(논문 요약) Phi-3 Technical Report:A Highly Capable Language Model Locally on Your Phone (Paper)
핵심 내용
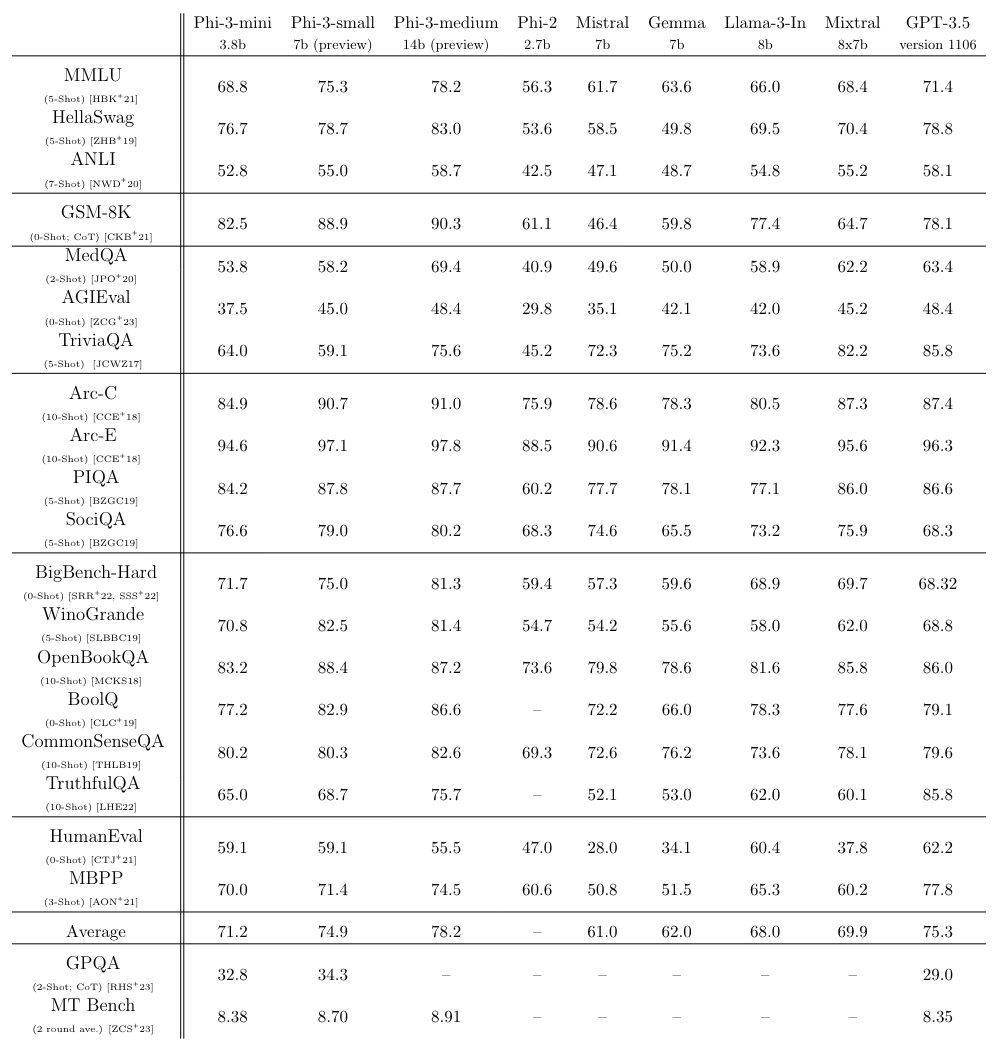
- Phi-3 mini: 3.8B model trained on 3.3T tokens (Mixtral 8x7B 과 GPT-3.5 에 근접)
- Textbooks Are All You Need 학습 방법 대로 데이터 퀄리티 높이는데 초점.
- Pretrain
- Phase-1 학습: mostly of web sources (general knowledge and language understanding).
