(논문 요약) InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output (Paper)
핵심 내용
- 모델
- vision encoder: CLIP ViT-L-14-490 from IXC2 (increase resolution to 560x560)
- PLoRA 는 image 쪽만 LoRA 를 쓴다는 뜻
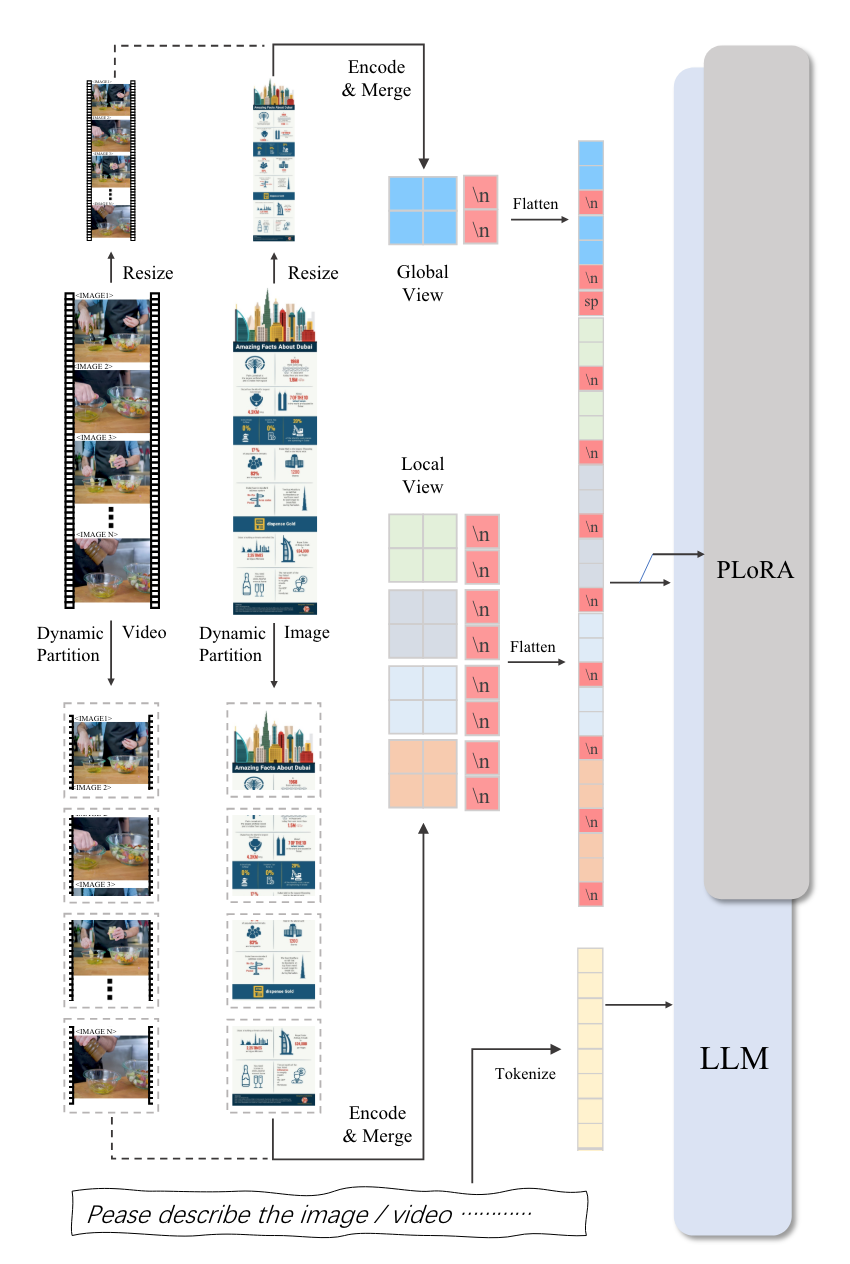
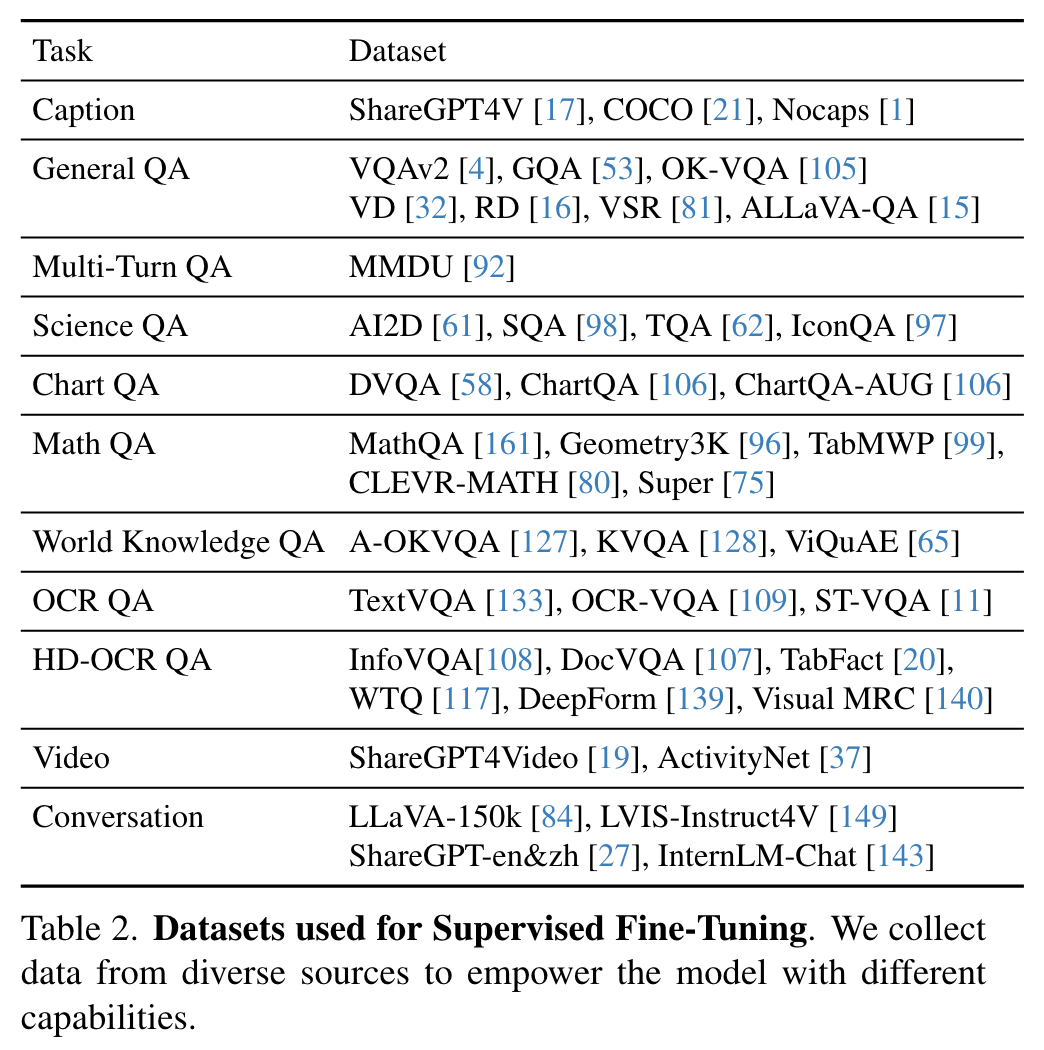
- 데이터: gpt4, claude 등의 모델을 활용하여 alignment 데이터 생성

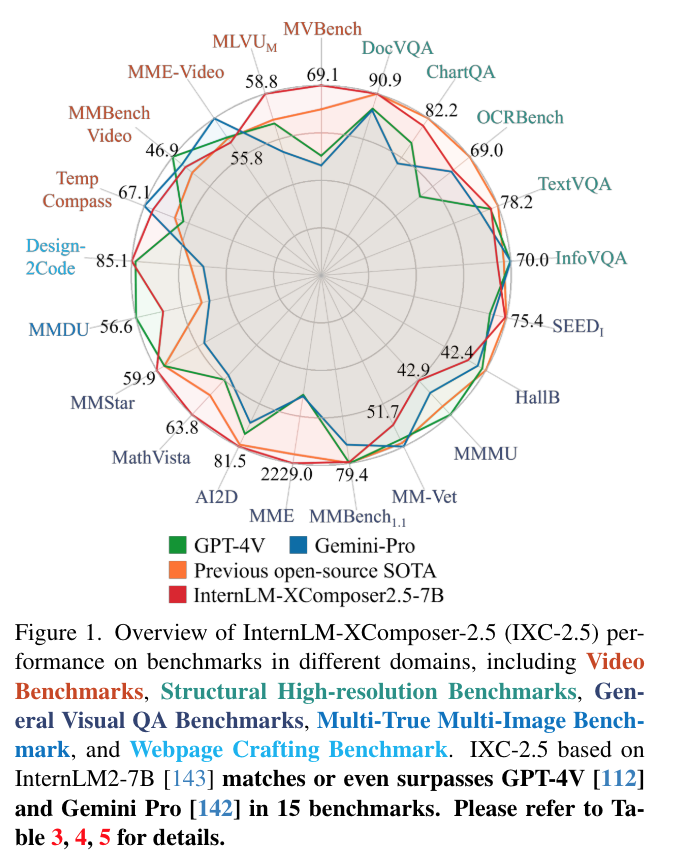
실험 결과
- benchmark 에서 gpt4v 와 비슷