(논문 요약) Open Mixture-of-Experts Language Models (paper) (model) (data) (code)
핵심 내용
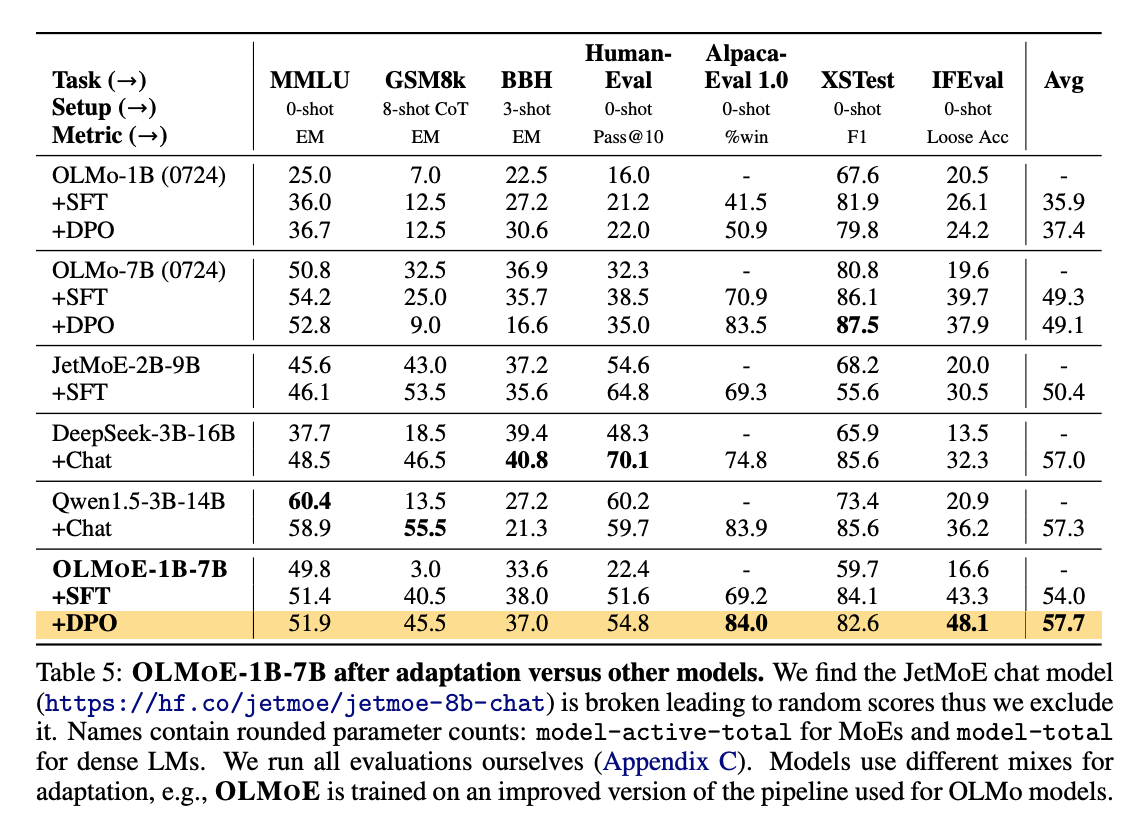
total 7B, 1B per input token MoE 모델 및 학습 데이터 공개
