(논문 요약) Gemma 3 Technical Report (Paper)
핵심 내용
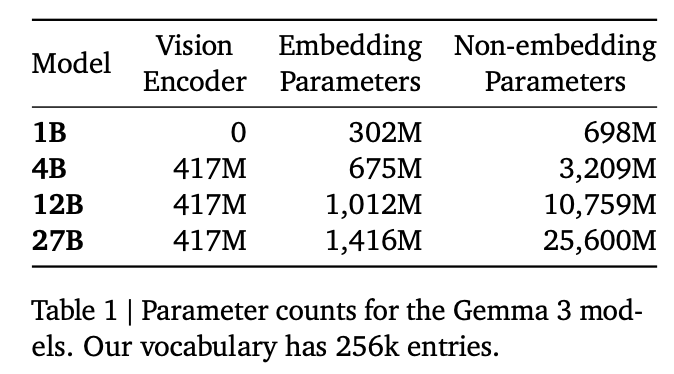
모델 파라미터
input image size: 896 x 896 (high resolution 의 경우 잘라서 resize)
long context 를 적은 메모리로 처리하기 위해 local attention layer (1024 token attention) 비율을 높임 (1 global for every 5 local layers)
- pretrain data: Gemma 2에서 조금 더 늘림
- 1B: 2T tokens
- 4B: 4T tokens
- 12B: 12T tokens
- 27B: 14T tokens
- multilingual data, monolingual, parallel data 추가
tokenizer: Gemma 2 와 동일 (SentencePiece with split digits, preserved whitespace, and byte-level encodings, vocab size 262k)
- instruction tuning
- 큰 모델에서의 distillation + RL
- RL에서는 다음 reward 를 학습한 뒤, weight averaged model 사용
- human feedback data
- code execution feedback
- R1 스타일 ground-truth rewards (for solving math problems)
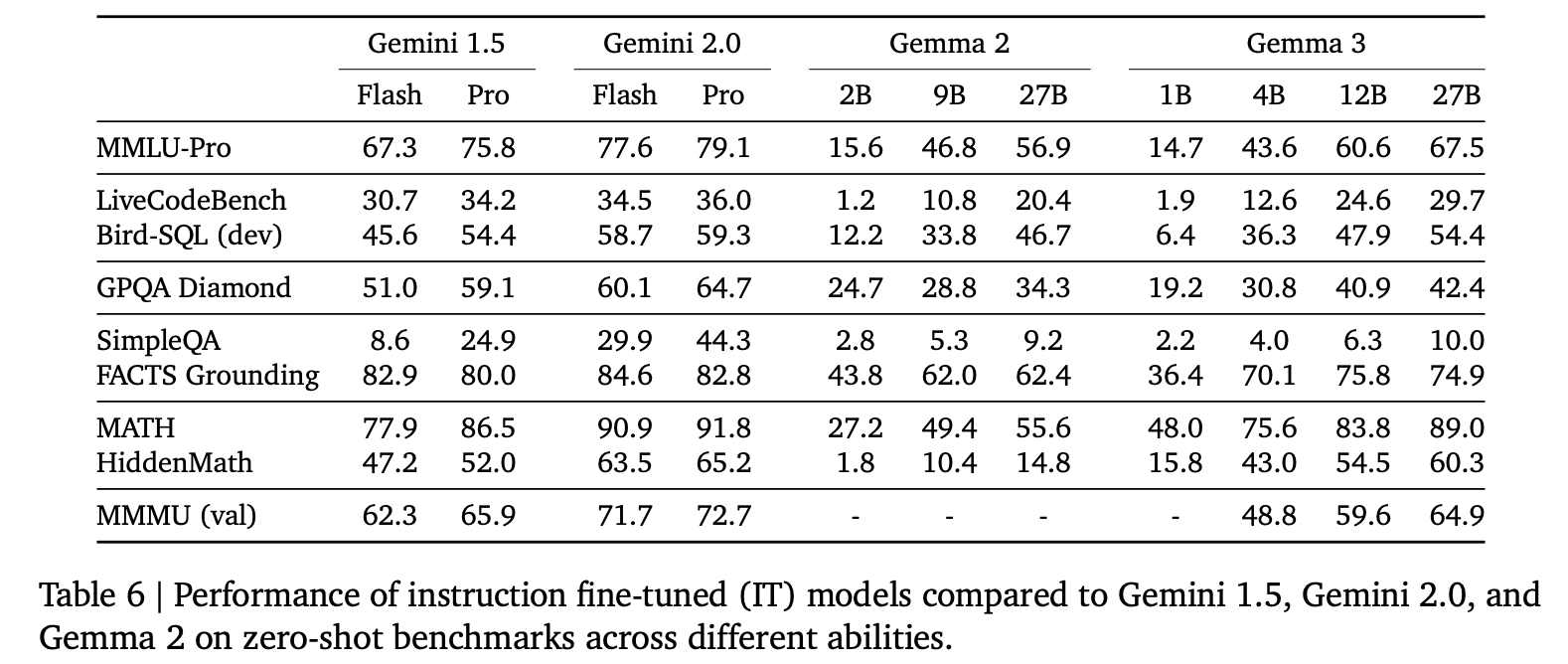
모델 성능
- Gemini 1.5 Pro 와 비슷한 benchmark 성능 존재
- Input image size ablation