(모델 요약) NVIDIA Llama Nemotron (blog)
핵심 내용
- Llama 모델을 SFT 혹은 distill 한 뒤, SFT, RL 학습.
- Nano: 8B finetuned from Llama 3.1 8B
- Super: 49B distilled from Llama 3.3 70B
- Ultra: 253B distilled from Llama 3.1 405B
- 성능은 Llama3.3 70B 보다 나음.
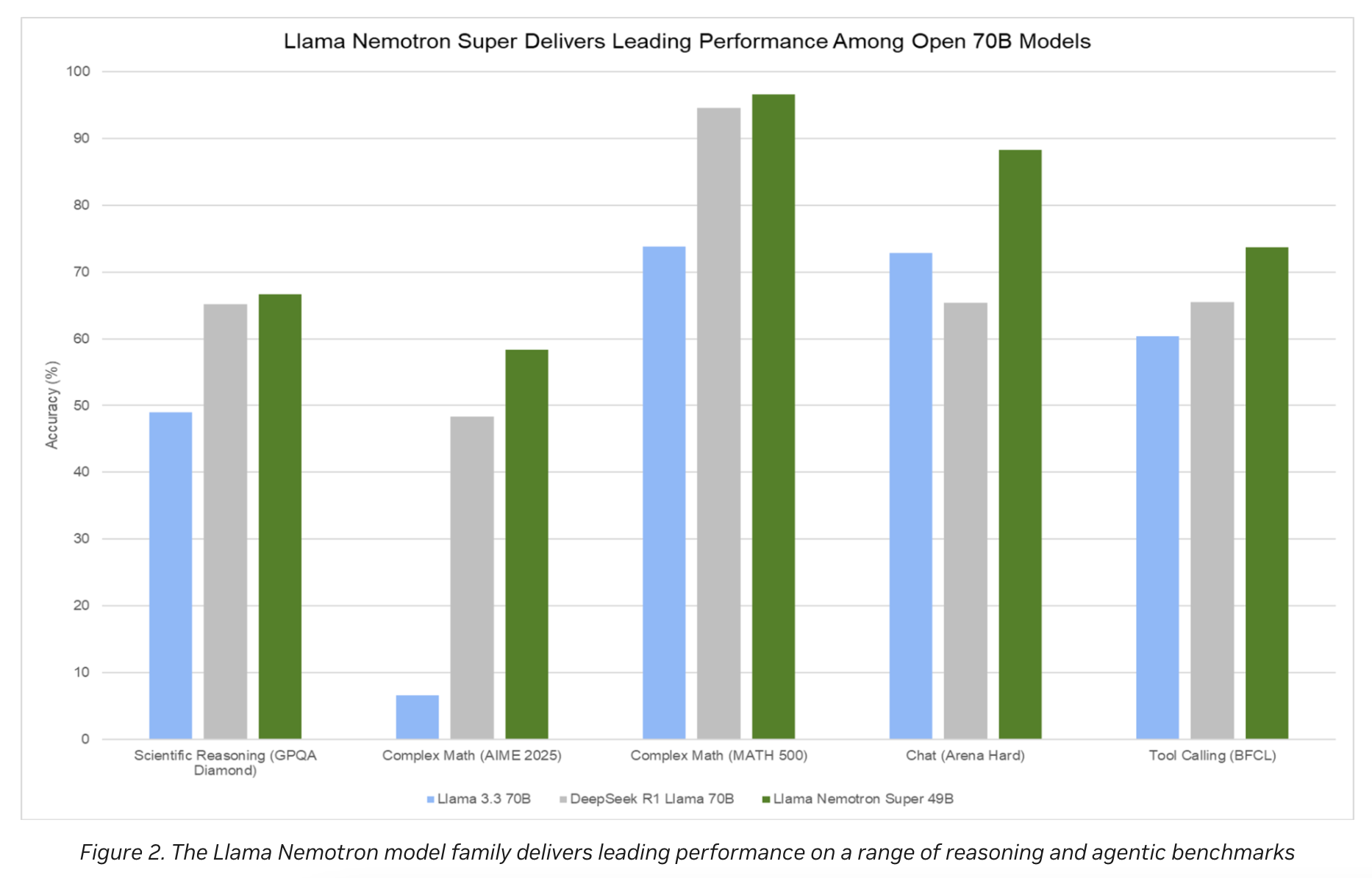
(모델 요약) NVIDIA Llama Nemotron (blog)