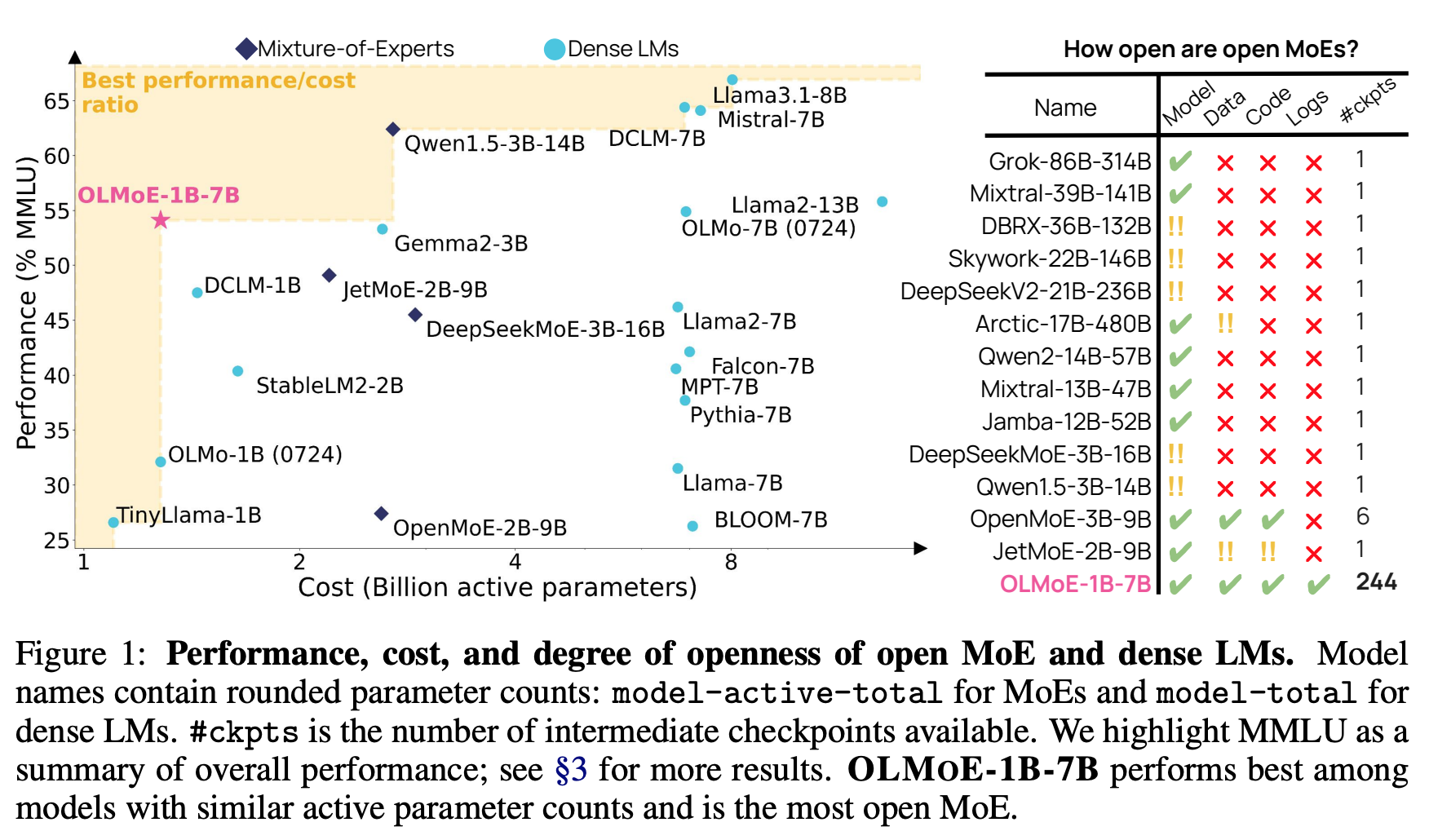
- architecture
- Mixture of Experts Module: Top-k experts 의 softmax 로 weighting ($k=8$ out of 64 experts)
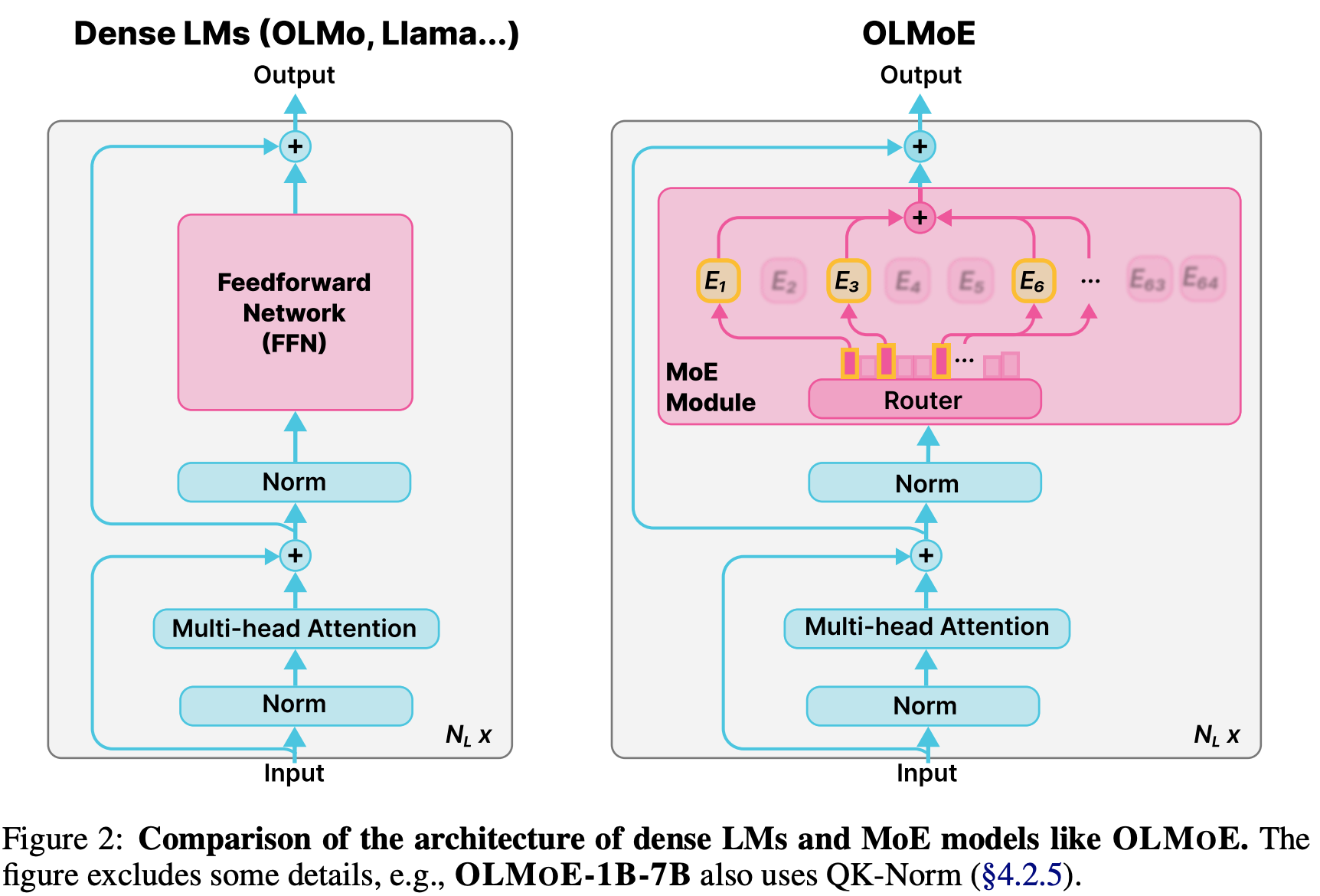
