(논문 요약) Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs (Paper)
모델
- Chinese, English, French, German, Italian, Japanese, Portuguese, Spanish 지원
- Phi-4-Multimodal: 5.6B (vocabulary size 200K)
- vision+language
- vision+speech
- speech/audio
- Phi-4-Mini: 3.8B (vocabulary size 200K)
- Architecture: 32 decoder-only transformer layers with 128K context length based on LongRoPE
tokenizer: o200k_base tiktoken
- LoRA adapter
- vision: 370M parameters
- speech/audio: 460M parameters
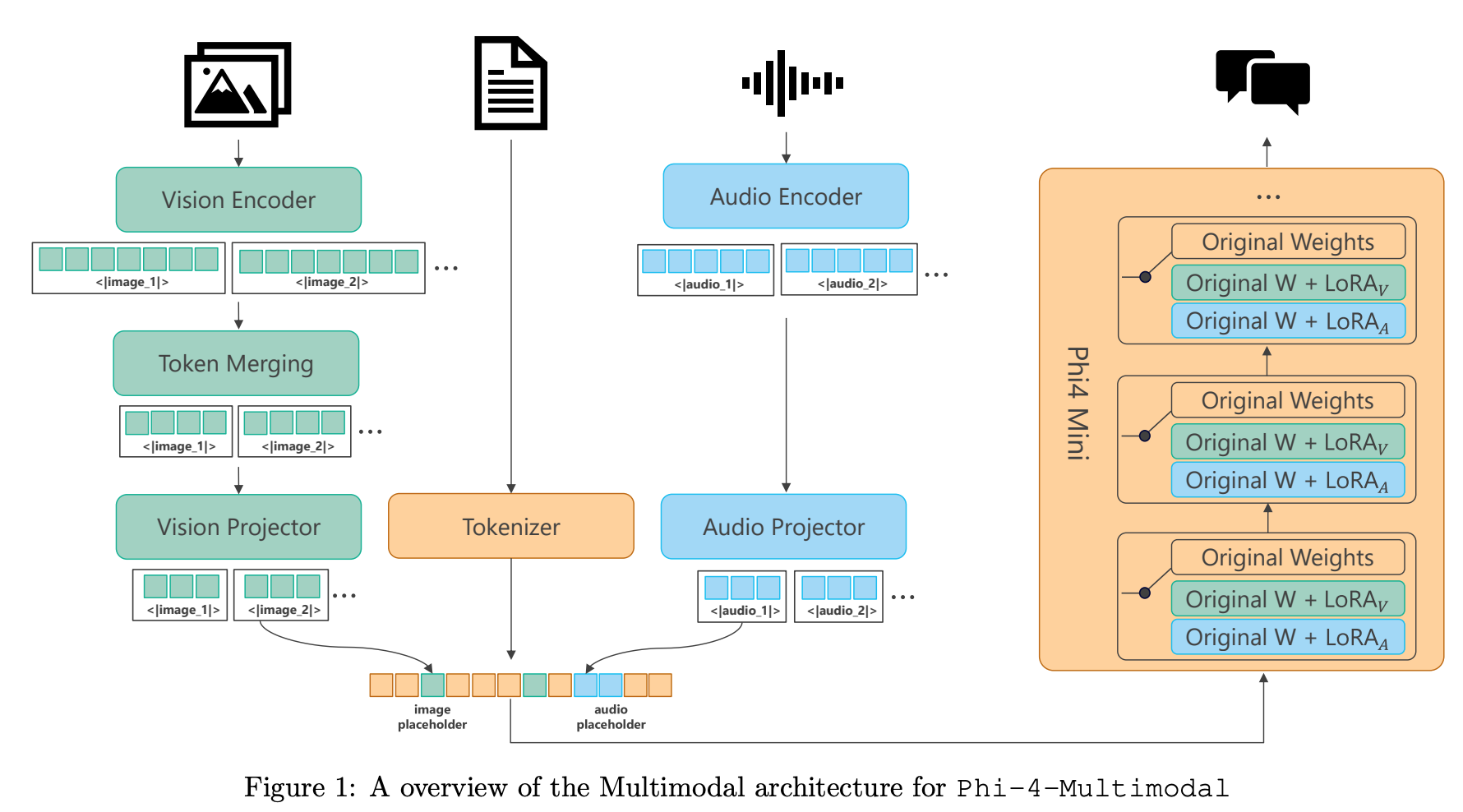
학습
- Vision
- projector only
- vision encoder + projector (OCR and dense understanding)
- vision encoder + projector + llm + lora with single-frame SFT data
- projector + llm + lora with multi-frame SFT data
- Speech and Audio
- audio encoder + projector
- projector + llm + lora with multi-frame SFT data
- 생성 데이터를 filtering 하여 데이터 quality 를 유지함.
