(논문 요약) Matryoshka Representation Learning (Paper)
핵심 내용
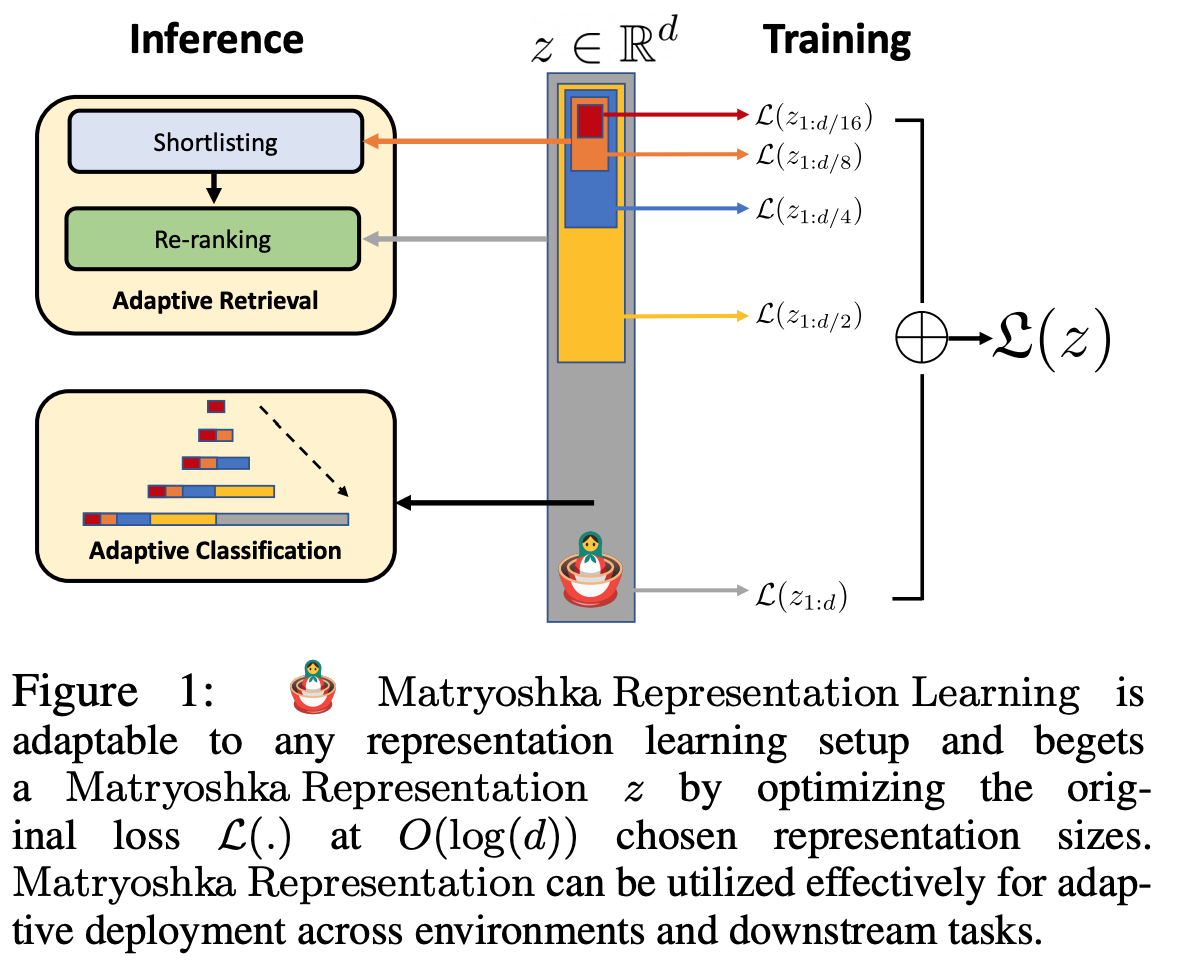
다양한 길이의 feature 를 활용.
Risk minimization loss
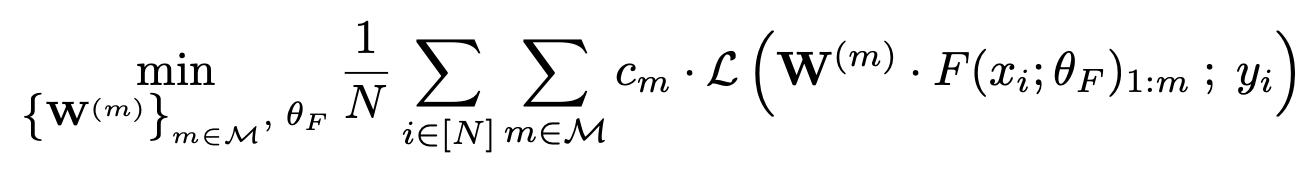
- $F(x_i;\theta_F)$: 네트워크 feature
- {($x_1,y_1$),…,($x_N,y_N$)}: 총 $N$ 개의 (input, label)
- Feature dimension 이 2048 인 경우, $\mathcal{M}$={8, 16, …, 1024, 2048}
- Network weight 와 linear weights 를 동시에 학습.
- 실험에서는 $c_m=1$ 사용.
성능
- 적은 dimension 으로도 좋은 feature 를 뽑을수 있어, 빠른 속도를 낼수 있음.
