(논문 요약) QWEN2 TECHNICAL REPORT (paper)
핵심 내용
- Tokenizer: byte-level bytepair encoding of Qwen
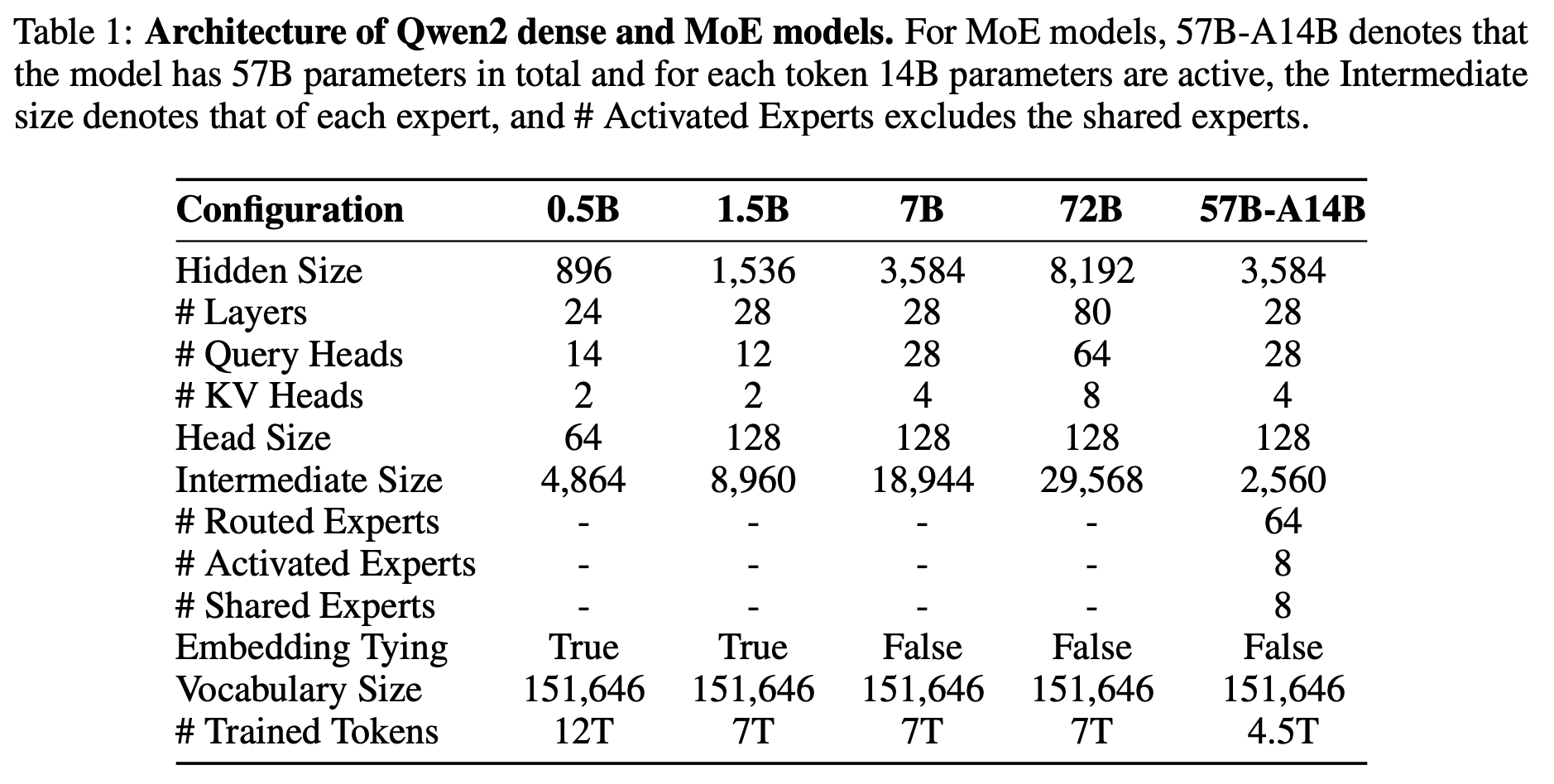
- Architecture
- MoE
- GQA
- Dual Chunk Attention with YARN (for long context)
- SwiGLU
- RoPE
- QKV bias
- RMSNorm
- pre-normalization
- Pretrain data: 7T tokens (30 languages)
- Long Context Training
- context window: 4,096 tokens -> 32,768 tokens
