(논문 요약) DataComp-LM: In search of the next generation of training sets for language models (Paper)
핵심 내용
- filtered open data 로, compute-optimal model 개발
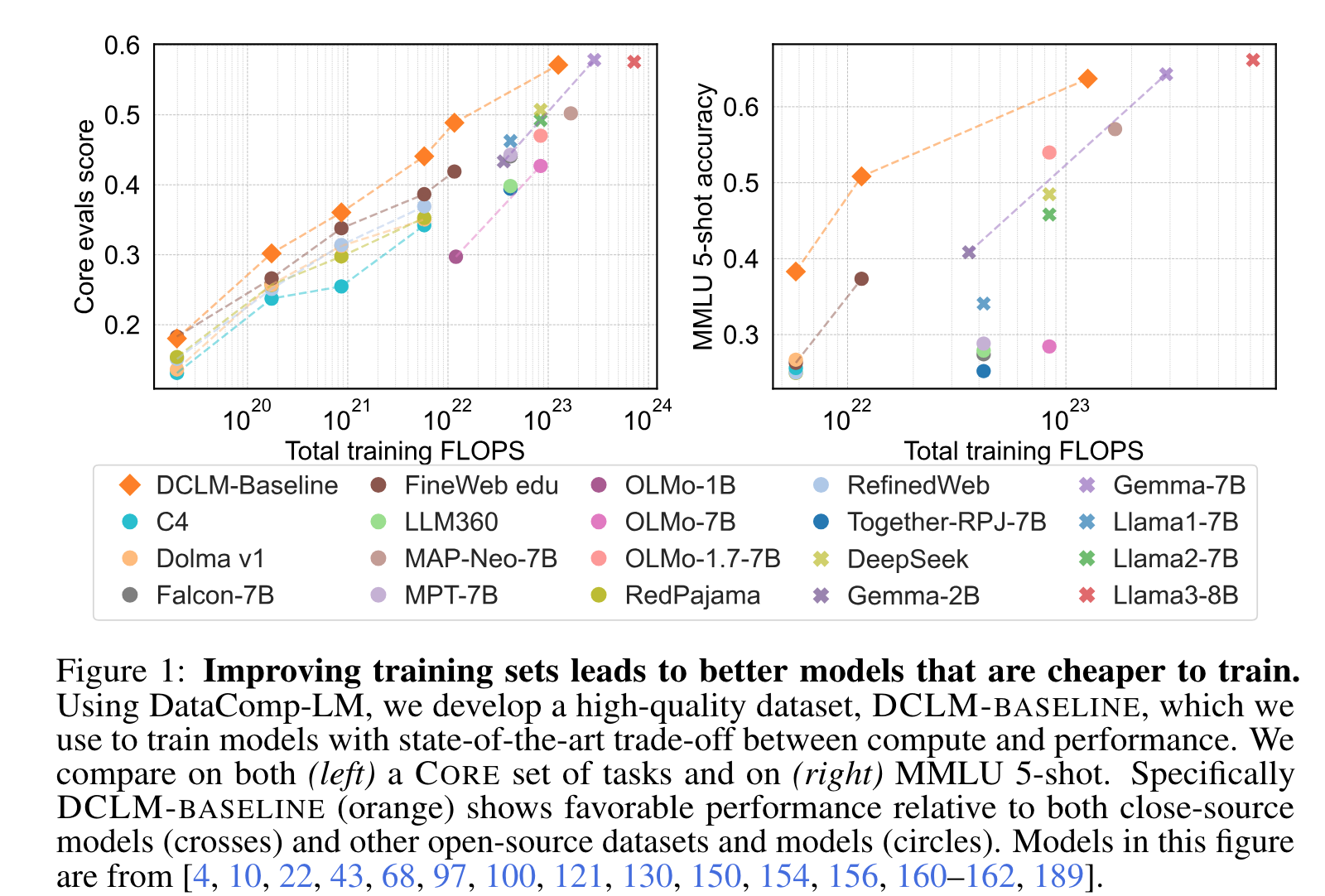
- 다양한 사이즈의 모델로 실험
- 데이터 filtering
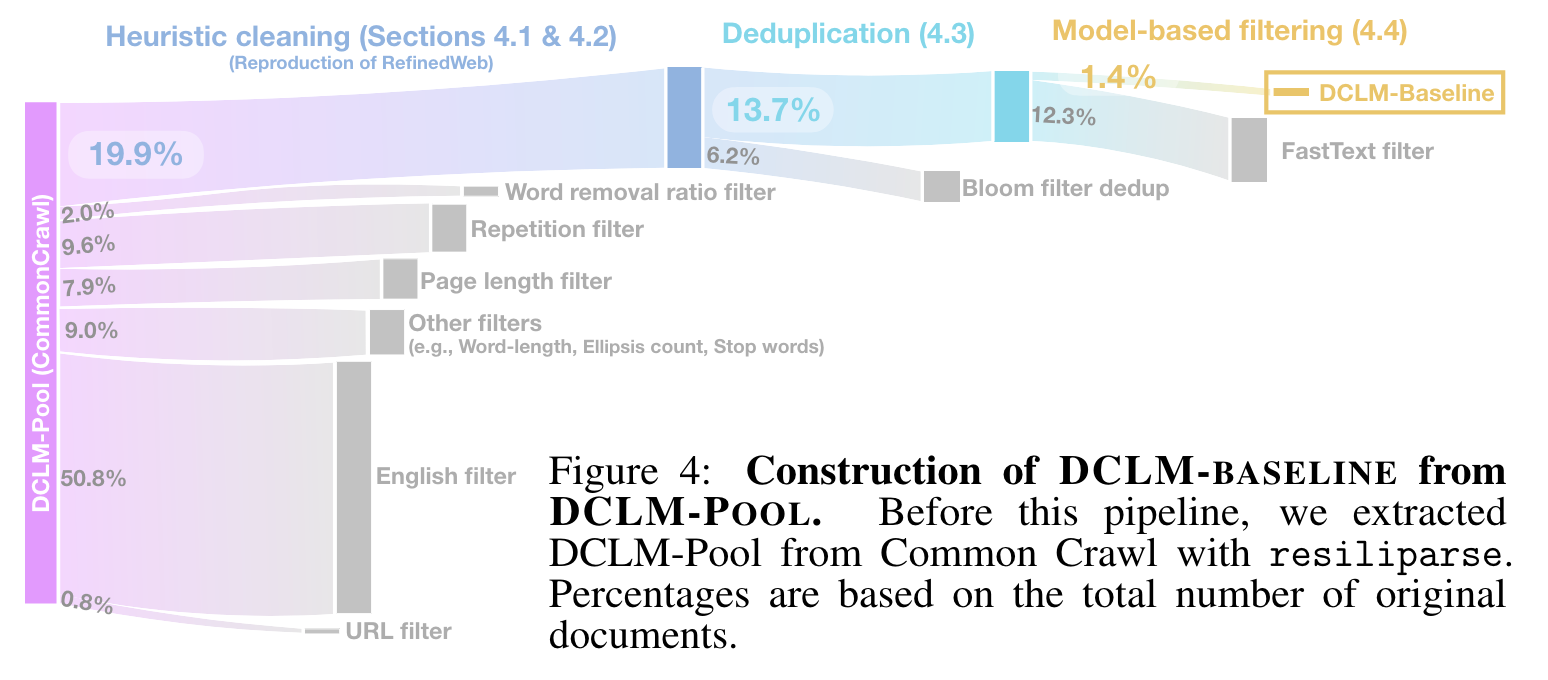
실험 세팅
- finetuning 없이, 다양한 분야에 관한 데이터 