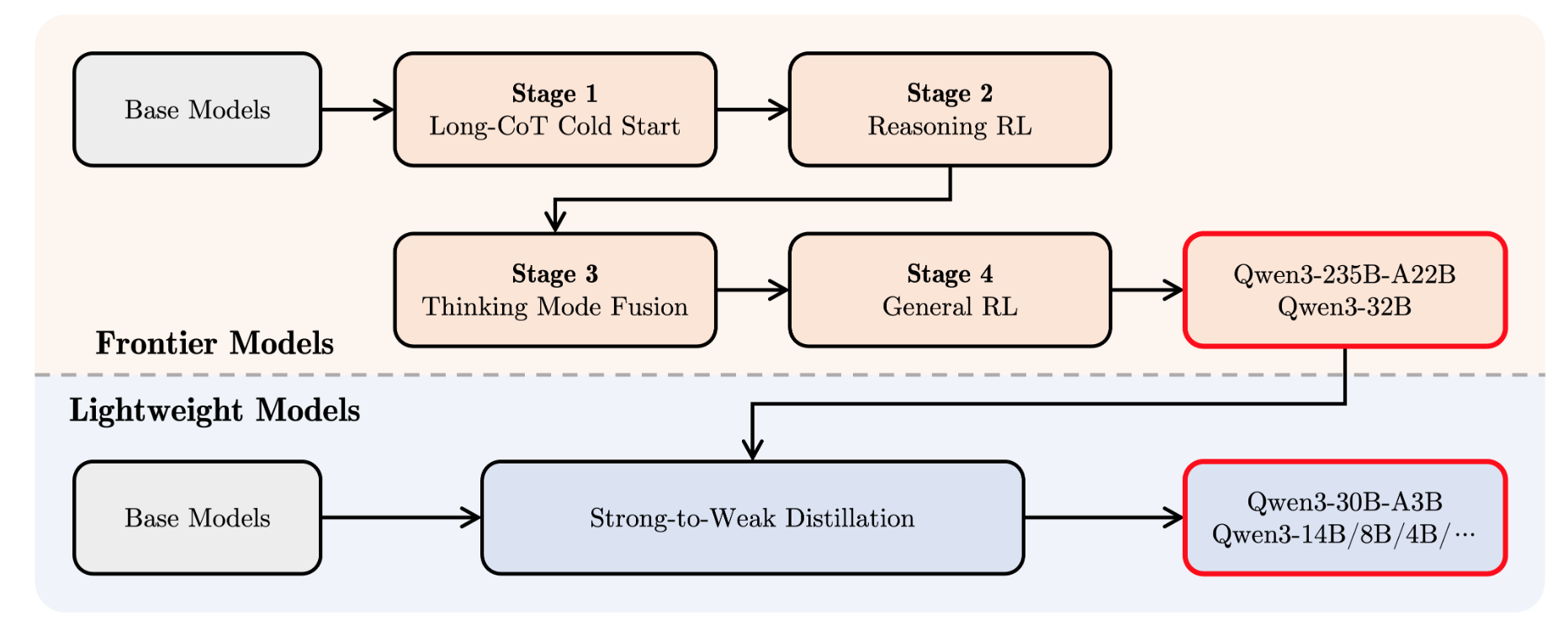
- post-train
- frontier 모델 학습 후, 작은 모델 학습시 distllation.
- frontier 모델 학습
- 1.Long-CoT-cold-start: verifiable hard data 로 데이터 생성후, SFT.
- non-verifiable queries (multiple sub-questions, general text gen), Qwen2.5-72B-Instruct 로 쉽게 풀리는 queries 는 제거.
- QwQ-32B 로 response 생성후, thinking 과 summary 가 consistent 하고, 정답이 맞고, 내용에 중복이 없고, 언어를 섞지 않는 경우에 label 로 사용.
- QwQ-32B 가 정답을 생성하지 못하는 경우, 사람이 생성.
- 2.Reasoning RL
- 3,995 query-verifier pairs 로 학습.
- 170 RL training steps
- 3.Thinking Mode Fusion: 모델 활용하여 데이터 생성후, SFT
- Thinking data: Long-CoT-cold-start 의 query 데이터에 Reasoning RL 학습된 모델의 response 사용.
