**(논문 요약) ** (Paper) Q-GaLore: Quantized GaLore with INT4 Projection and Layer-Adaptive Low-Rank Gradients
핵심 내용
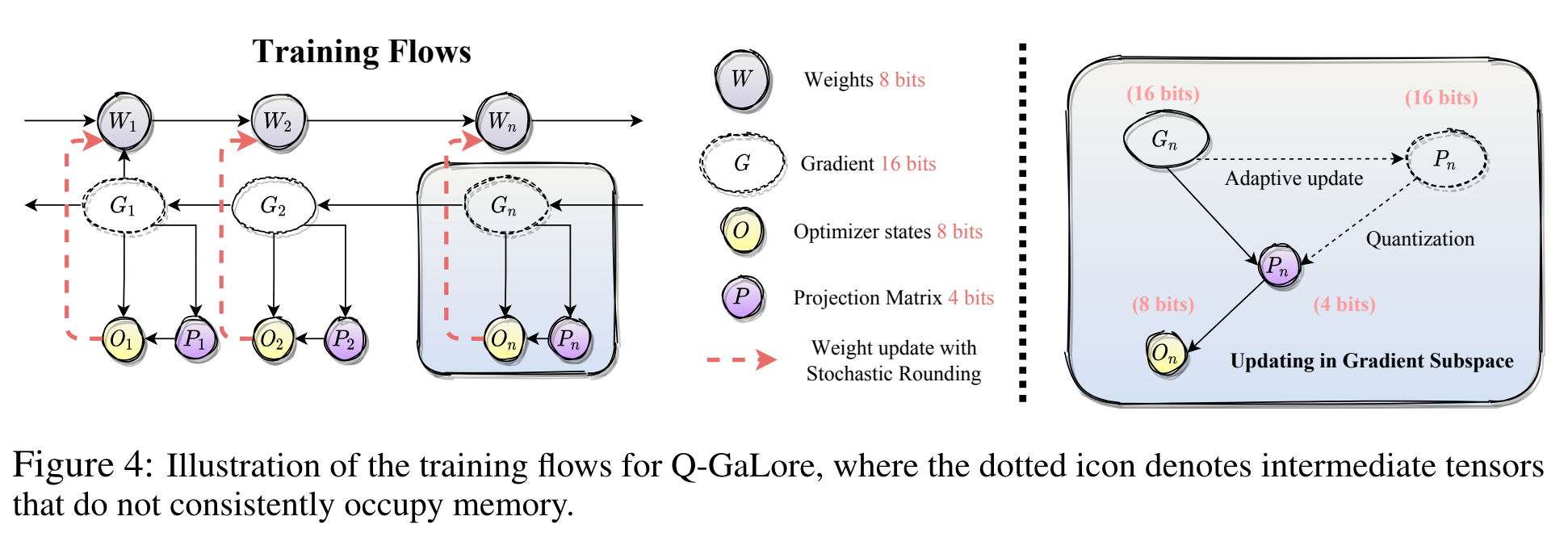
- GaLore 에서 2가지 관찰
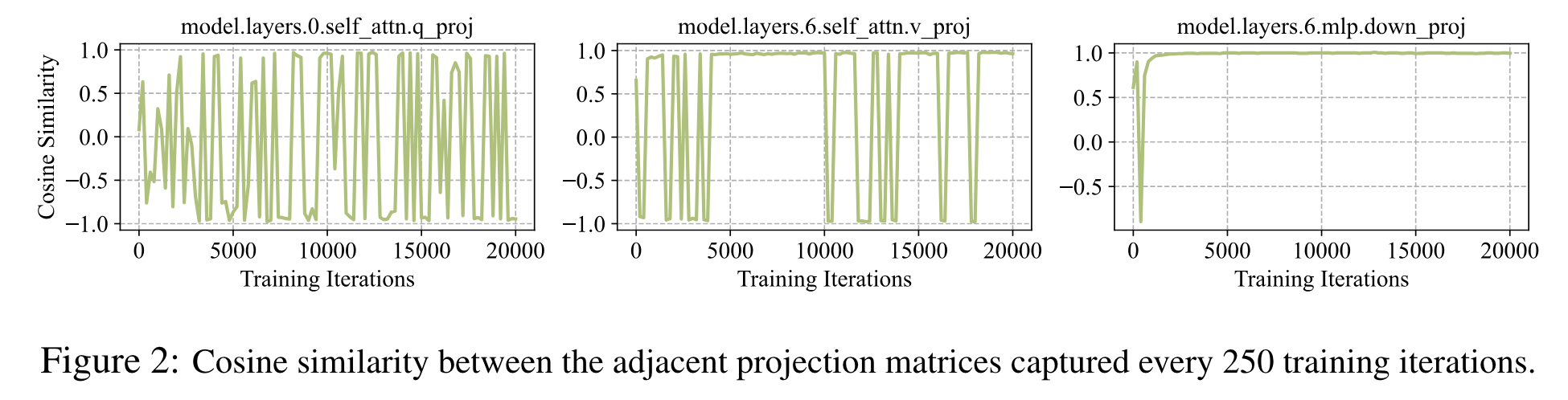
- 일부 layer 에서는 gradient subspace 가 빠르게 수렴
