(논문 요약) DeepSeek-V3 Technical Report (paper)
핵심 내용
- 모델: DeepSeek-V2 보다 많은 parameter.
- 671B total, 37B per token (MoE)
- 128k context window
- Byte-level BPE with an extended vocabulary of 128K tokens
- Auxiliary-Loss-Free Load Balancing: expert gating 시, bias term 추가하여 overload 되면 줄이고, underload 되면 값을 늘림.
- 학습: DeepSeek-V2 보다 많은 학습 데이터로 pretrain.
- pretrain: 14.8T tokens (higher ratio of mathematical and programming samples + multilingual coverage beyond English and Chinese)
- SFT, RL 수행
- Decontamination 분석은 없음.
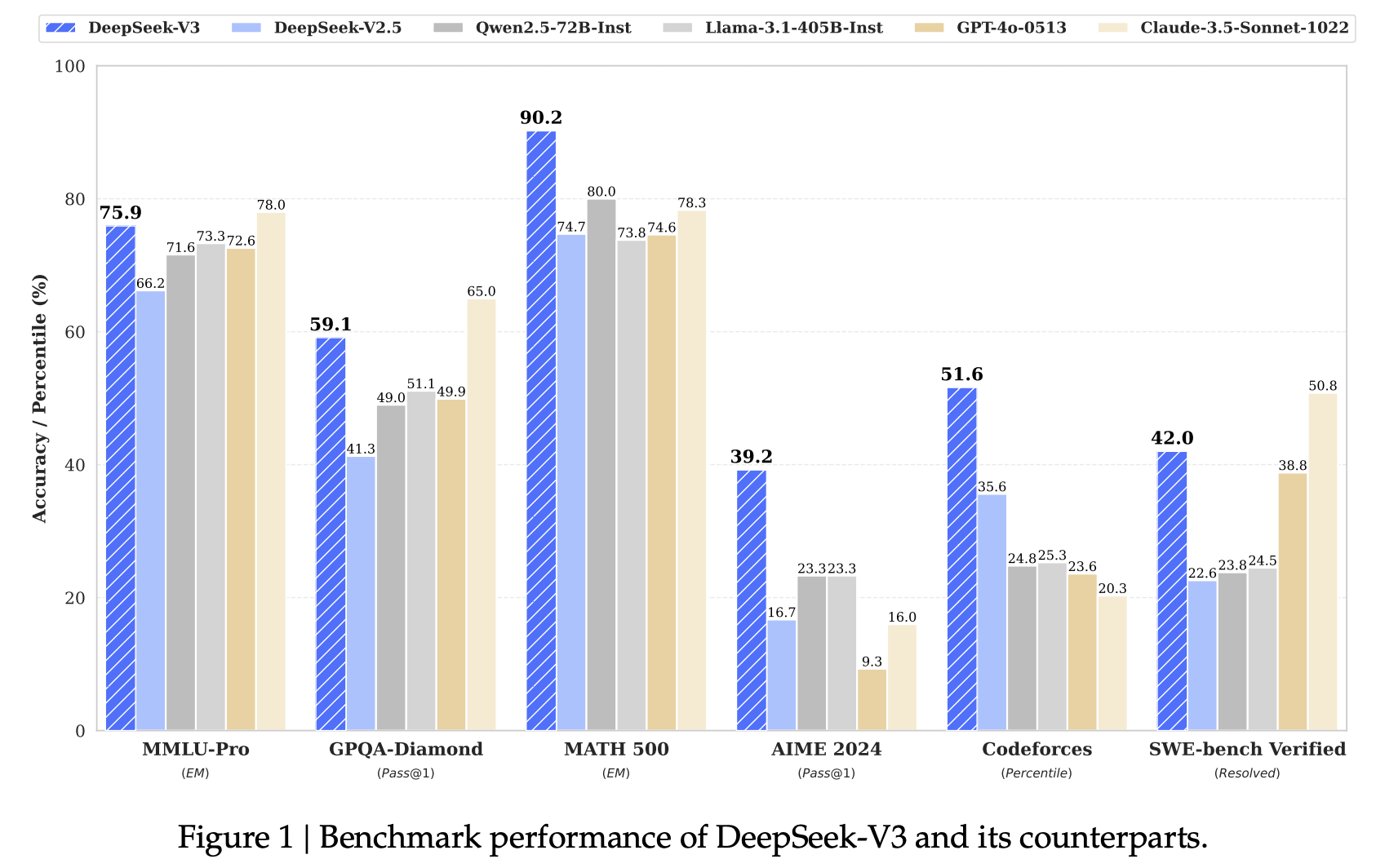
실험 결과
- benchmark 에서 gpt4o 능가.