(논문 요약) WizardLM: Empowering Large Language Models to Follow Complex Instructions (paper)
핵심 내용
- LLM 으로 Instruction data 생성 (Evol-Instruct)
- 큰 모델 (Chat-GPT) 에 query 하여 instruction 및 response 둘 다 생성
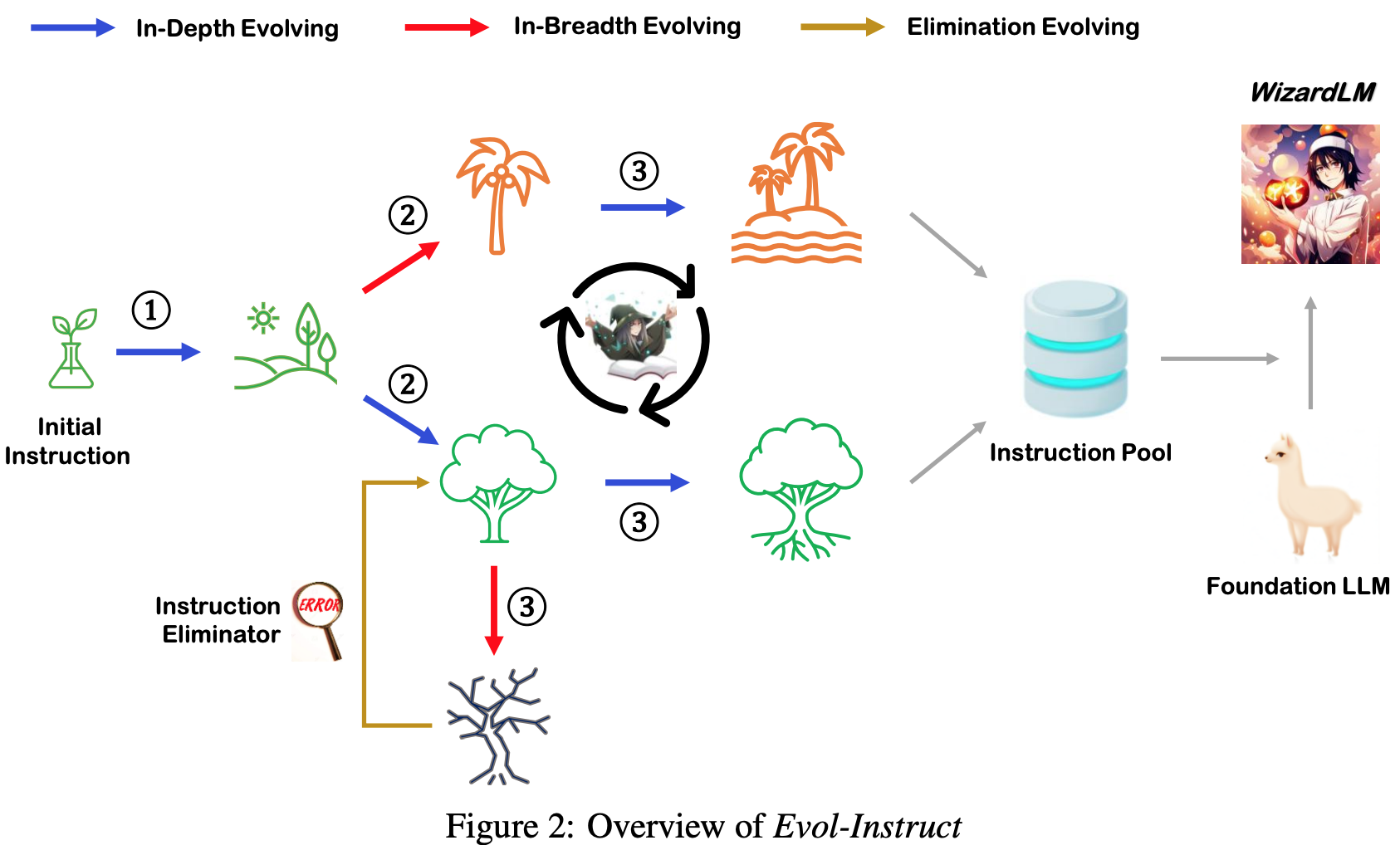
- 방법
- In-Depth Evolving: 조건 추가, 변형
- In-Breadth Evolving: topic 및 skill 추가
- Elimination Evolving: low-quality instructions 제거
- Initial Instruction: Alpaca 의 52K Instructions
- 총 4번의 사이클 수행
- 최종적으로 250K 의 Instructions 수집
Prompts
- In-Depth Evolving
- 조건 추가

- 형식 변형 (xml -> html)

- 구체적으로 변형 (1+1 을 사과 1개+바나나 1개=과일 2개)

- 조건 추가
- In-Breadth Evolving

Elimination Evolving