- Non-thinking data: 다양한 도메인의 데이터 (구체적 내용 없음)
- 4.General RL
- Over 20 distinct tasks (each with scoring criteria)
- rule-based reward: instruction following, format adherence.
- model-based reward with reference: Qwen2.5-72B 가 reference 를 기반으로 점수 출력.
- model-based reward without reference: human preference 데이터로 모델을 학습시킨후, 점수를 출력하였다고 함 (구체적 내용 없음)
- 1.Long-CoT-cold-start: verifiable hard data 로 데이터 생성후, SFT.
- 기타
- data property annotation
- pretrain 데이터의 내용을 domain 별로 분류.
- Qwen2.5-72B-Instruct 사용하여 Long-CoT-cold-start data 의 query 를 domain 별로 classification.
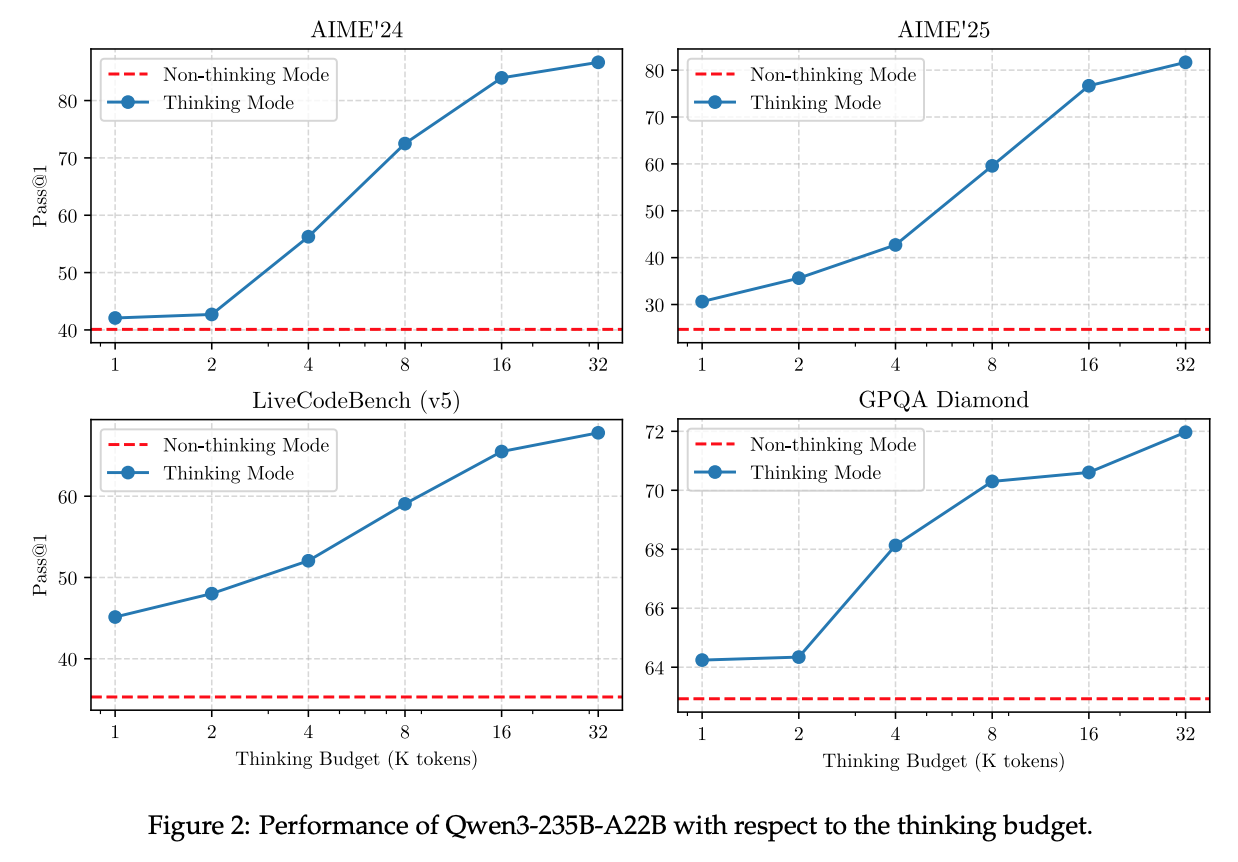
- Thinking Mode 에서 성능은 log(context_length) 와 선형관계.
- data property annotation