- key design
- add layer normalization after the queryand key projections (QK-Norm)
- Mixture of Experts Module: Top-k experts 의 softmax 로 weighting ($k=8$ out of 64 experts)
학습 자원: 128 H100 GPUs 사용
- 안정적인 학습을 위한 loss 및 initialization 방법 서술
- 일부 experts 에 몰리는 현상 방지하기 위해 load balacing loss 추가
- large logit penalize 하는 Router Z-loss
- truncated normal initialization
- RMSNorm
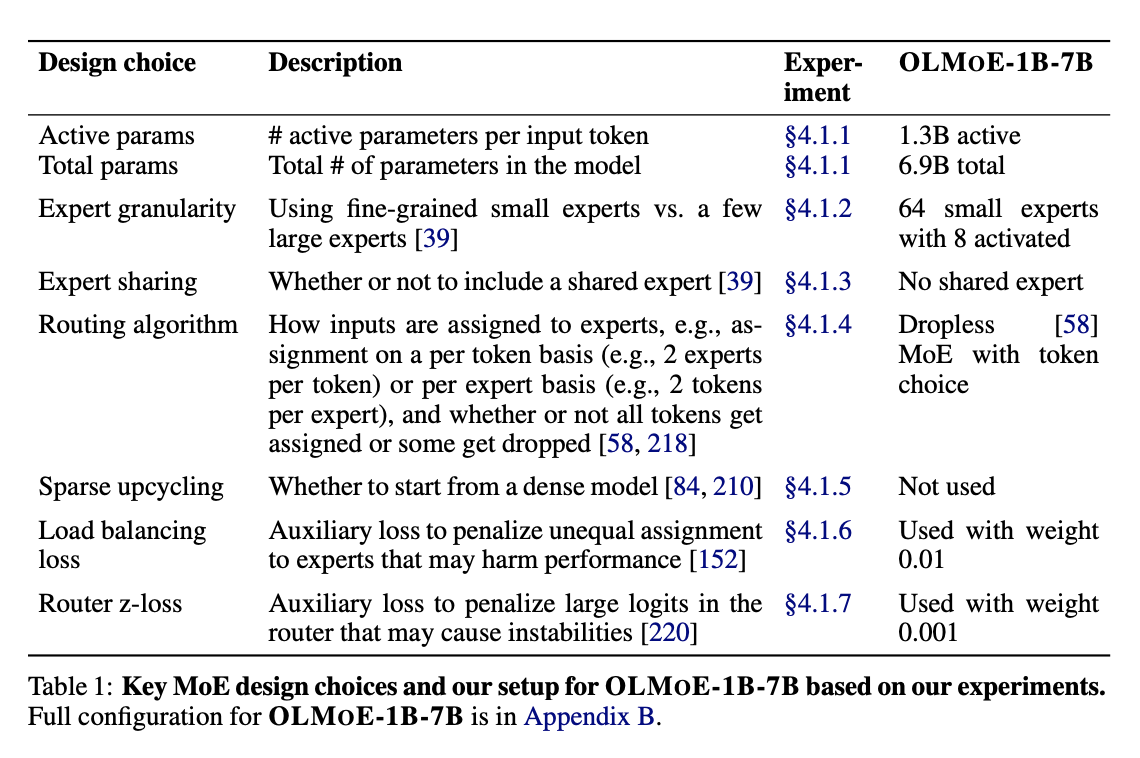
실험 결과
- MoE 의 효과
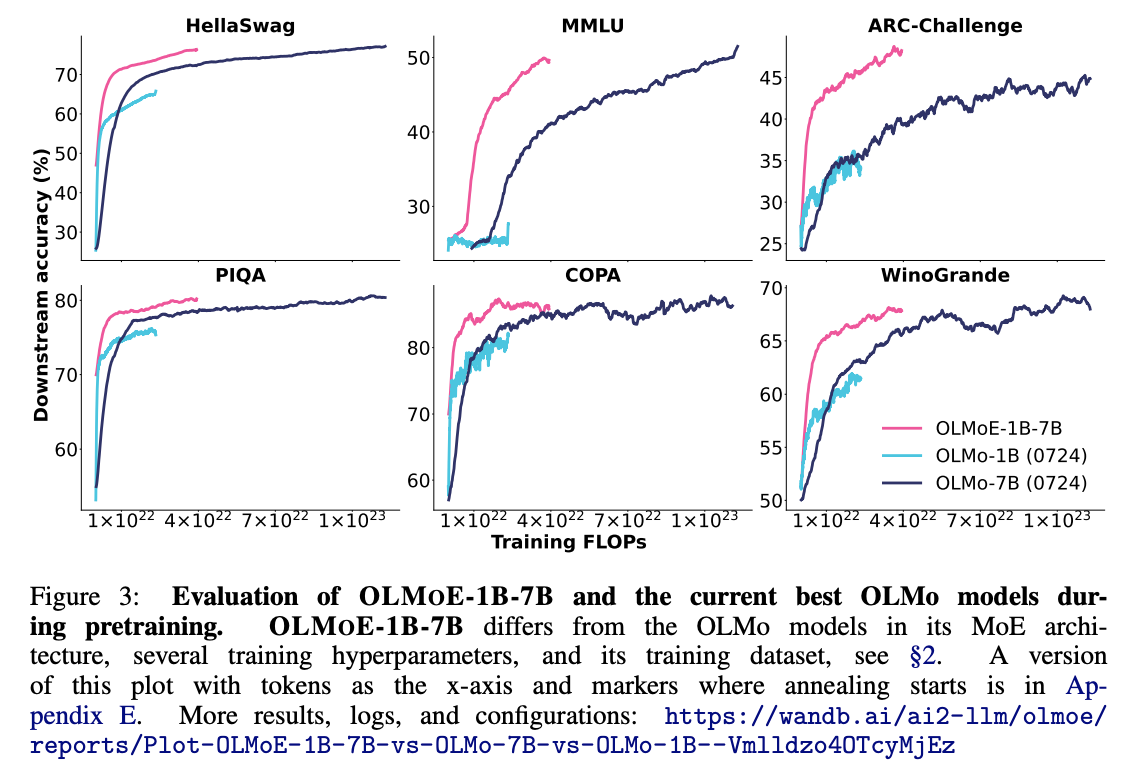
- 타 모델과 비교
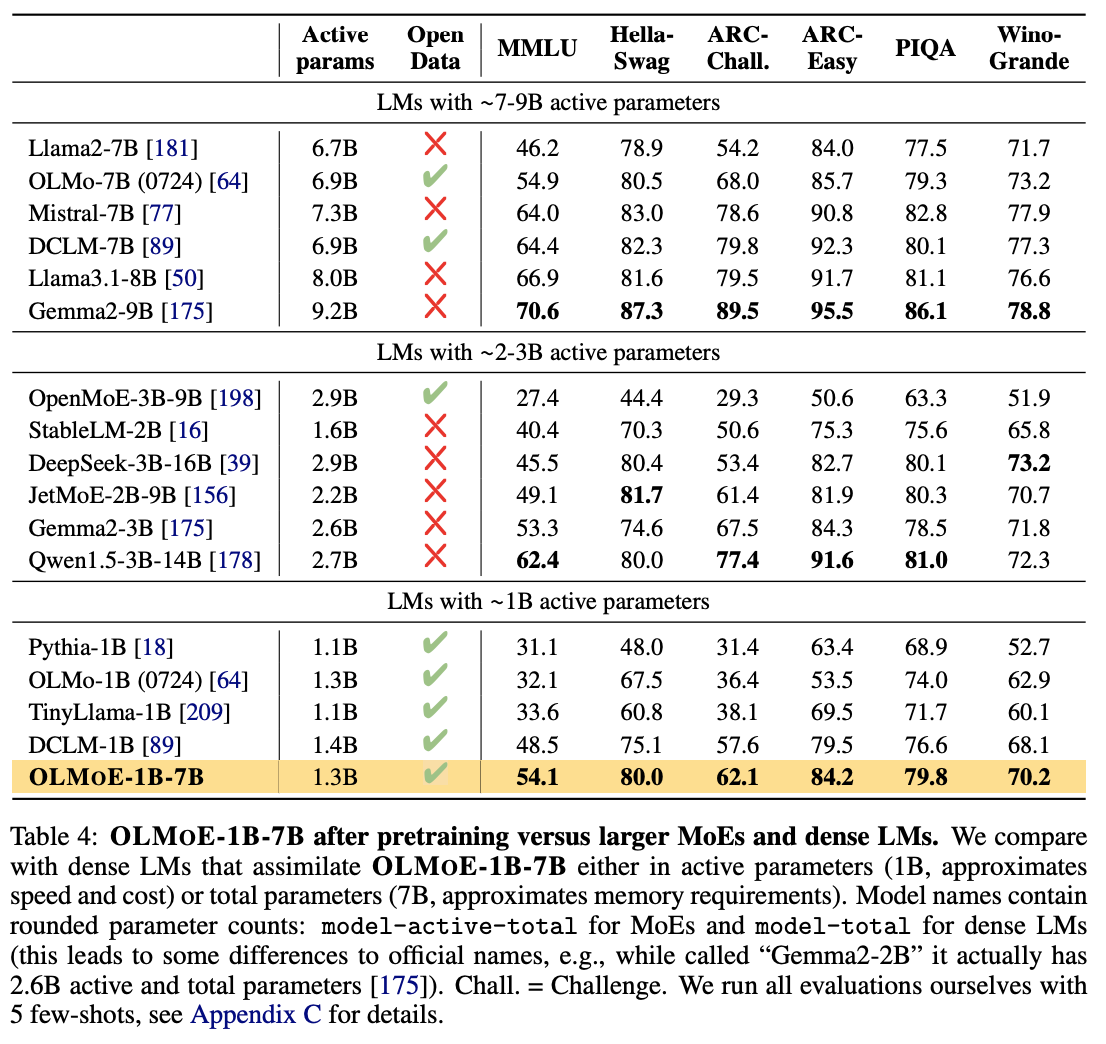
- adaption 효과