성능
Phi-4-Multimodal 의 vision-language task 성능
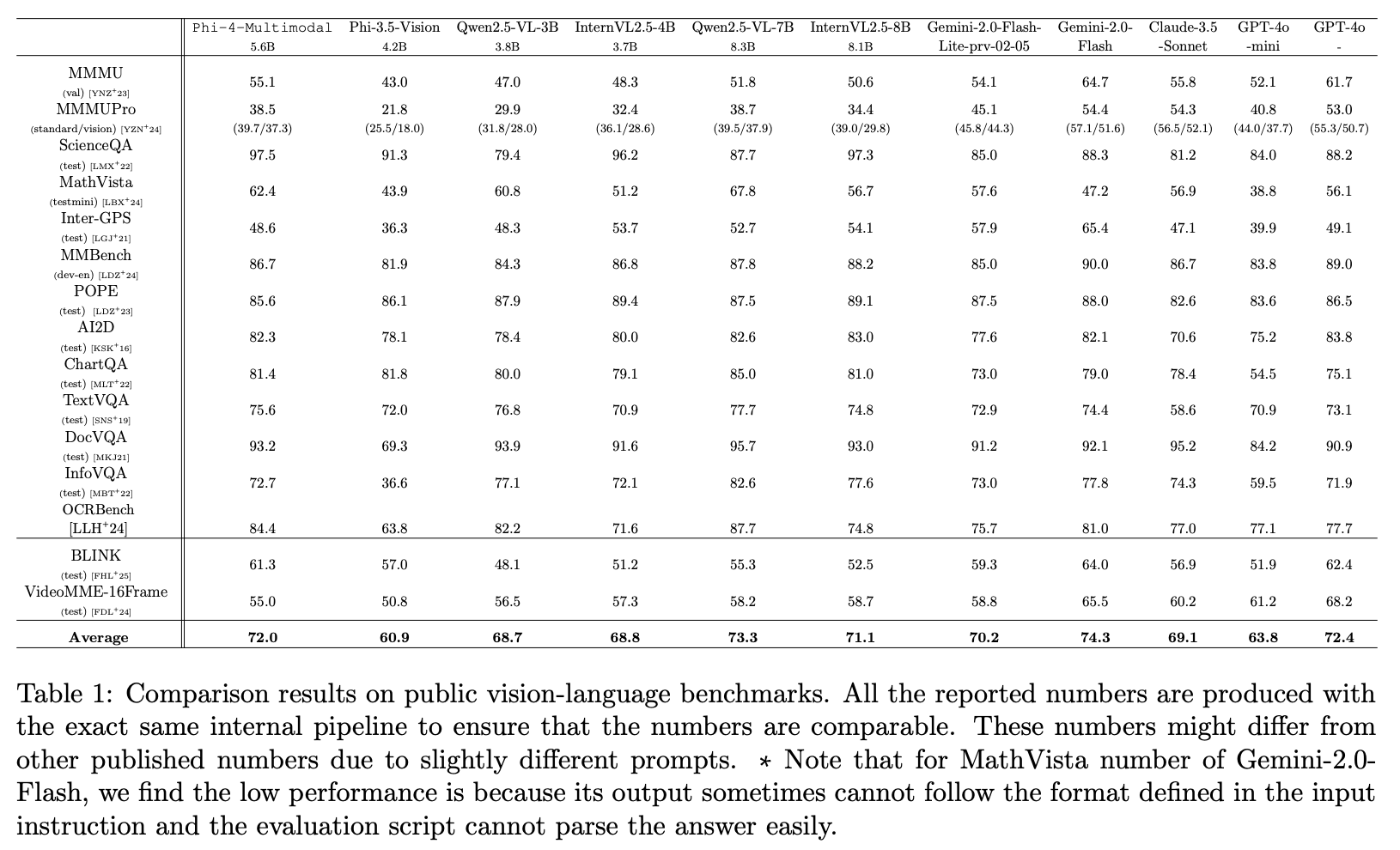
Phi-4-Mini 의 language 성능