(논문 요약) Data curation via joint example selection further accelerates multimodal learning (Paper)
핵심 내용
- 주어진 Batch 에서 학습에 효율적인 데이터만 골라서 학습
- 개별 데이터에 대해서 in-batch constrastive loss 를 계산
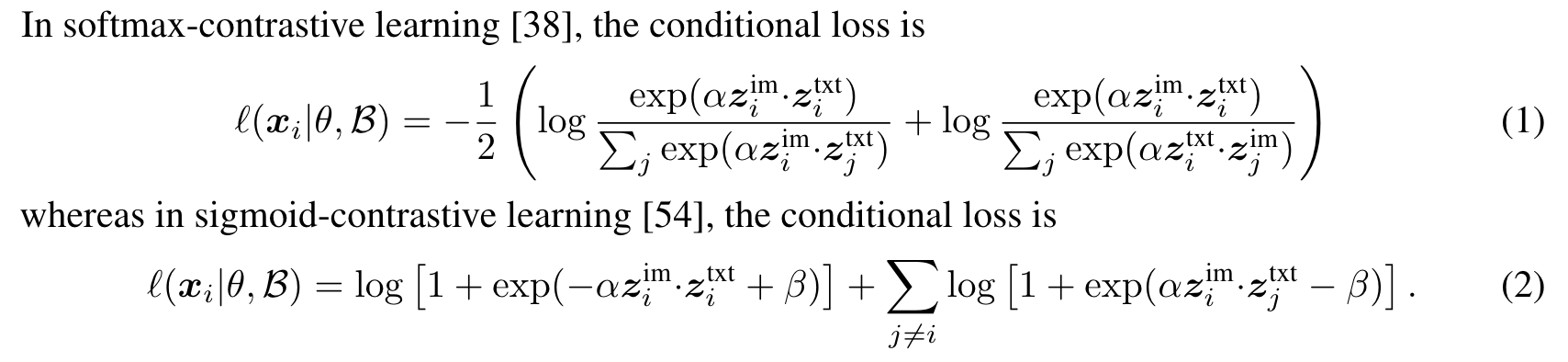
- score 에 비례하여 한번에 n_draws 개를 학습 데이터에 추가. 이를 n_chunks 번 반복
- score (혹은 learnability): learner model loss 가 높을수록, reference model loss 가 낮을수록 높게 설정

