(논문 요약) Phi-4 Technical Report (Paper)
모델
- Phi-4: 14B, 16K context window, tiktoken tokenizer, primarily English.
- Phi-3 와 마찬가지로 데이터 퀄리티 높이는데 초점.
- 실 데이터 (web content, code) + 생성 데이터 (총 10T tokens)
학습
- linear warm-up and decay schedules with peak learning rate of 0.0003,
- constant weight decay of 0.1
- global batch size of 5760
- phase 1: 주로 filtered web data
- phase 2: synthetic tokens + ultra-filtered and reasoning-heavy web data
- key findings
- Web datasets showed small benefits on reasoning heavy benchmarks. Prioritizing more epochs over our synthetic data led to better performance with respect to adding fresh web tokens.
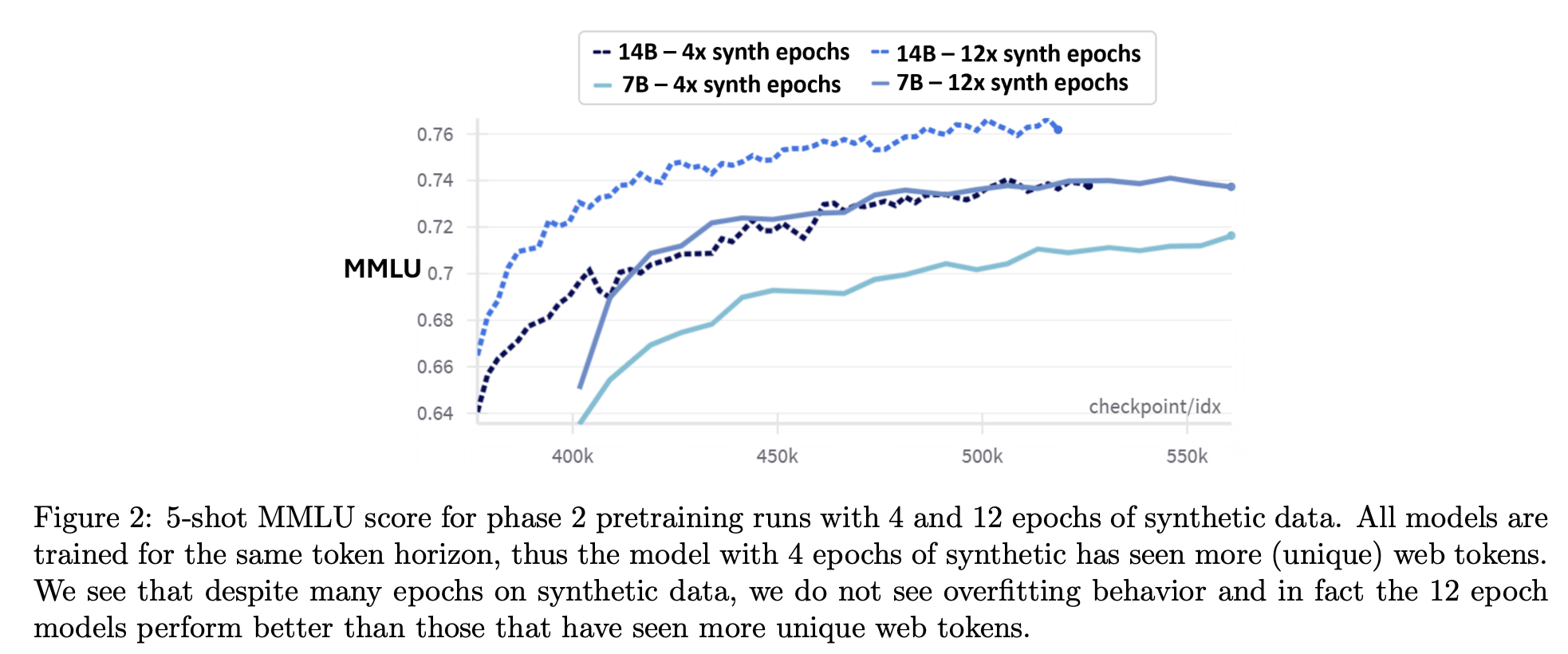
- Models trained only with synthetic data underperformed on the knowledge-heavy benchmarks and demonstrated increased hallucinations.
