(논문 요약) Distributed Inference and Fine-tuning of Large Language Models Over The Internet (Paper)
핵심 내용
- distributed inference
- client: Runs inference or fine-tuning jobs through the swarm of servers. Holds input and output embeddings and delegates running transformer blocks
- server: GPU-enabled node holding a set of consecutive transformer blocks
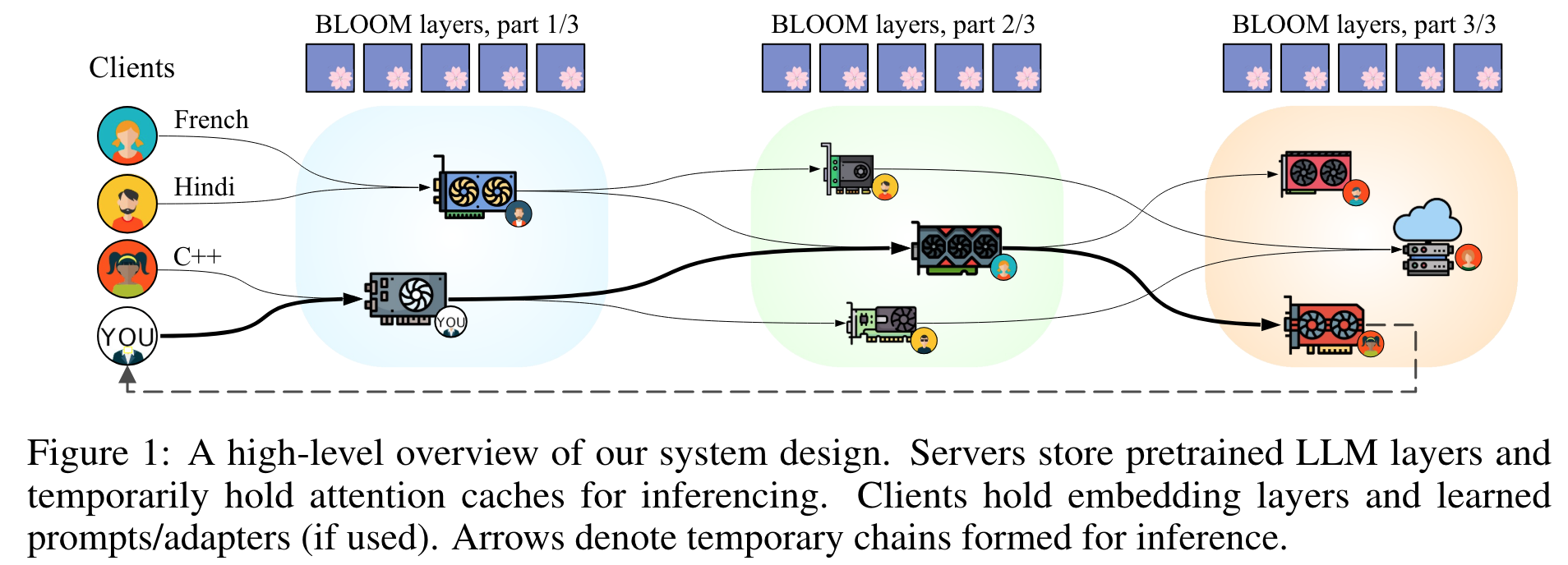
- algorithm

- find_best_chain 은 D* algorithm 으로 실시간 throughput (compute time + network latency) 을 고려하여 계산
실험 결과