- base frequency of RoPE: 10,000 -> 1,000,000
- Post-training
- SFT: 500,000 examples (instruction following, coding, mathematics, logical reasoning, role-playing, multilingualism, and safety)
- DPO: offline preference dataset, online preference generated by a reward model (online 학습의 경우, Online Merging Optimizer 라는 걸 썼다고 함)
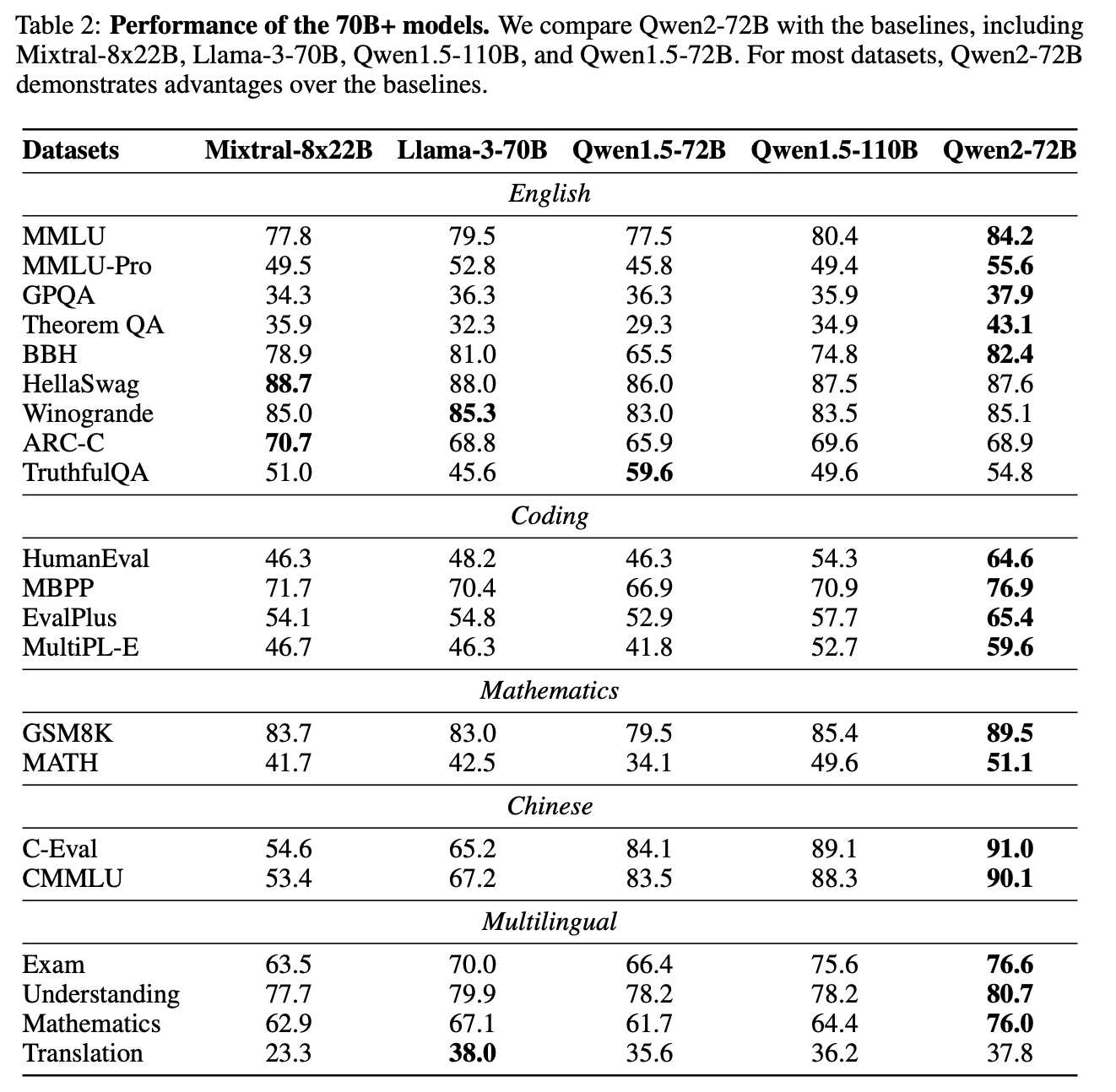
실험 결과
- benchmark 에서 Llama-3-70B 보다 높은 성능