- 각 데이터 소스별 에폭수는 fraction 에 비례, unique token count 에 반비례
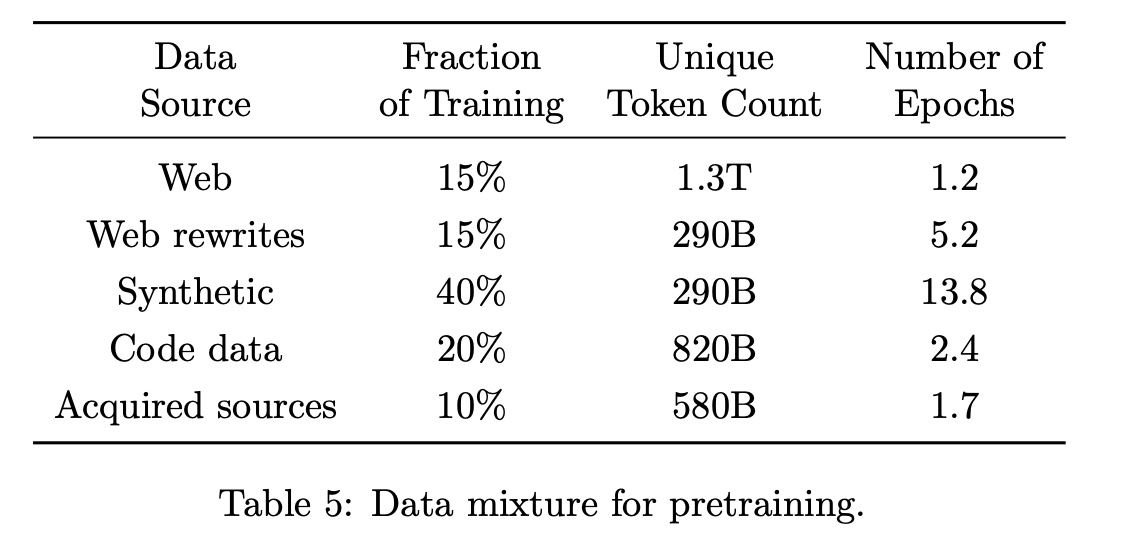
- Web datasets showed small benefits on reasoning heavy benchmarks. Prioritizing more epochs over our synthetic data led to better performance with respect to adding fresh web tokens.
- mid-training: context window 4K -> 16K
- academic, books, code data 에서 8K 이상 데이터
- 16K 이상 데이터 up-sample
- 4K 이상인 생성 데이터 (30%)
- supervised-finetuning data: 8B tokens in 40 languages in chatml format
- Pivotal Token Search for direct preference optimization
- $abs(p(success∣t_1,…,, t_i) − p(success∣t_1,…,, t_{i-1})) > threshold$ 인 경우,
- $t_i$ 가 pivotal token (결정적으로 성공률에 영향을 미치는 토큰)
- $p(success)$ 는 끝까지 completion 해서 oracle 을 통해 empirical probability 계산
- 경험적으로 너무 쉽거나 어려운 경우, pivotal token 은 없어서, $0.2 \leq p(success) \leq 0.8$ 인 question 만 대상으로 함
생성 데이터
- 원칙
- Diversity: 각 domain 의 subtopics, skills 를 골고루 포함
- Nuance and Complexity: basics 뿐만 아니라 advanced, edge case 포함
- Accuracy: 정확한 코드, 맞는 증명, 올바른 지식만 포함
- Chain-of-Thought: systematic reasoning (step-by-step manner) 을 포함
- (생성시 참조할) seed data curation
- Web and Code-based Seeds: identify pages with strong educational potential, and, segment the selected pages into passages, scoring each for its factual and reasoning content.
- Question Datasets (websites, forums, Q&A platforms 에서 수집): generated multiple independent answers for each question and applied majority voting to assess the consistency of responses, then, discarded questions where all answers agreed (too easy) or where answers were entirely inconsistent (too ambiguous)
- Creating Question-Answer pairs from Diverse Sources: books, scientific papers, and code 에서 Q&A 생성 (The language model identifies key steps in reasoning or problem-solving processes and reformulates them into questions and corresponding answers)
- Rewrite and Augment: rewrite passages of seed data into exercises, discussions, or structured reasoning tasks (using an LLM)
- Self-revision: a model improves its own outputs guided by the rubrics focused on reasoning and factual accuracy.
- Instruction Reversal for Code and Other Tasks: code -> instruction -> generated code 생성후, 원 code 와 high fidelity 인 것들을 데이터로 사용.
- Validation of Code and Other Scientific Data: 코드는 실행해보고 검증하고 scientific questions 는 scientific materials 에서 발췌.