셋(e.g. coding, text-book, knowledge, and common-sense reasoning) 에서 성능 측정
- Core datasets: low-variance 22 tasks (e.g. HellaSwag, ARC-E, Big-Bench, BoolQ, CommonsenseQA)
- Extended datasets: all 53 tasks including Core datasets (e.g. GSM8K, LogiQA, MMLU, Math QA)
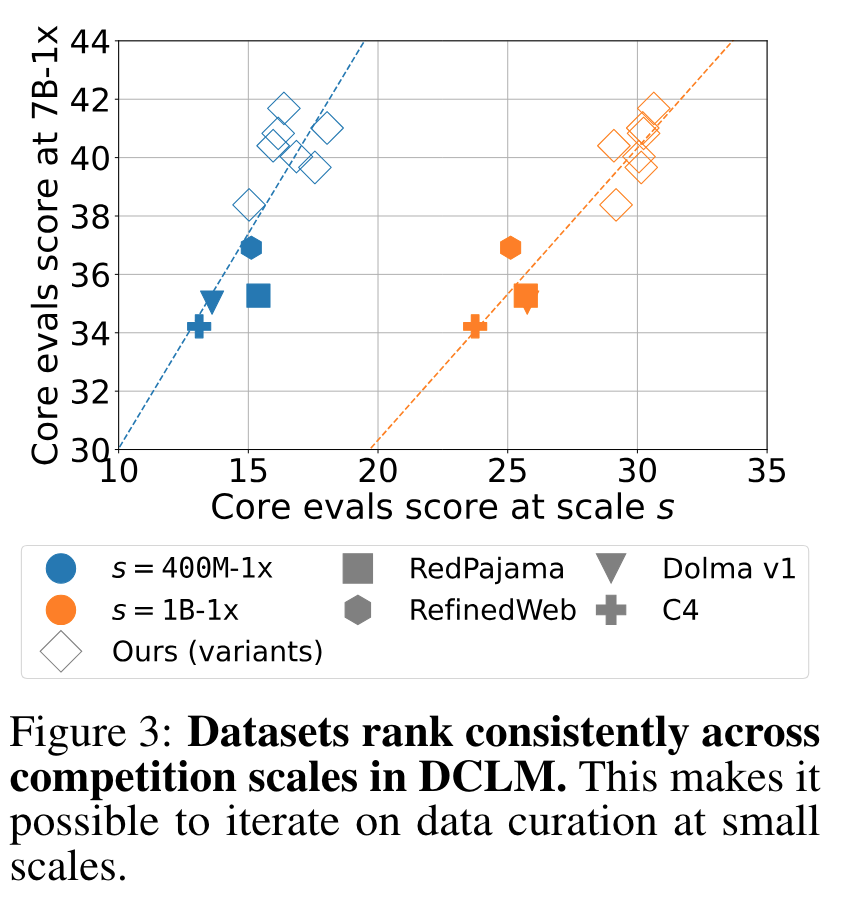
