(논문 요약) MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens (Paper)
핵심 내용
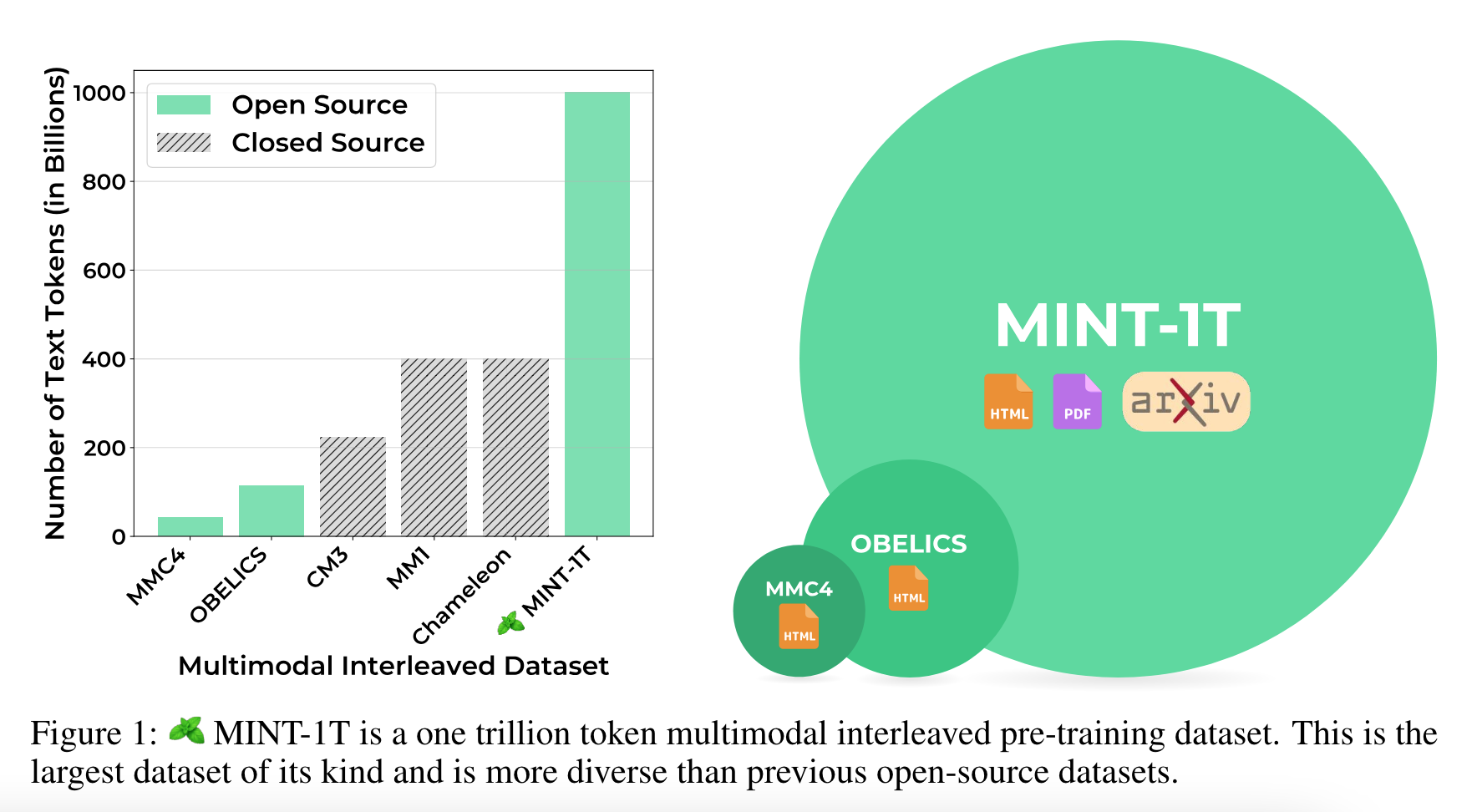
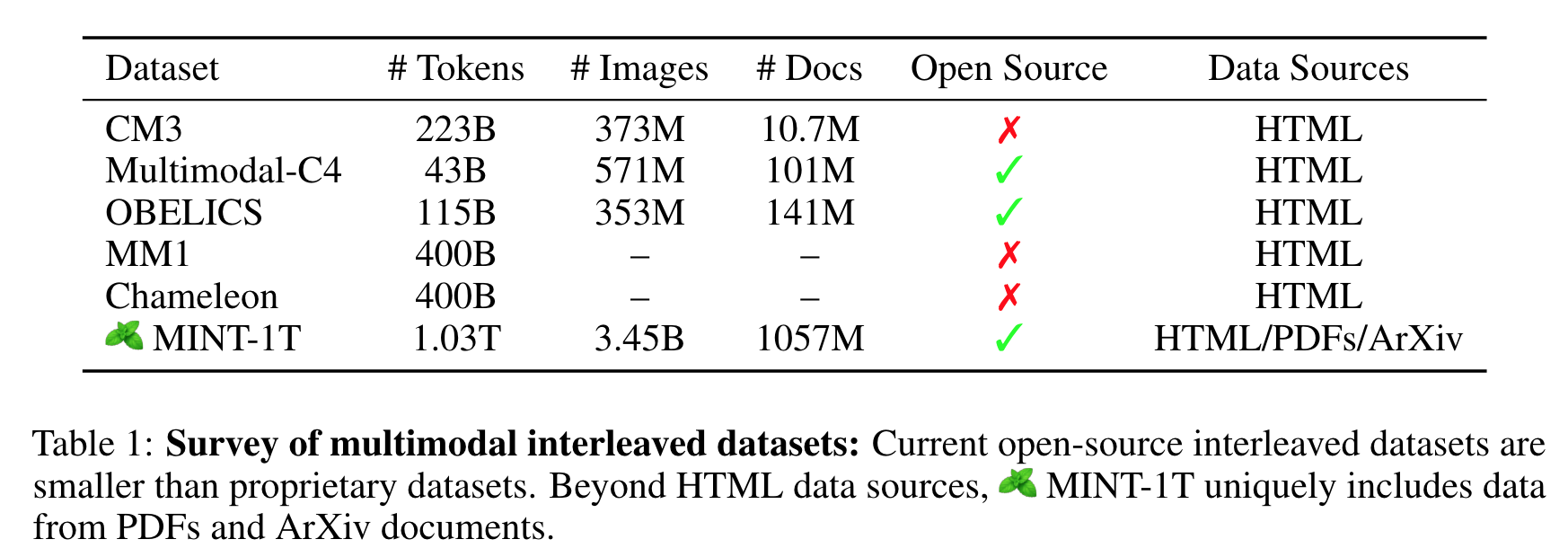
- 1T-tokens + 3.4B images of multimodal-interleaved-datasets

- pipeline
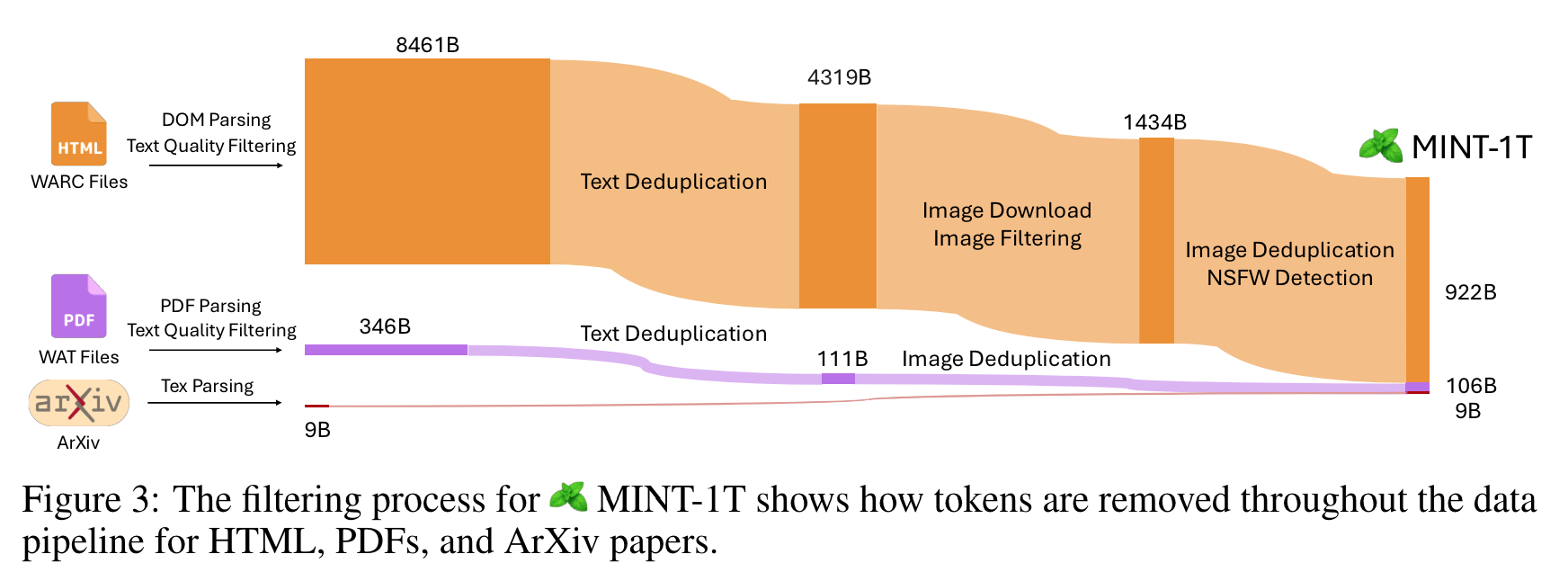
- HTML: Common Crawl WARC dump 추가 (2020.2~2023.2 에서 2017.5~2024.4 로 늘임), 이미지가 없거나, 30개 이상이거나, 이상한 URL (logo, avatar, porn, and xxx) 제거
- PDF: CommonCrawl WAT dump (2023.2~2024.4) 에서 50MB 이상, 혹은 50 pages 이상 문서, 빈 페이지 제거하고, 읽는 순서처리 (단, 논문 Figure 10 과 같이 잘 처리 안되는 경우 존재)