- Chat-GPT 에 물어서, seed instruction 과 modified instruction 이 차이가 없으면, modified instruction 제외
- modified instruction 을 Chat-GPT 에 물었을때 답변이 “Sorry” 를 포함하거나 80 단어 미만이면, modified instruction 제외
- modified instruction 을 Chat-GPT 에 물었을때 답변이 punctuation (e.g. ,.:;), stop words (e.g. the, and, is) 만 존재하면, modified instruction 제외
- modified instruction 에 prompt 에서 카피된 흔적이 있으면 modified instruction 제외 (e.g. #Rewritten Prompt#)
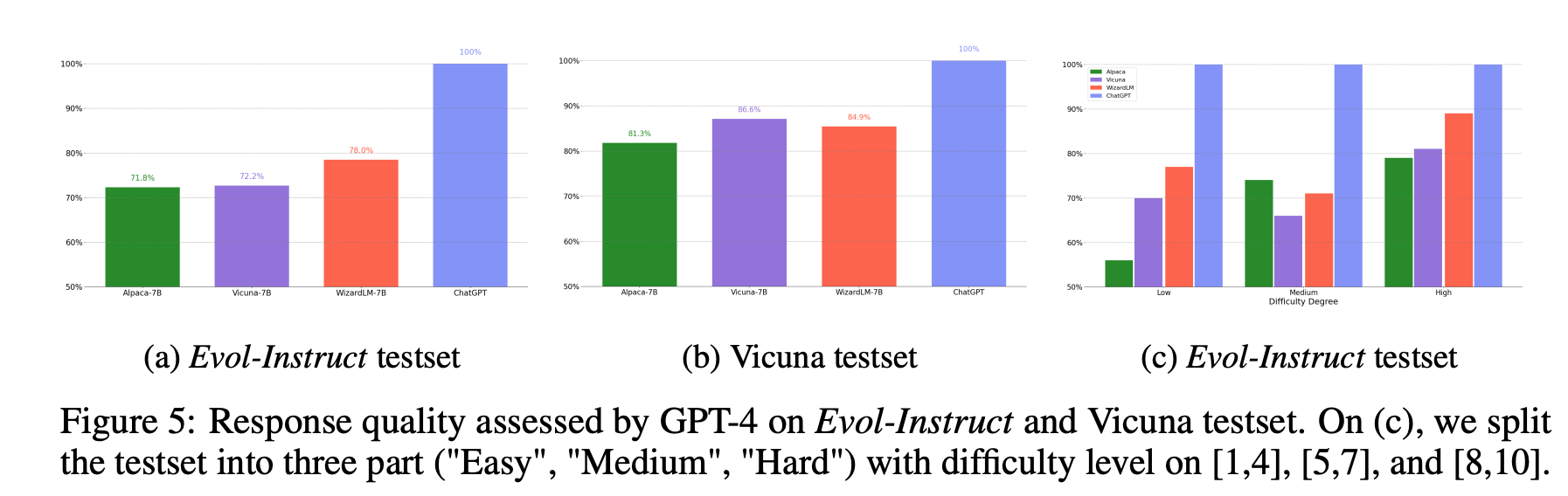
실험 결과
- Alpaca 7B: Llama 7B 에 52K Instructions SFT
- 52K Instruction-answer pairs 는 human-generated (instruction, answer) pairs 175개를 OpenAI text-davinci-003 로 다시 생성
