(논문 요약) Gemma 2: Improving Open Language Models at a Practical Size (Paper)
핵심 내용
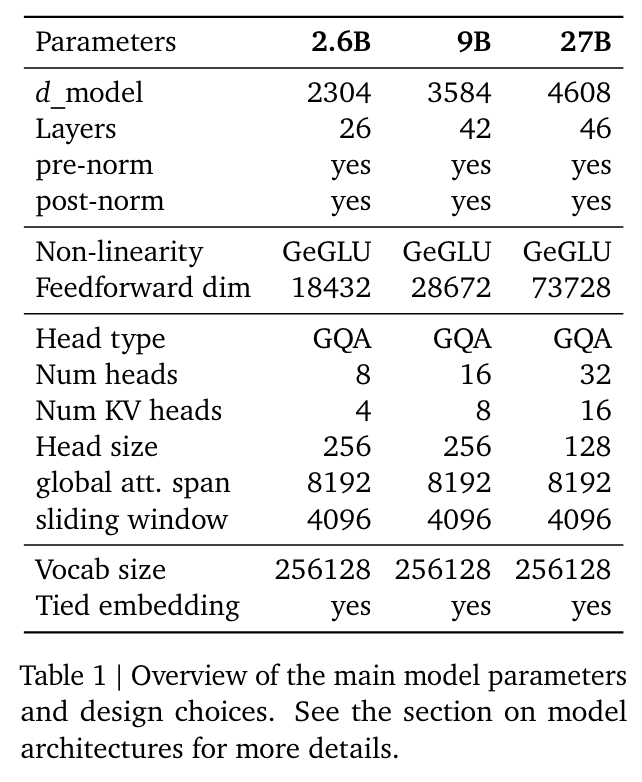
- 아키텍쳐
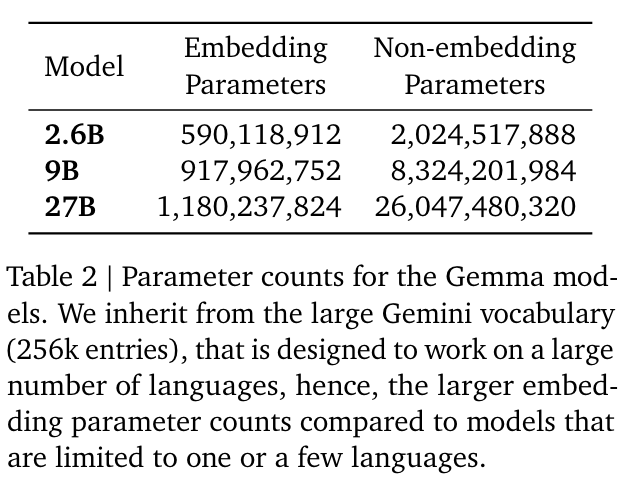
