(논문 요약) DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (paper)
핵심 내용
- 모델
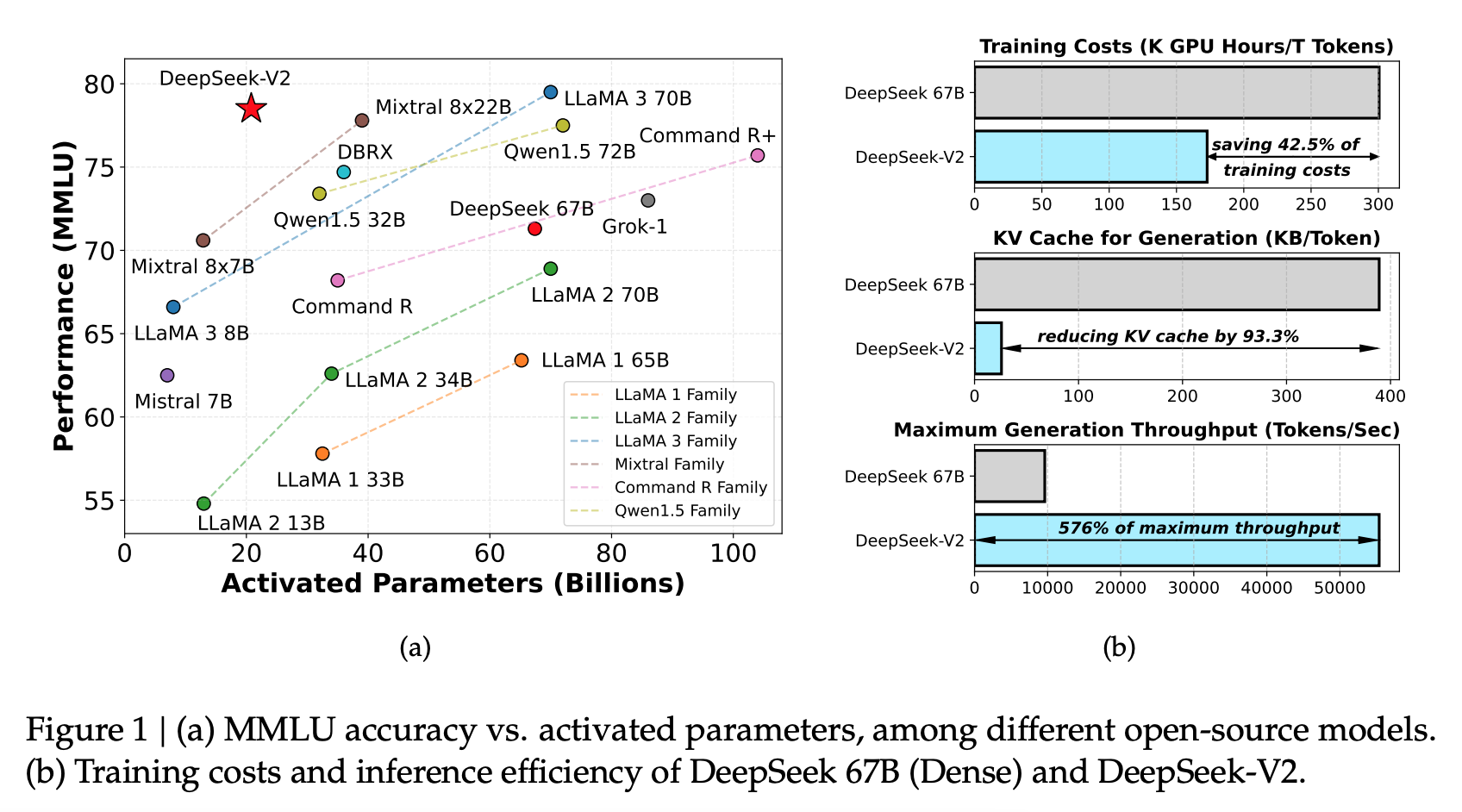
- 236B total, 21B per token (MoE)
- 128k context window
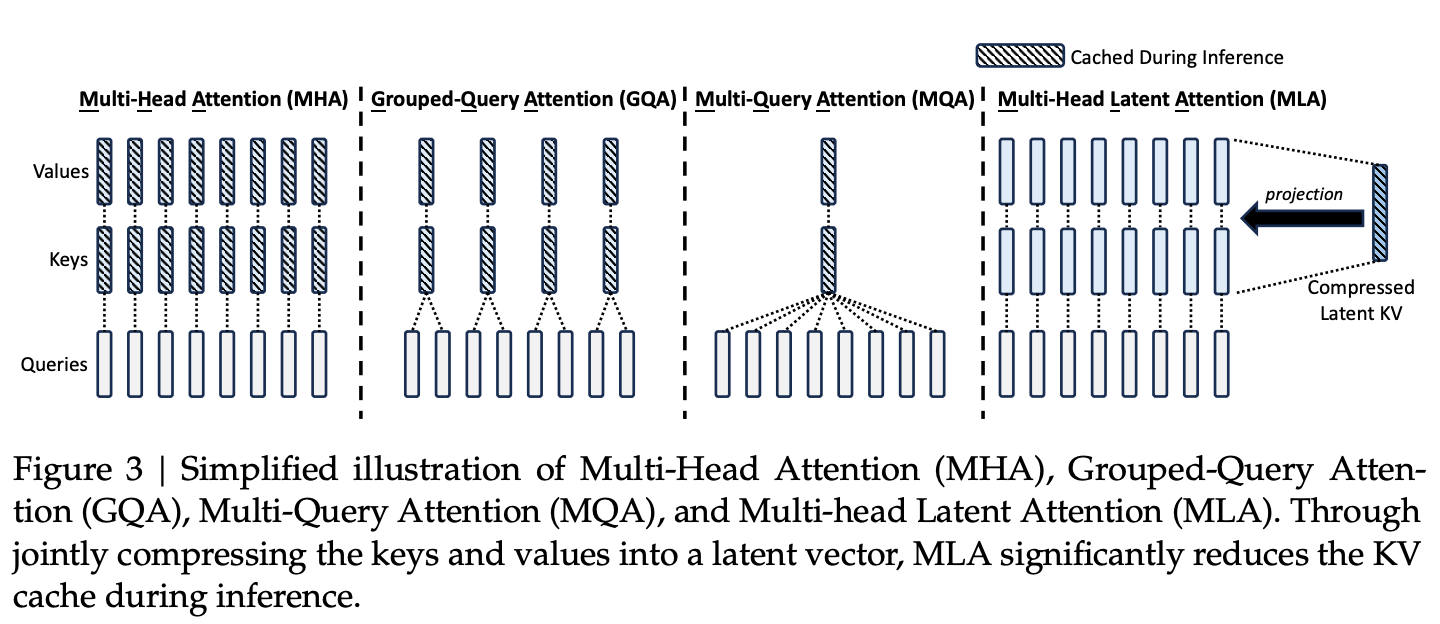
