(모델 요약) Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach (Model)
핵심 내용
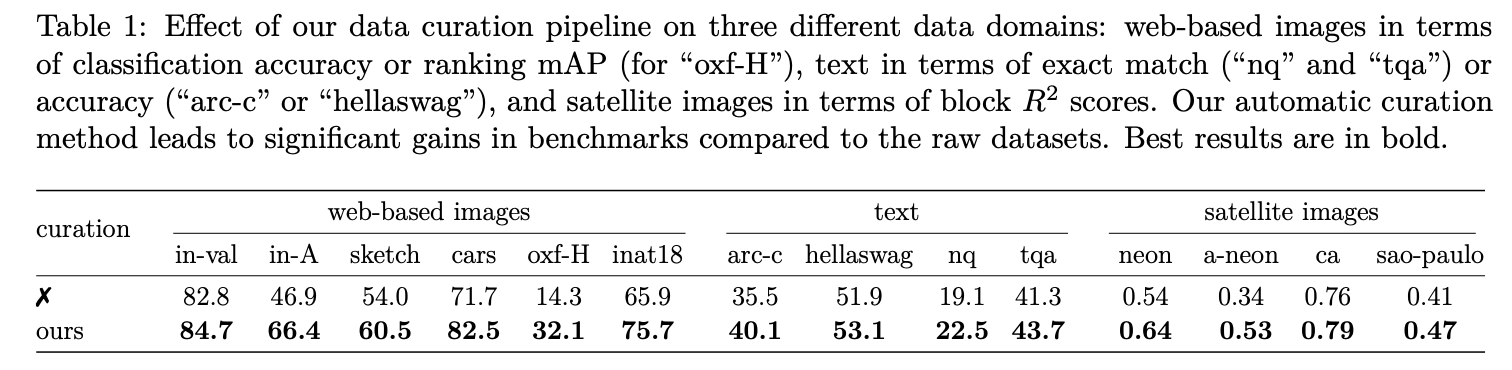
- $k$-means clustring 을 hierarchically 적용하여 data imbalance 를 줄임