- embedding-related 파라미터가 많음
- training infra
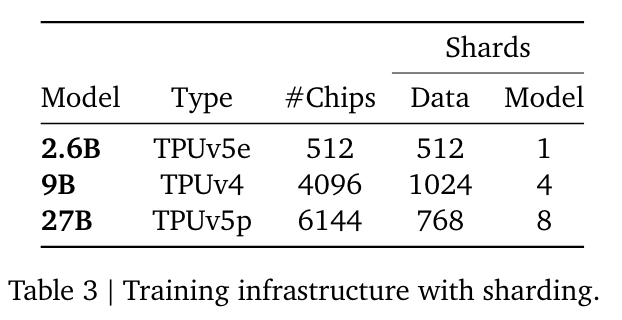
- embedding-related 파라미터가 많음
- 학습 데이터: web documents, code, and science articles 등 다양한 소스에서 발췌
- 27B 모델: 13 trillion tokens of primarily-English data
- 9B 모델: 8 trillion tokens
- 2.6B 모델: 2 trillion tokens
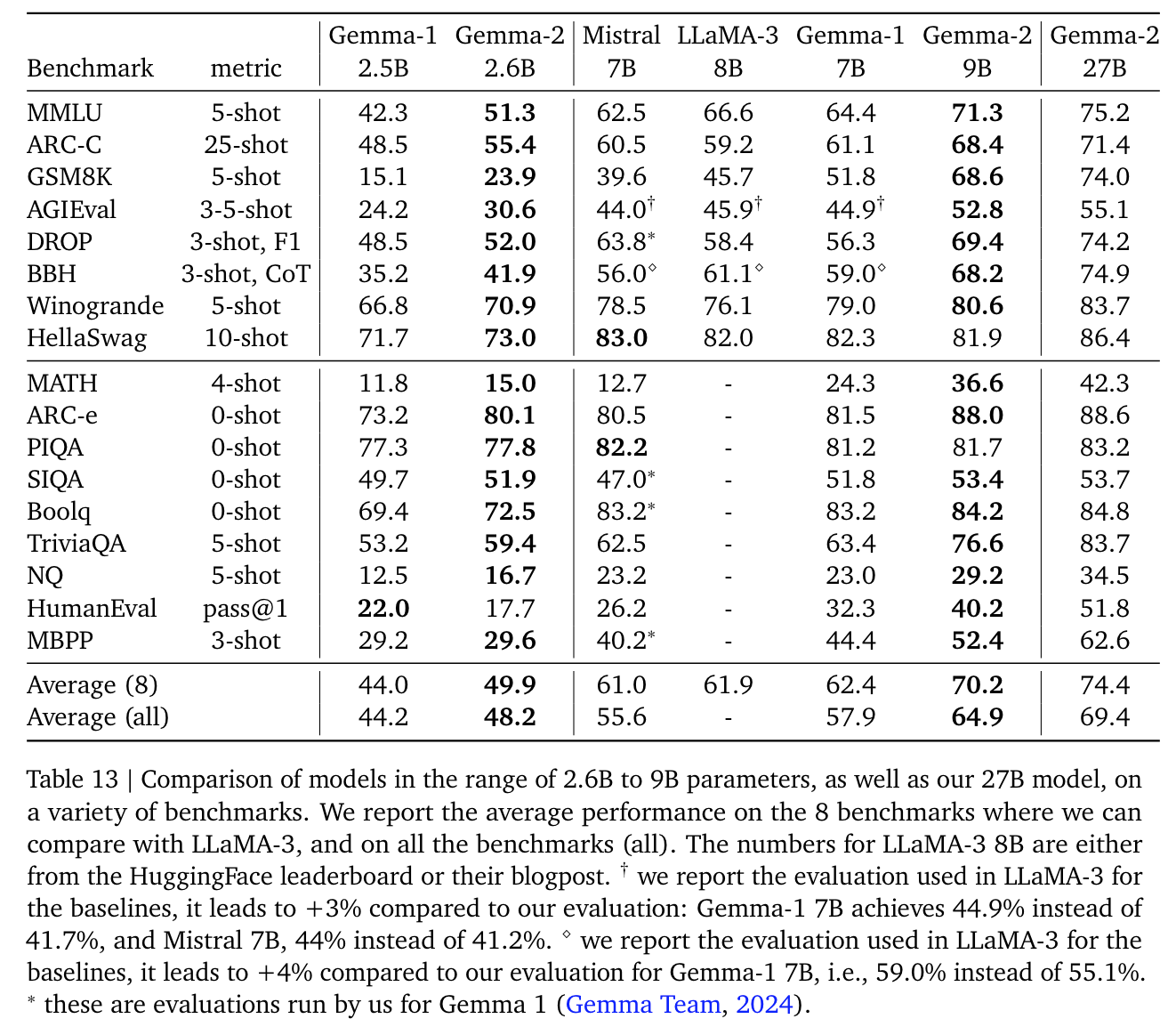
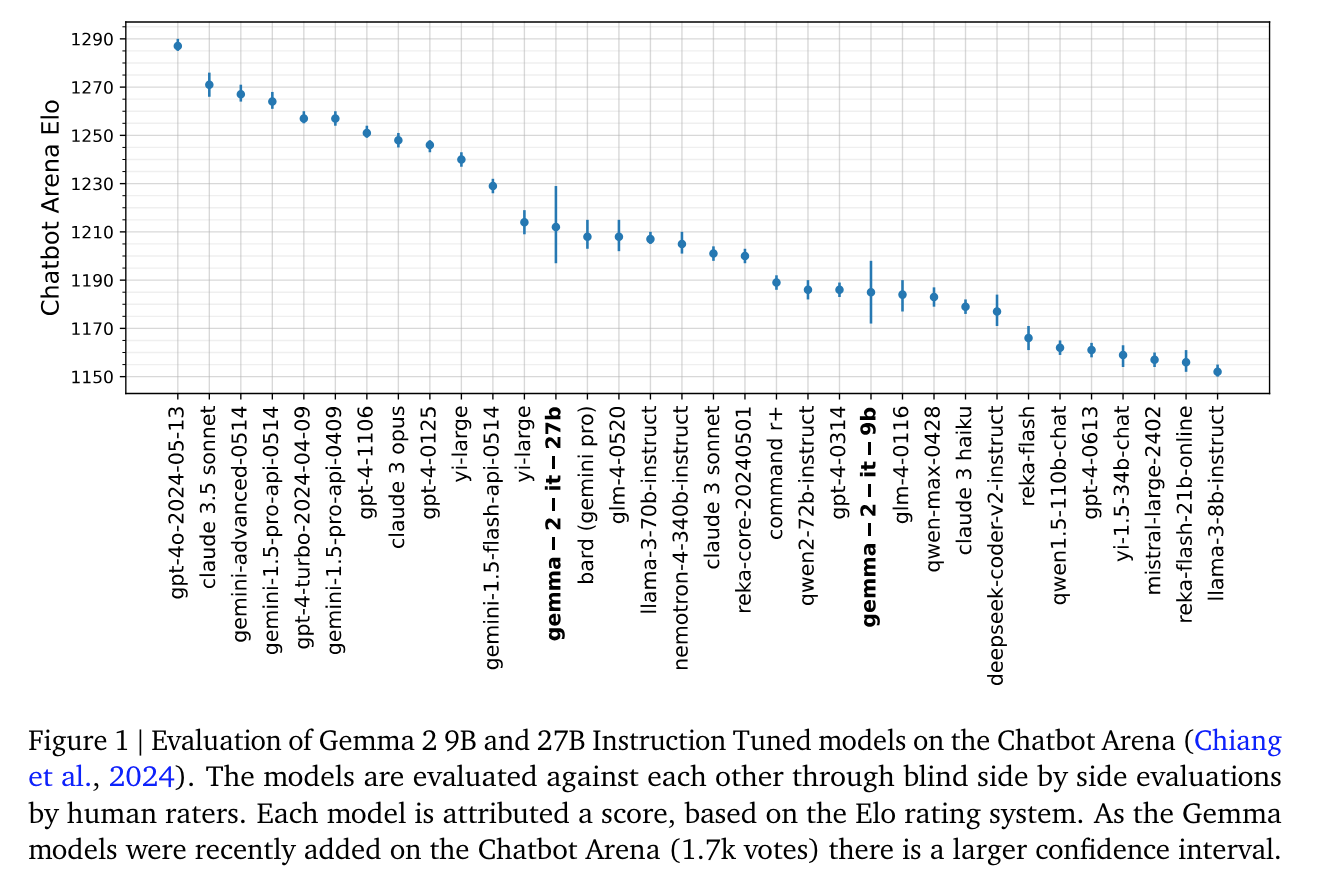
모델 성능