- 개별 데이터에 대해서 in-batch constrastive loss 를 계산
- 데이터 셋
- LION 40B 데이터 셋에서 filtering 하는 것으로 생각됨
- WebLI-curated: strongly filtered 100M scale subset from WebLI
- Webli-curated++: WebLI-curated + ~600M additional webscraped image-text pairs
실험 결과
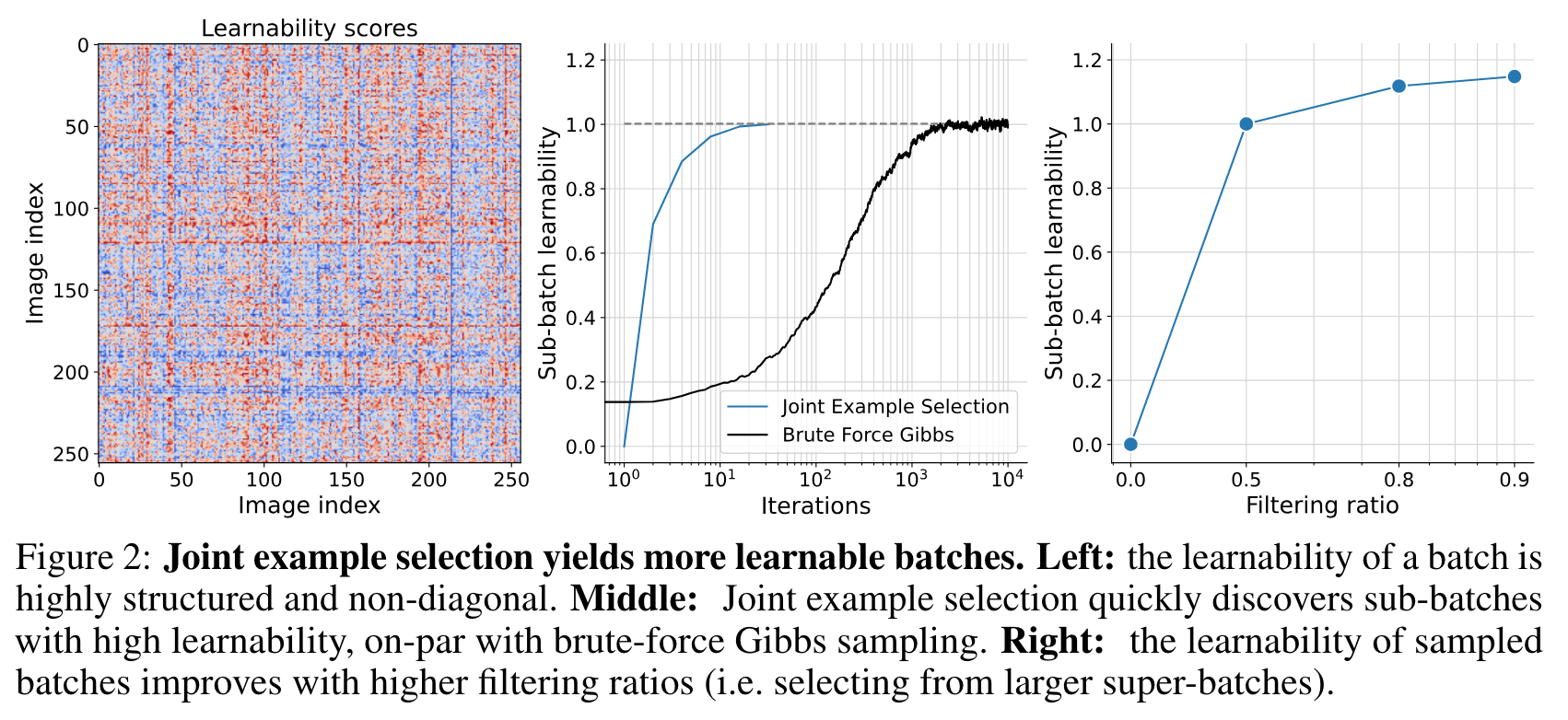
- 맨 오른쪽 subfigure 에서,