- projection matrices 는 low-bit quantization 해도 성능이 유지됨 (INT4 사용)

- 일부 layer 에서는 gradient subspace 가 빠르게 수렴
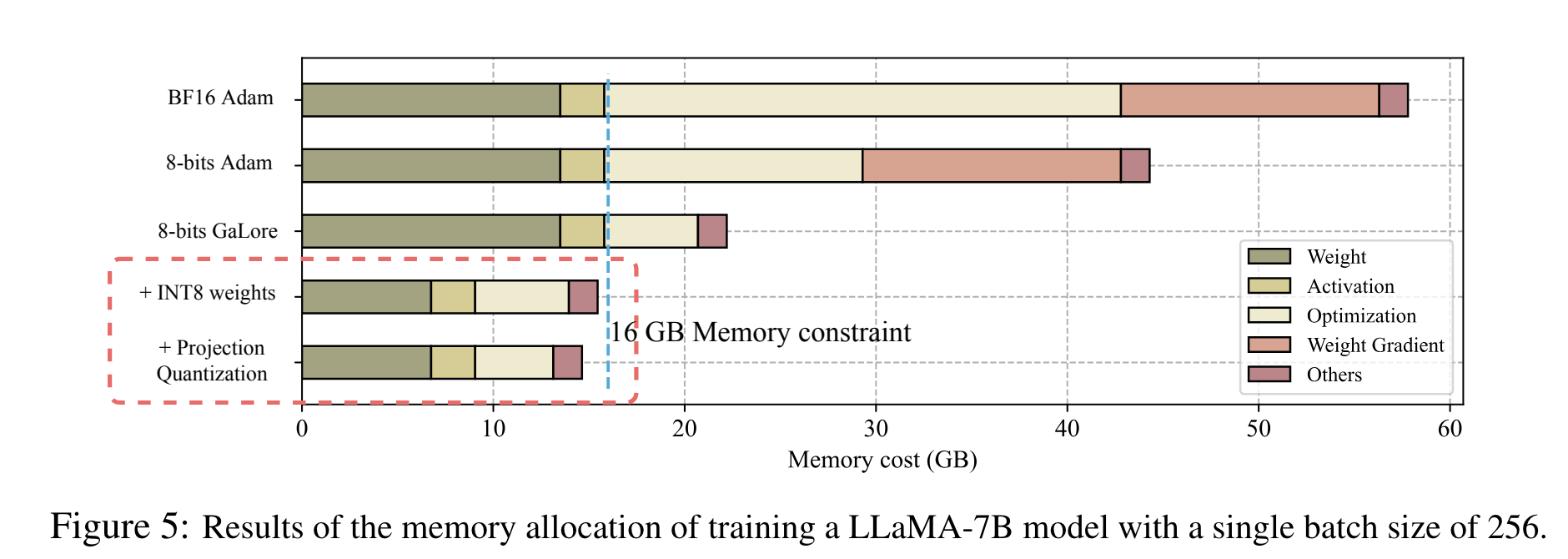
weights 는 INT8 사용하여, LLaMA-7B 를 NVIDIA RTX 4060 Ti 에서 학습시 16 GB memory 만 필요