- Vicuna 7B: Llama 7B 에 ShareGPT 의 70K user-shared conversations SFT
- Wizard 7B: Llama 7B 에 250K Evol-Instruct 데이터셋 SFT
- GPT4 로 채점시 높은 점수 받음
(블로그 요약) WizardLM2 (blog)
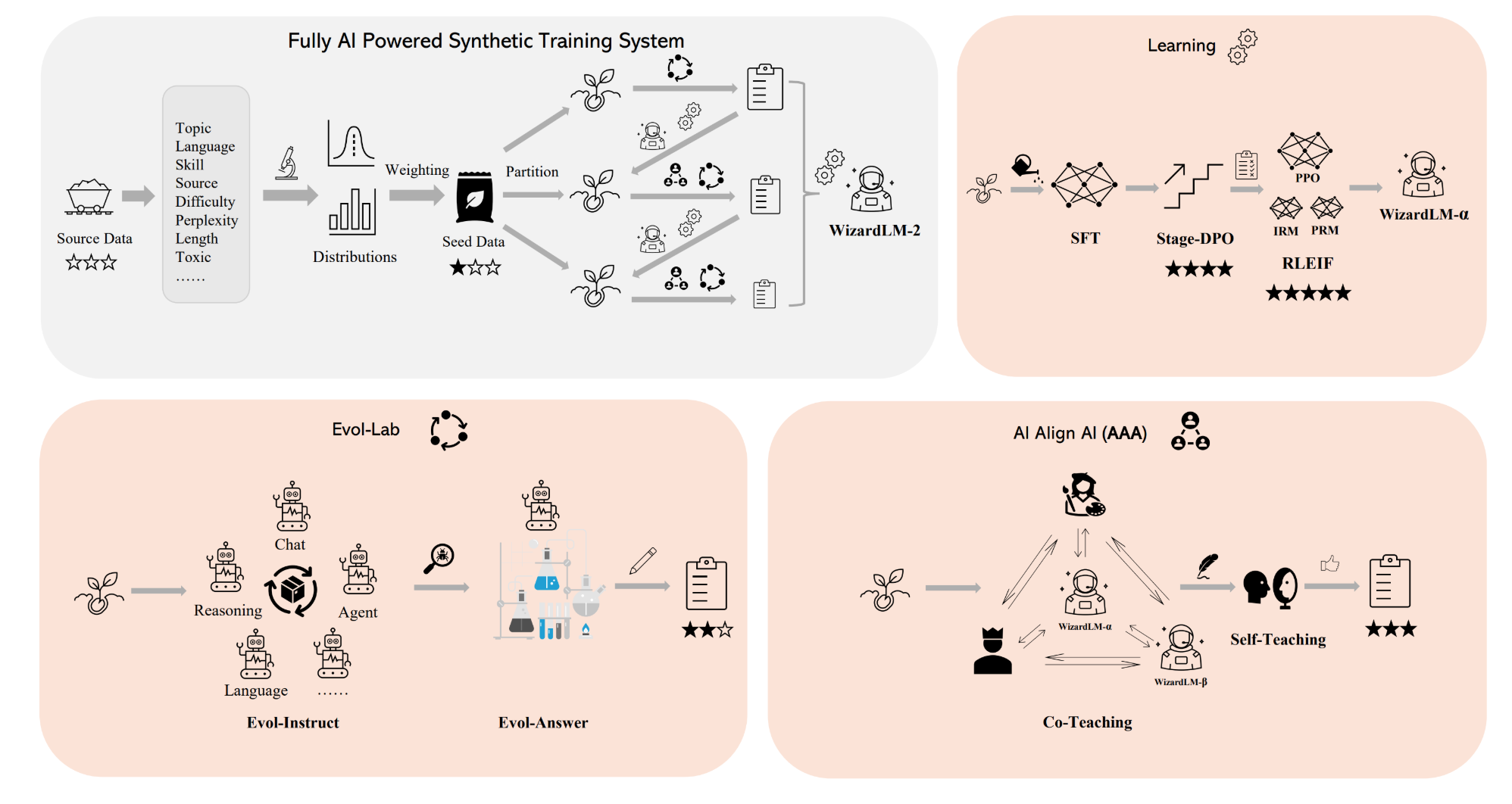
- Preprocessing
- 다양한 attributes 에 대한 distribution 파악
- natural distribution 에 맞게 sampling
- Learning
- SFT
- Stage-DPO: 단계별로 DPO
- RLEIF: Instruction Reward Model + Process Supervision Reward Model 활용하여 PPO
- Evol-lab
- multi-agent 로 instruct 생성
- 여러번 query 하여 response 를 개선
- AI align AI
- Co-teaching: 다양한 모델들로 simulated chat, quality judging, improvement suggestions and closing skill gap, etc
- Self-teaching: 스스로 query 하여 데이터 셋을 생성