- Phase-2 학습: even more heavily filtered webdata (a subset used in Phase-1) with some synthetic data (logical reasoning and various niche skills).
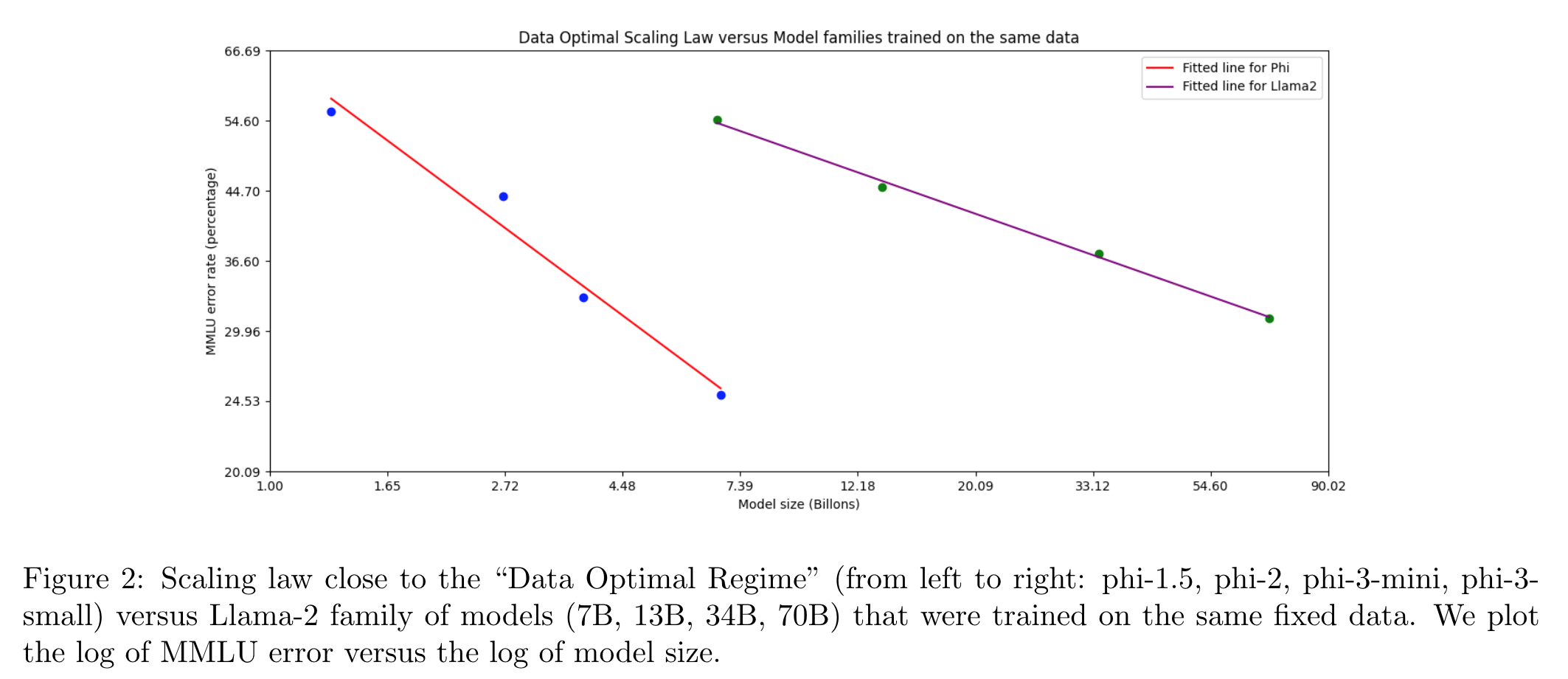
- Llama2 보다 data, parameter efficient.
- Postrain
- supervised finetuning (SFT): highly curated high-quality data across diverse domains, e.g., math, coding, reasoning, conversation, model identity, and safety (english-only).
- direct preference optimization (DPO): format data, reasoning, and responsible AI (RAI) efforts.
실험