(모델 요약) Kimi-K2 (blog) (paper)
핵심 내용
- 모델
- total 1T params, 32B activated params (MoE)
- 학습
- pretrain: 15.5T tokens
- key vector, query vector 를 clip 함
- RL: verifiable rewards (math, coding) + non-verifiable rewards (writing)
- non-verifiable rewards: self-judge (periodic weights update)
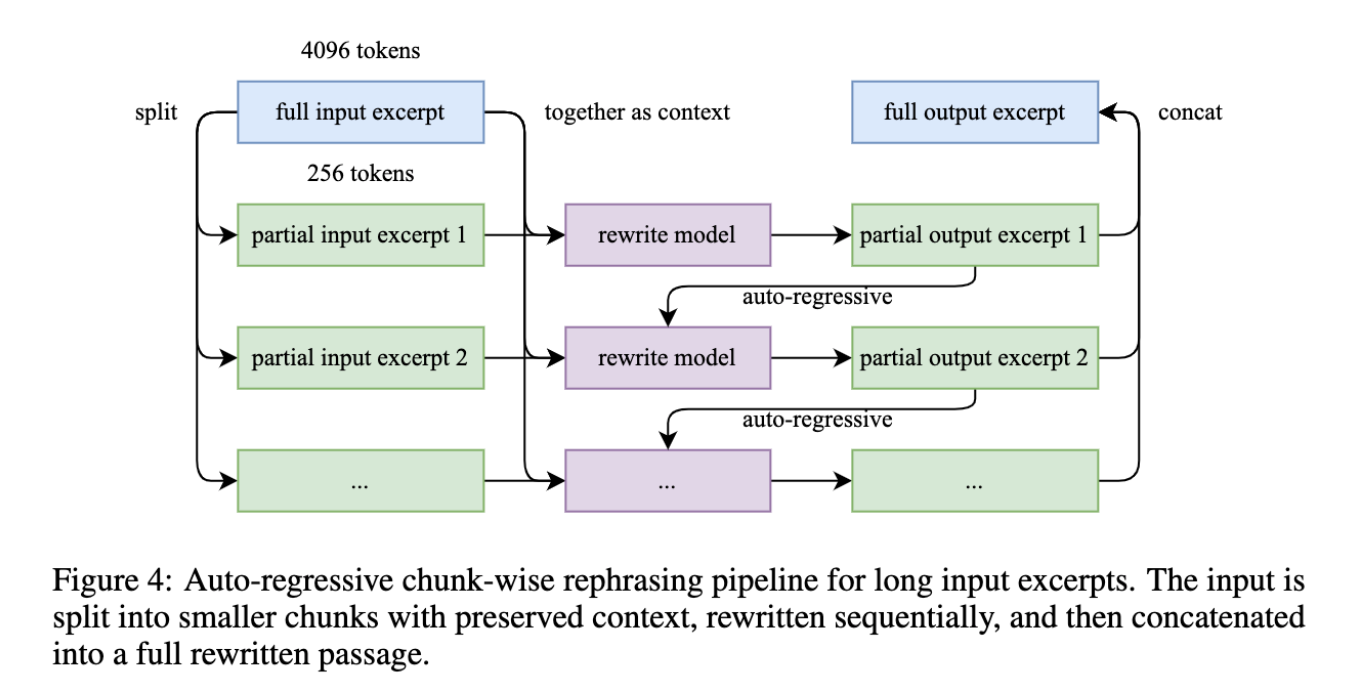
- Pretrain data rephrasing: corpus 를 rephrase 하여 데이터를 다양하게 변형
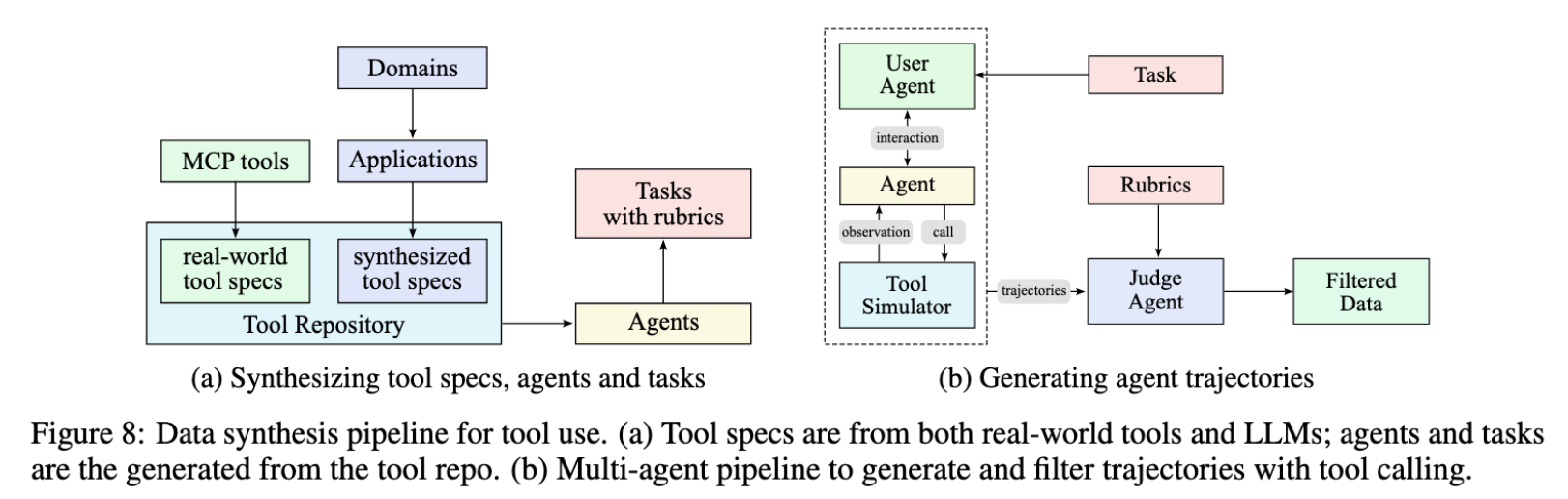
- agent data
- 수천개의 tools, 수백개의 domains 를 ‘evolve’ 했다고 함.
- 다양한 tool set 을 지닌 수백개의 agents 생성.
- simulated environment 에서 agents 가 상호작용.
- task rubic 으로 quality training data 를 선별.