- Algorithm
- $t$ iteration 마다 projection update 하는 것을 $k$ interval 동안 cosine similarity 가 40% 이상 유지되면, $t\rightarrow 2t$ 로 증가
- weight update
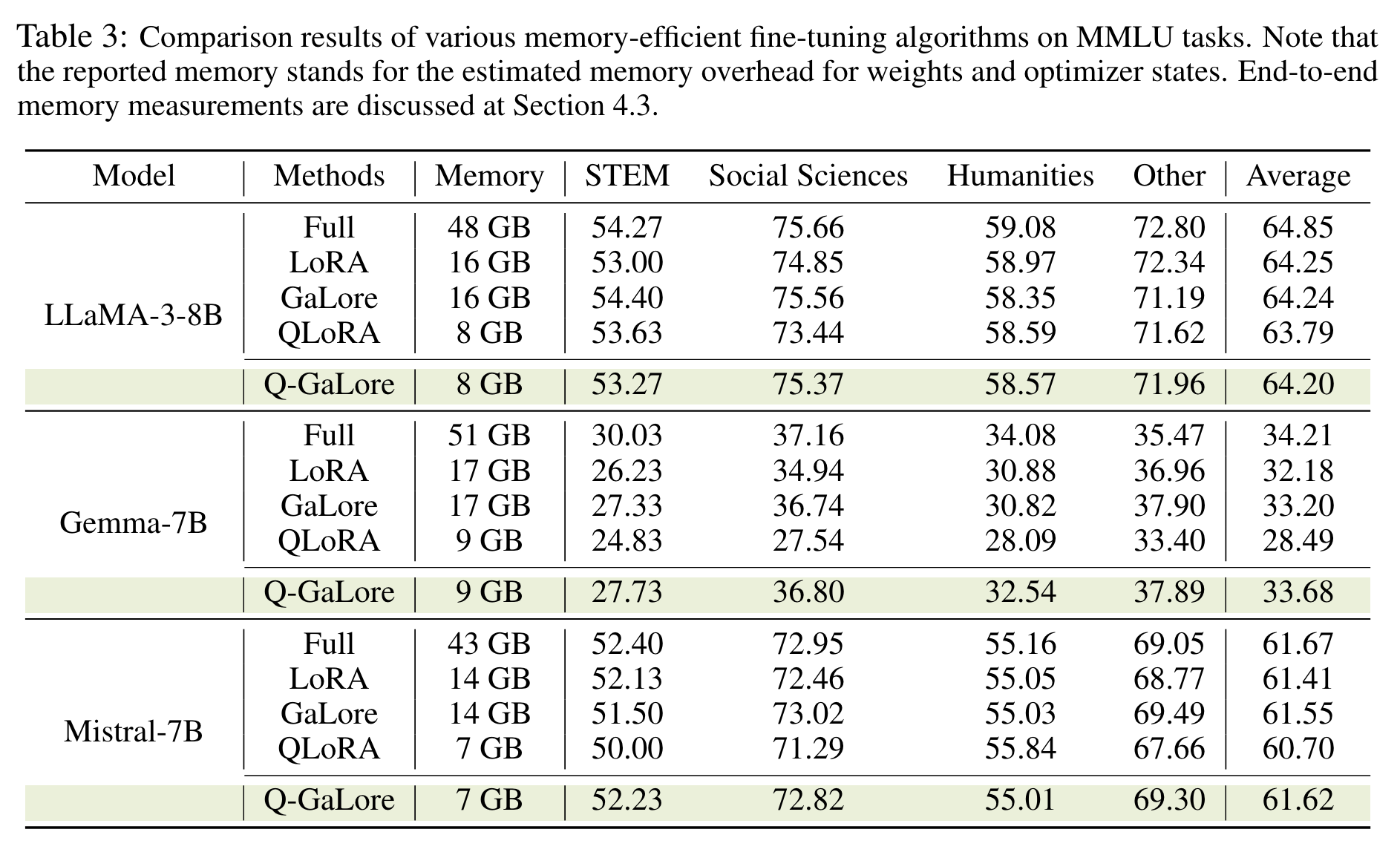
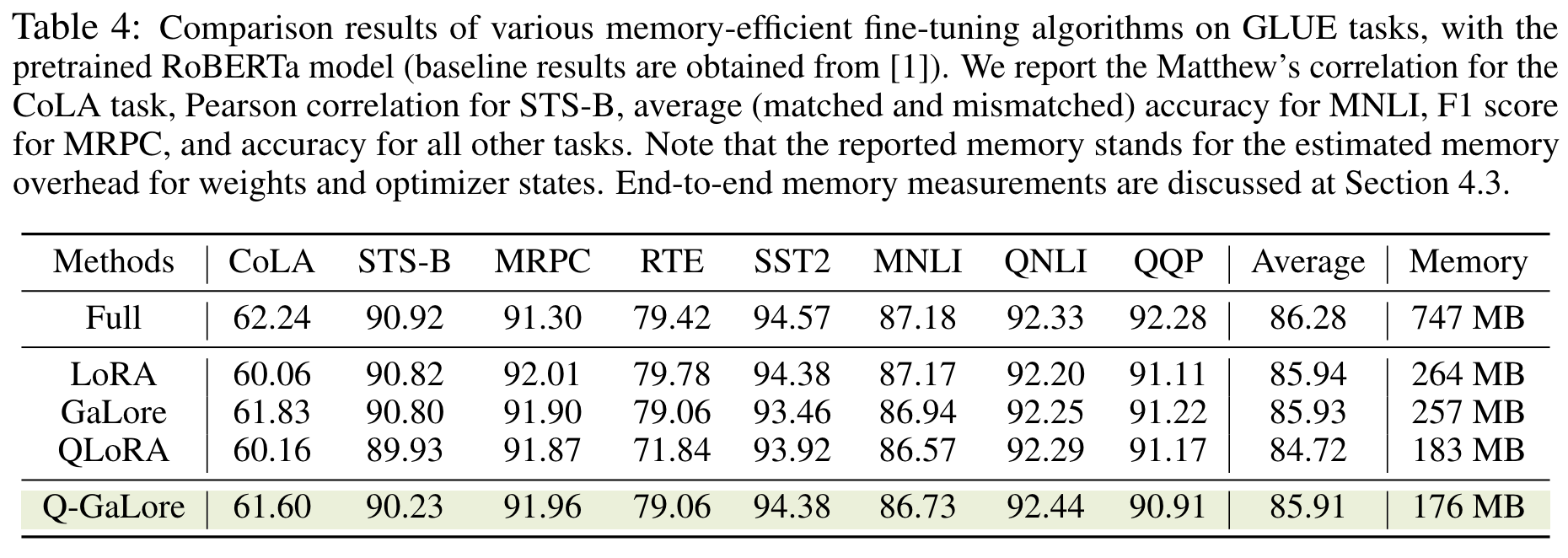
실험 결과
- 성능이 QLoRA 보다 나음