- $k$-means centroids 들이 $p^{d/(d+2)}$ 에 비례하게 분포한다는 증명이 존재
- $k$-means 를 $T$ 번 반복하면, $p^{(d/(d+2))^T}$ 에 비례하게 되고, 점점 uniform 에 가까워짐
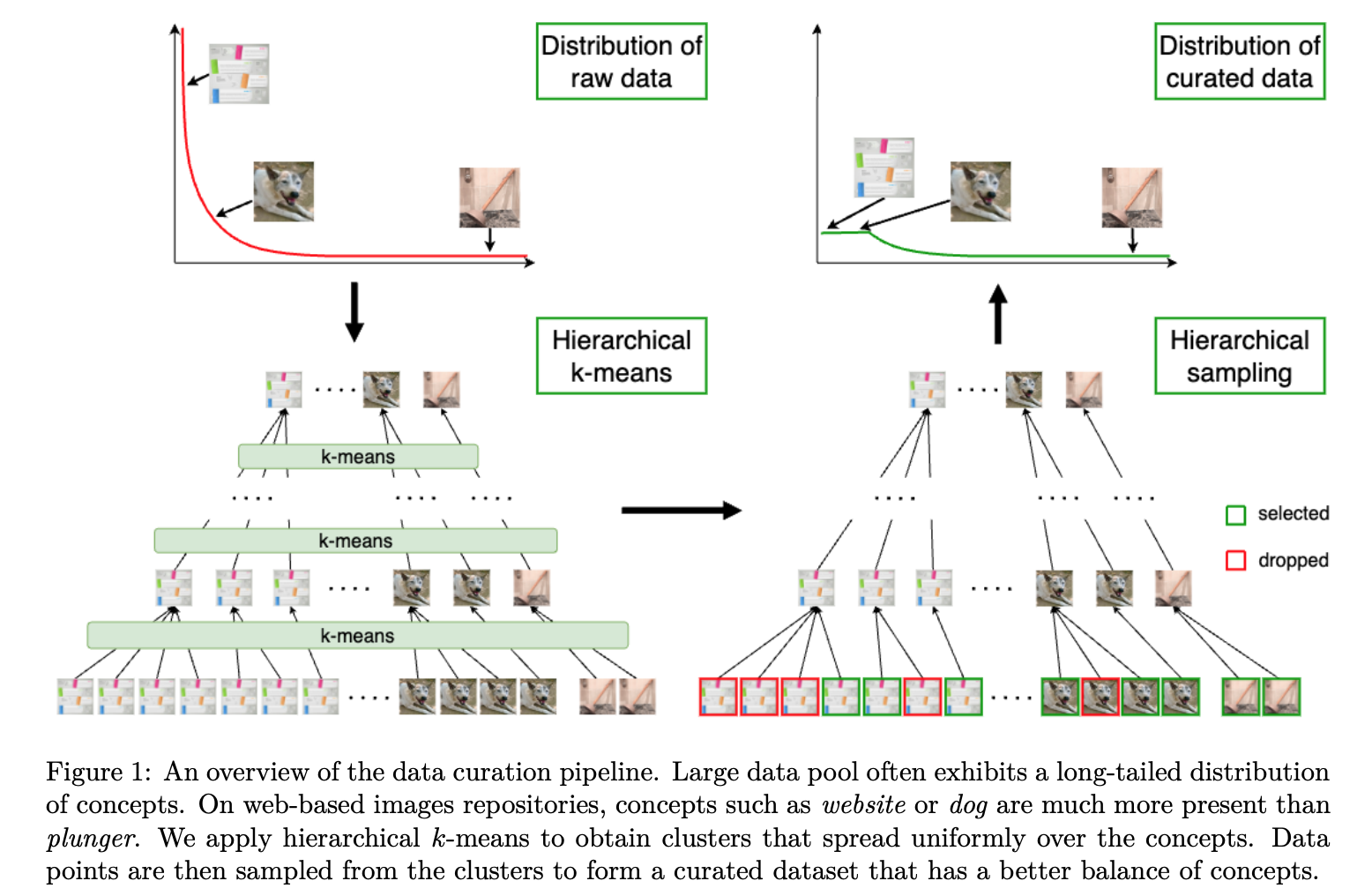
- algorithm: $k$-means clustering 반복
