(논문 요약) Qwen2.5-Omni Technical Report (paper)
핵심 내용
- thinker: text, image, audio 를 input 으로 하여, text output
- talker: thinker 의 hidden feature 를 input 으로 하여, audio output

- Input 처리
- Audio
- resample (16kHz)
- 128-channel mel-spectrogram
- window size: 25ms
- hop size (overlap): 10ms
- Text: Qwen tokenizer
- Image: ViT encoder
- Video
- 소리 없는 경우: dynamic frame rate
- 소리 있는 경우: audio, image 40ms 간격으로 sample.
- Audio
- Pretrain
- vision adaptor: image-text pairs
- vision encoder: image-text pairs
- audio adaptor: audio-text pairs
- audio encoder: audio-text pairs
- 전체 파라미터: multimodal data (800B image+video tokens, 300B audio tokens, 100B video+audio tokens, token length < 8192)
- 전체 파라미터: multimodal data (length of 32k)
- Post-train
- Thinker: SFT
- Talker: speech continuation (SFT), DPO, multi-speaker SFT
실험 결과
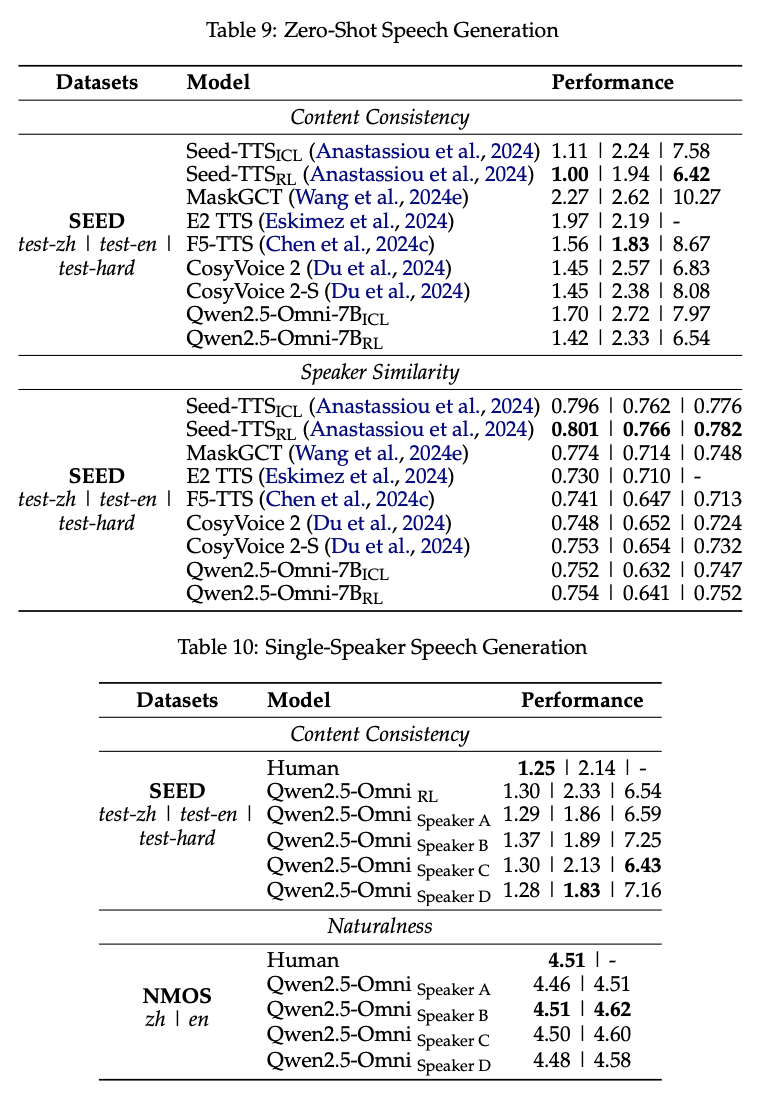
- speech to text
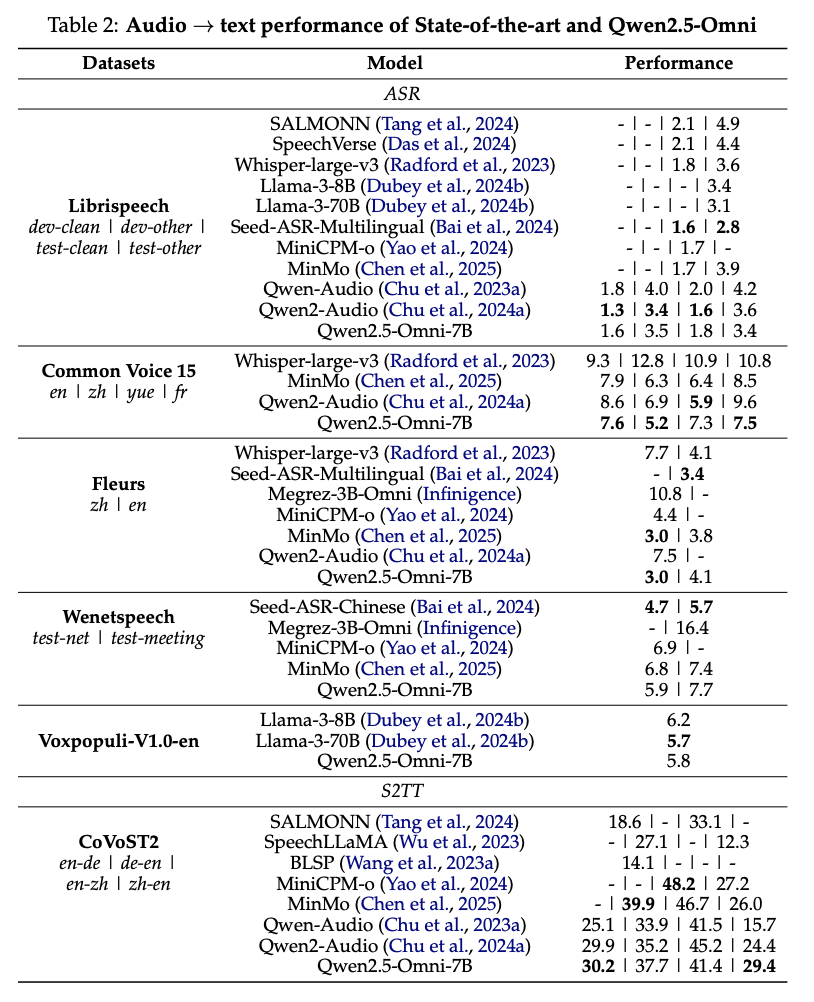
- speech generation