- Multi-head Latent Attention 새로 제안
- 학습
- pretrain: 8.1T tokens
- SFT, RL 수행
architecture
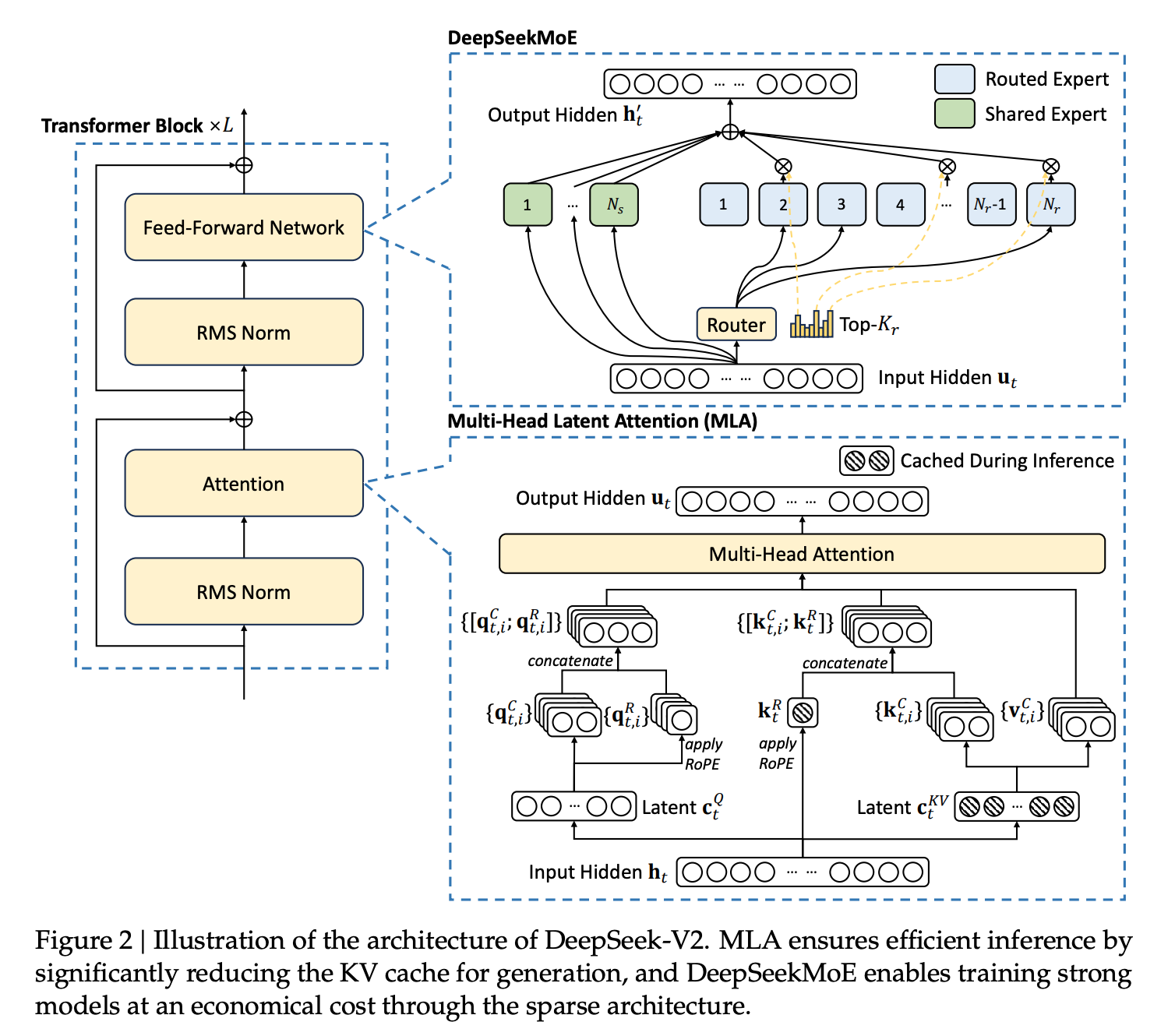
- 데이터: gpt4, claude 등의 모델을 활용하여 alignment 데이터 생성
실험 결과
- benchmark 에서 gpt4v 와 비슷