- filtering ratio == 0.5 는 65_536 개 데이터중 32_768 개 데이터 선택을 의미
- 0.8 == 32_768/163_840
- 0.9 == 327_680/163_840
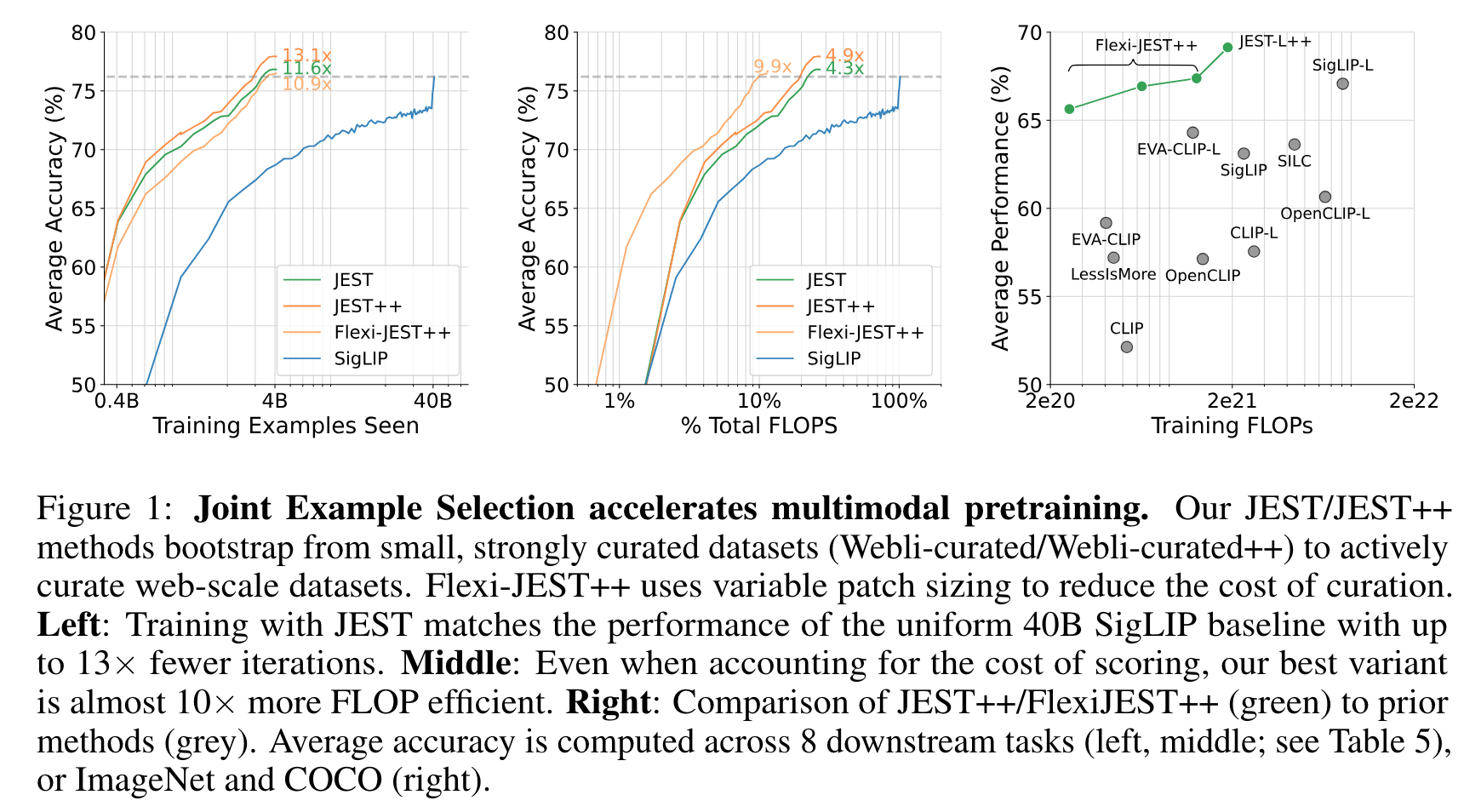
- JEST: WebLI-curated 로 reference 모델 학습
- JEST++: WebLI-curated++ 로 reference 모델 학습
- Flexi-JEST++: JEST++ 에서, 절반 데이터는 ViT 의 patch size 를 늘려서 시간 줄임
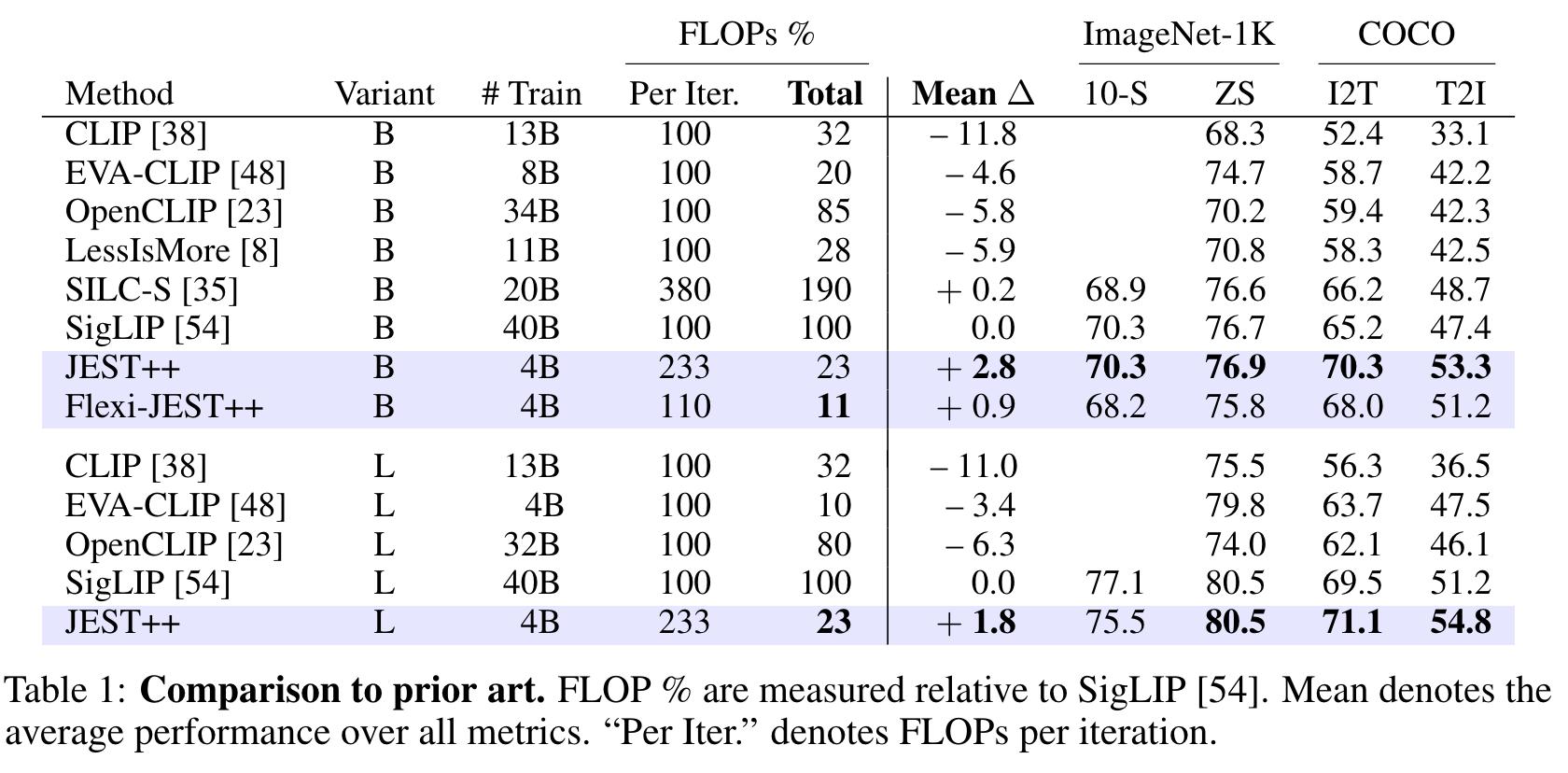
- variant B, L 은 ViT-B, ViT-L 을 의미