- Q&A datasets 은 수천만개 high-quality organic problems and solutions 데이터 수집. 정답이 정확하지 않은 경우, majority voting 으로 정답 대체.
- Web data: arXiv, PubMed Central, GitHub, licensed books 에서 수집하고, web dump 에서 topic classifications pipeline 활용하여 high-quality STEM, non-STEM content 수집.
- 글자가 깨지지 않도록 HTML-to-text extractor 를 custom 하게 개발.
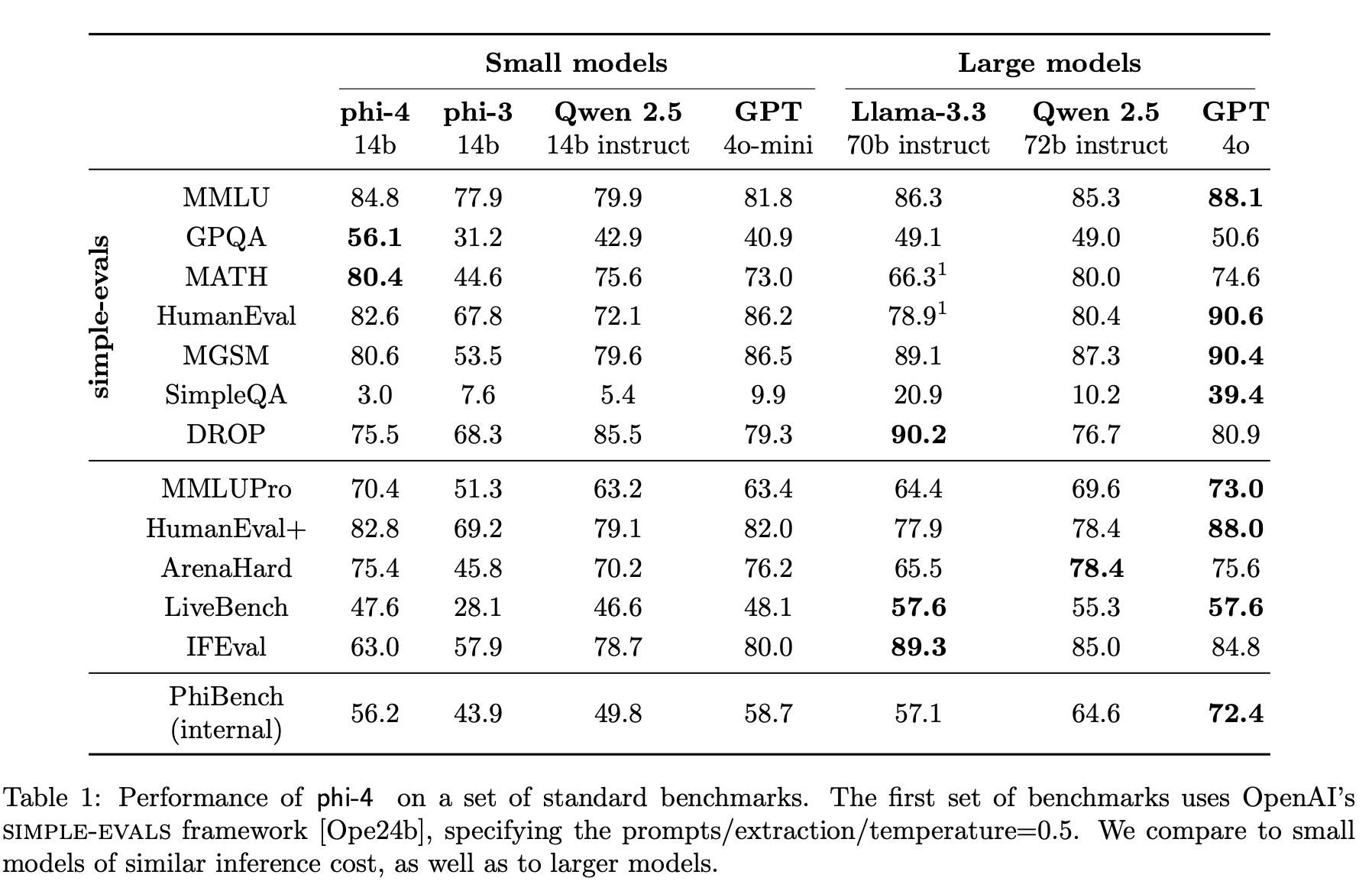
성능
- 일부 task 에서는 gpt-4o 와 근접