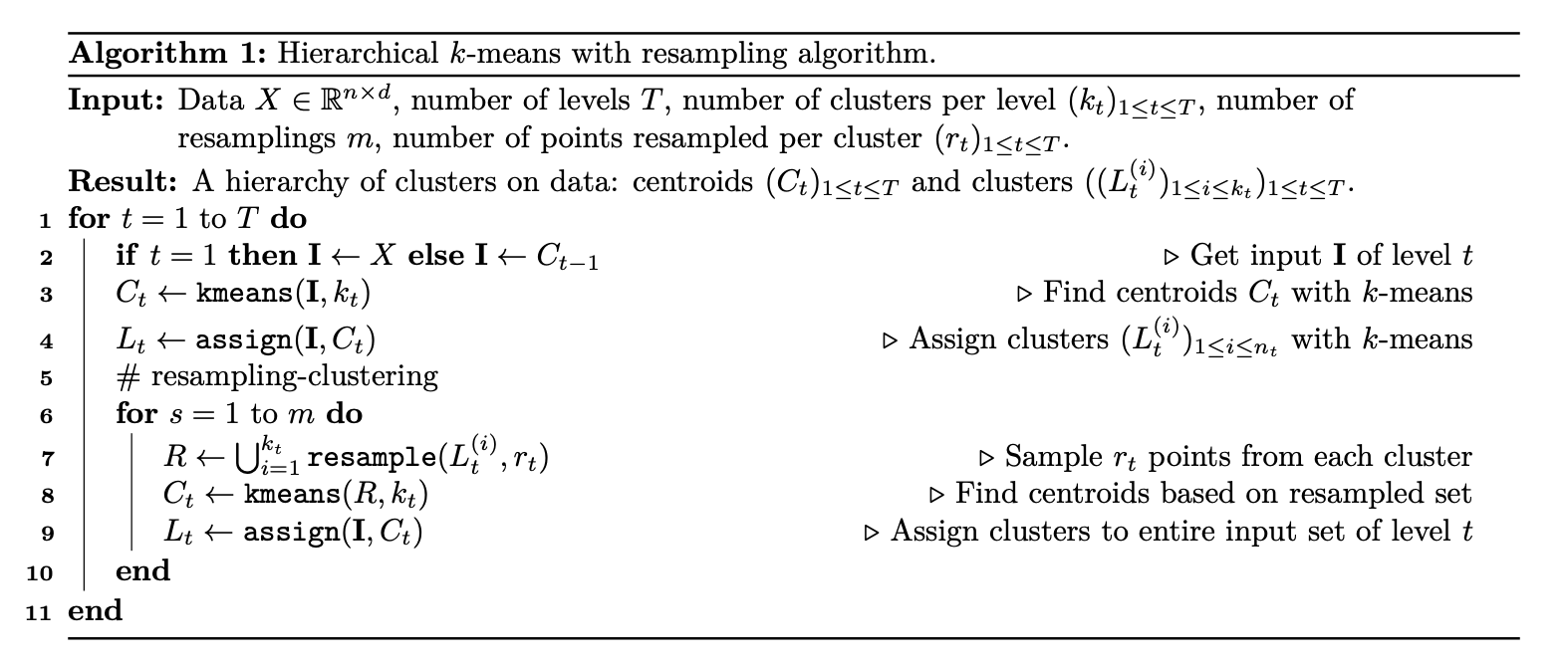
실험 결과
- Iterative $k$-means clustering algorithm 의 효과
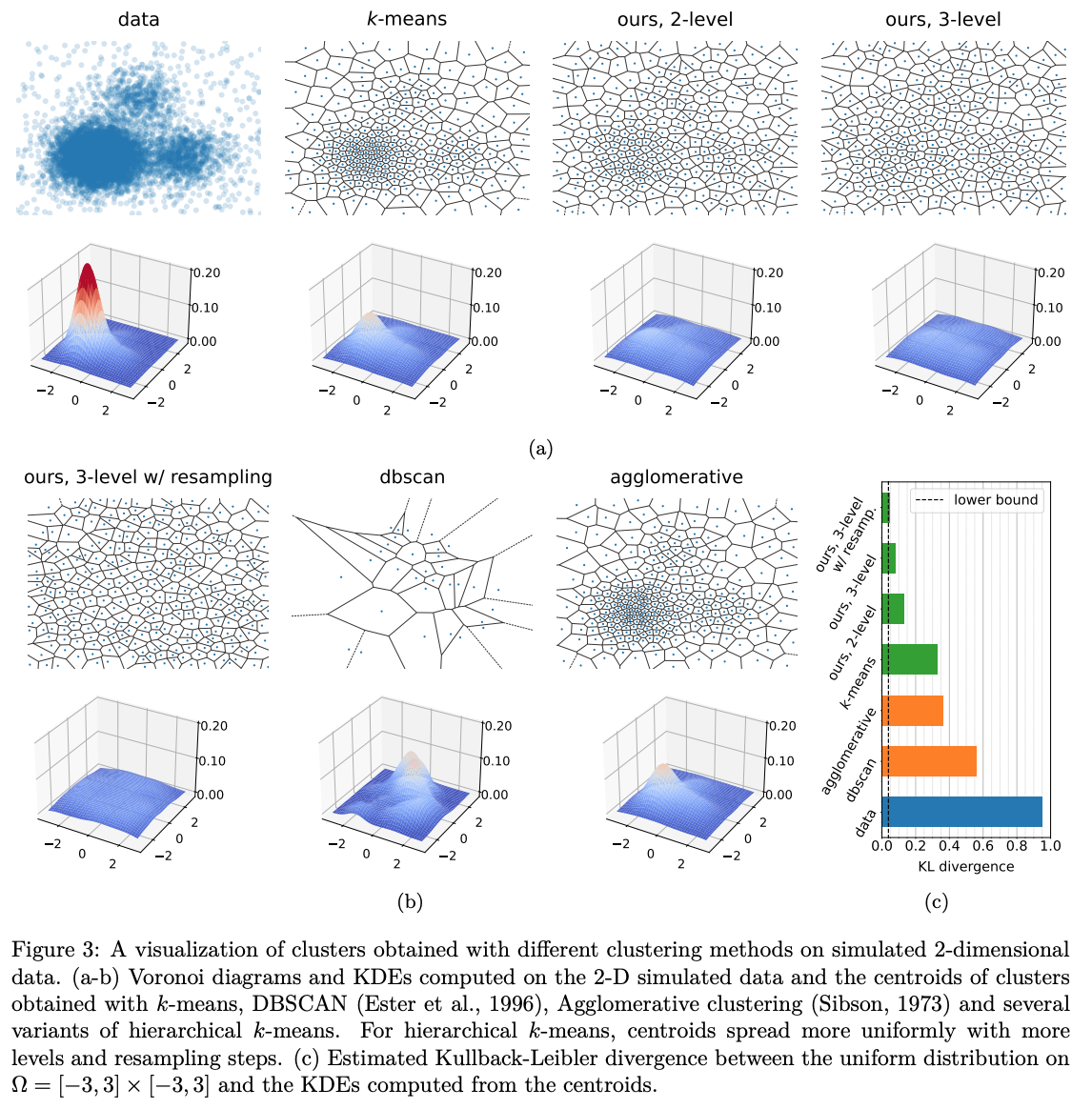
- imbalance 없애고 self-supervised learning 학습시 성능 향상