- ArXiv: LaTeX source code 를 filter, deduplication 없이 활용
- Filtering
- Text Quality Filtering: non-English 지우고, RefineWeb 의 방법 사용 (excessive duplicate n-grams, low-quality 제거)
- Image Filtering: broken link 포함 문서, 150 pixel 이하, 20_000 pixel 이상, 특정 aspect ratio (e.g. HTML 에서 2 이상 - 대부분 banner)
- Safety Filtering: NSFW 이미지 포함 문서를, image detector ‘Laborde’ 활용하여 제거
- Deduplication
- Paragraph and Document Deduplication: Bloom filter (FPR 0.01, deduplicate 13-gram) 활용하여 텍스트 제거, 중복 문단이 80% 이상인 경우, 문서 제거
- Removing Common Boilerplate Text: “Skip to content”, “Blog Archive” 등의 문자 제거 (2% 의 CC 데이터에 대해서 deduplication process 적용하여 찾아냄)
- Image Deduplication: SHA256 활용, 하나의 문서에서 중복 없애고, 1개 snapshot 에서 10개 이상 존재하는 이미지 제거
- Infrastructure: ~2,350 CPU cores (190-processor and 90-processor nodes) 로 ~4.2M CPU 시간
실험 결과
- 모델: XGen-MM
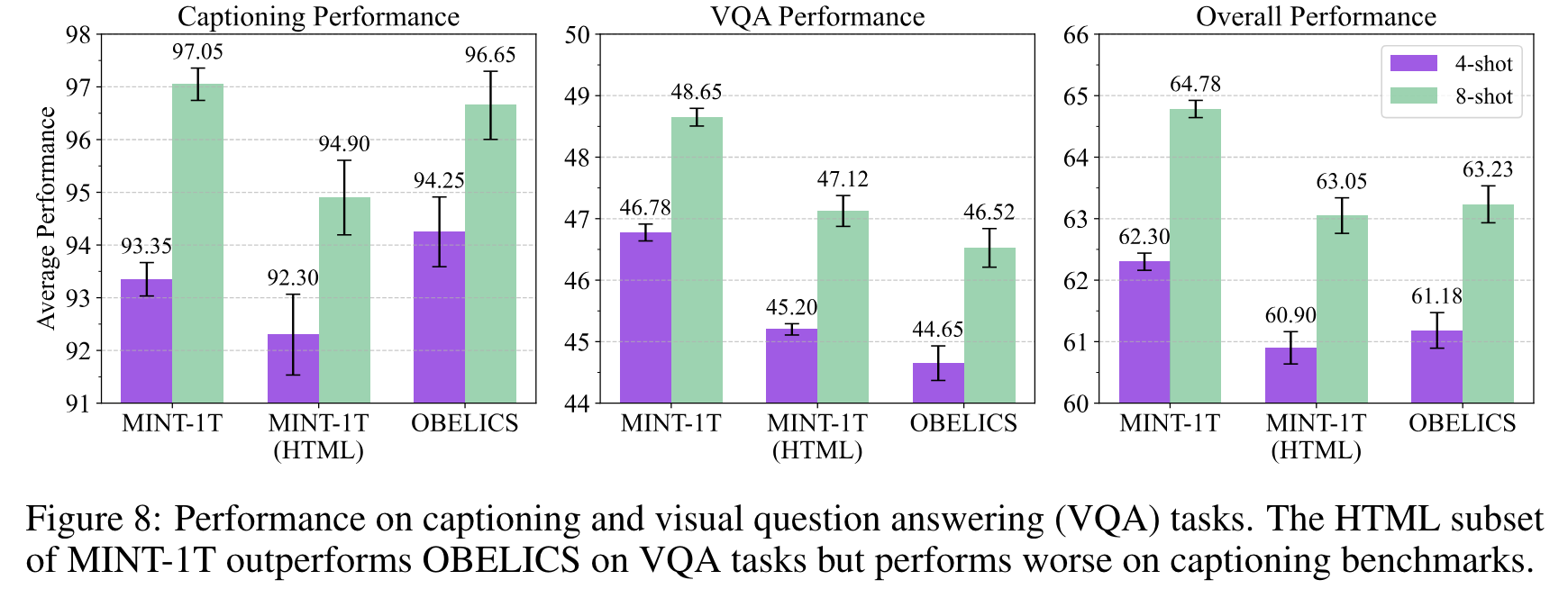
- XGen-MM, Idefics2 를 MINT-1T 에서 HTML 데이터만 가지고 학습했을때 (OBELICS 와 비교)