- 실험의 iteration 을 높이기 위하여, dataset quality 가 모델의 사이즈에 영향이 있는지를 실험 -> 모델 크기 상관없이 dataset 을 rank 세울수 있음
실험 결과
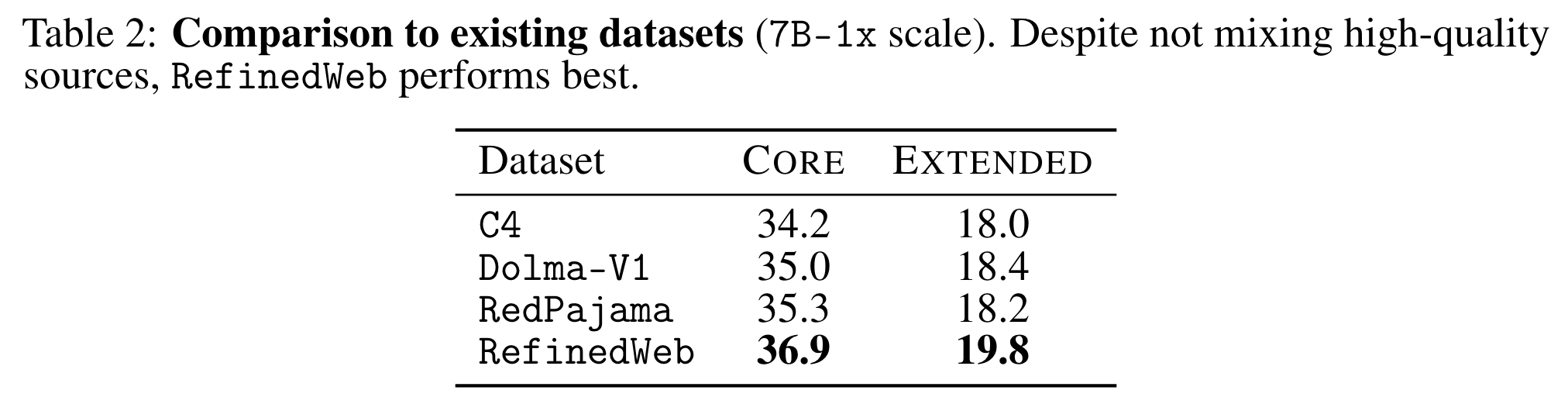
- C4, Dolma-V1, RedPajama, RefinedWeb 중 RefinedWeb 로 학습했을때 가장 성능이 좋음 -> RefinedWeb 의 filter 채택
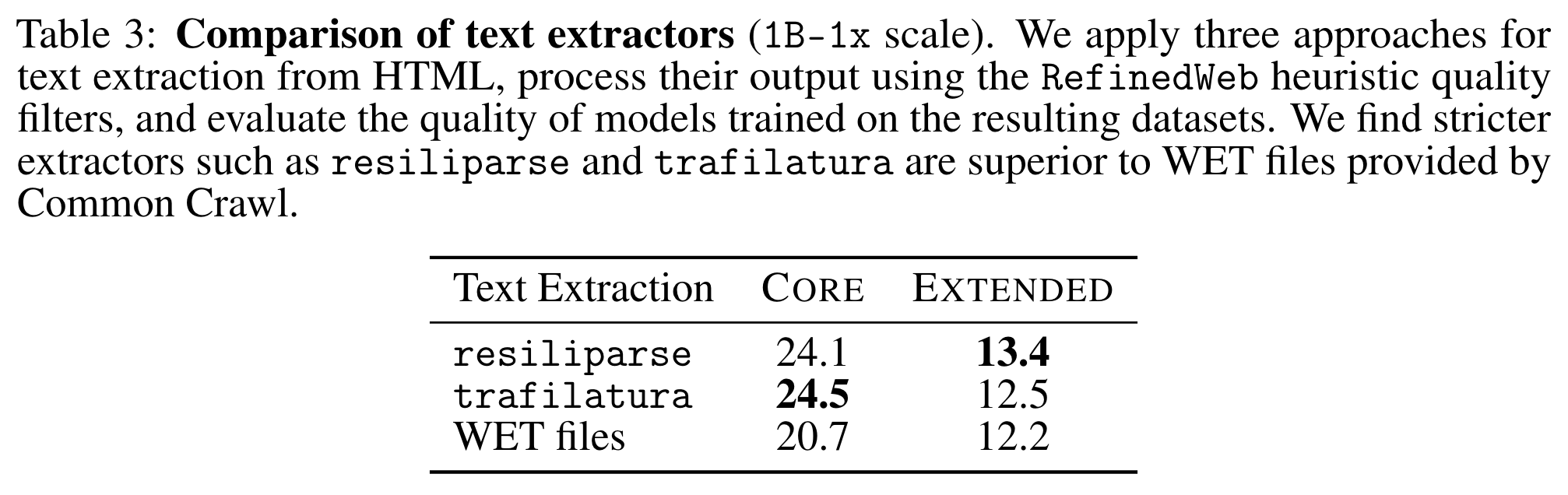
- HTML 에서 content 뽑는 extractor 는 성능 좋고 빠른 resiliparse 채택 (8× faster than trafilatura)
- fasttext 로 quality 를 평가하여 학습 데이터를 고르는 경우 가장 성능이 높음
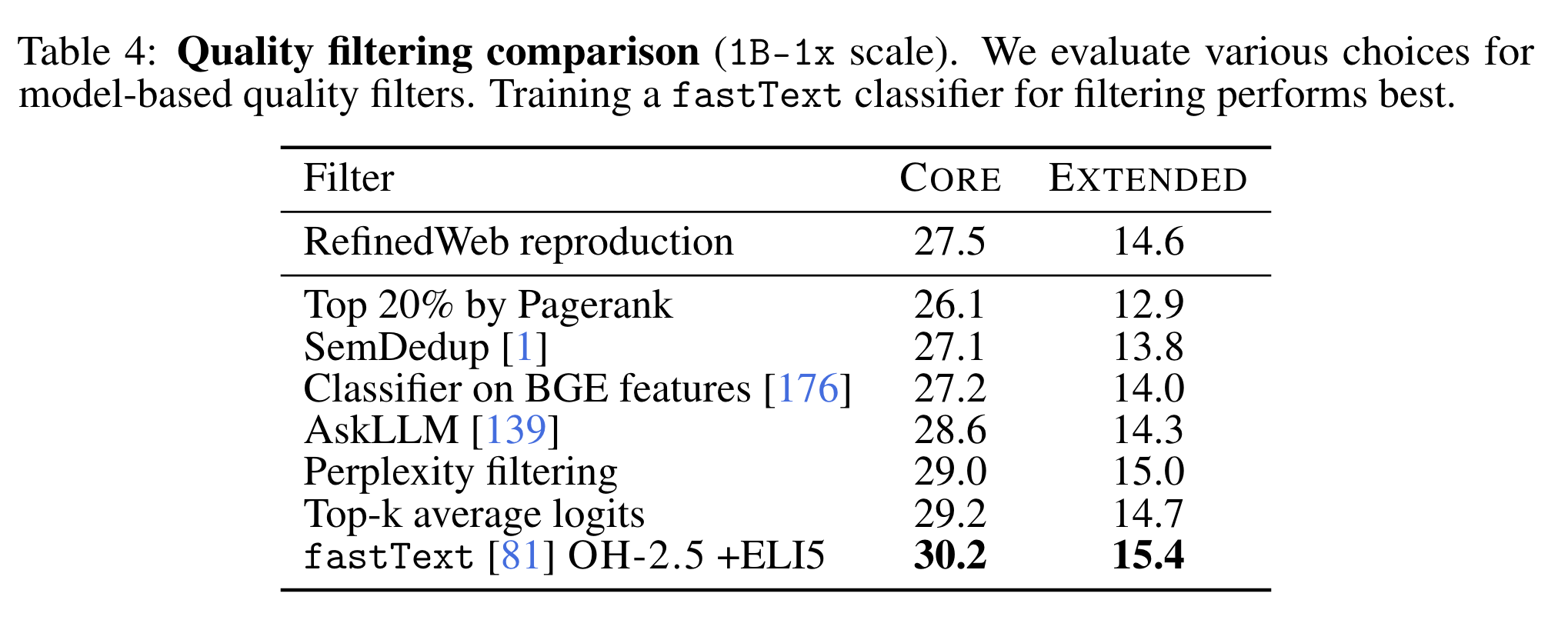
- SemDedup: similar information 을 depulicate 하는 모델
- AskLLM: LLM 에 학습 데이터로서의 가치를 직접 질의
- Perplexity filtering: CCNet 으로 perplexity 낮은 문서 고름
- Top-k average logits: “average the top-k model logits over all words in a document to score how confident a model is that the correct words are within k reasonable choices” 라고 함…
- fastText (OH-2.5+ELI5): high quality data (target 이 OH-2.5 와 ELI5 데이터셋) 와 low quality data (random sample) 를 구분하는 binary classifier 학습하여 이 모델을 filter 로 활용
- DCLM-BASELINE (filtered data 로 학습된 모델) 은 llama3 와 gemma 정도의 성능을 보임