(논문 요약) Layer-Condensed KV Cache for Efficient Inference of Large Language Models (paper)
핵심 내용
- 몇몇 layer 에서는 standard attention, 그 외 layer 에서는 top layer 에서만 Key, Value 사용.
- save memory consumption by caching fewer layers
- omit the key-value computation and save key-value parameters
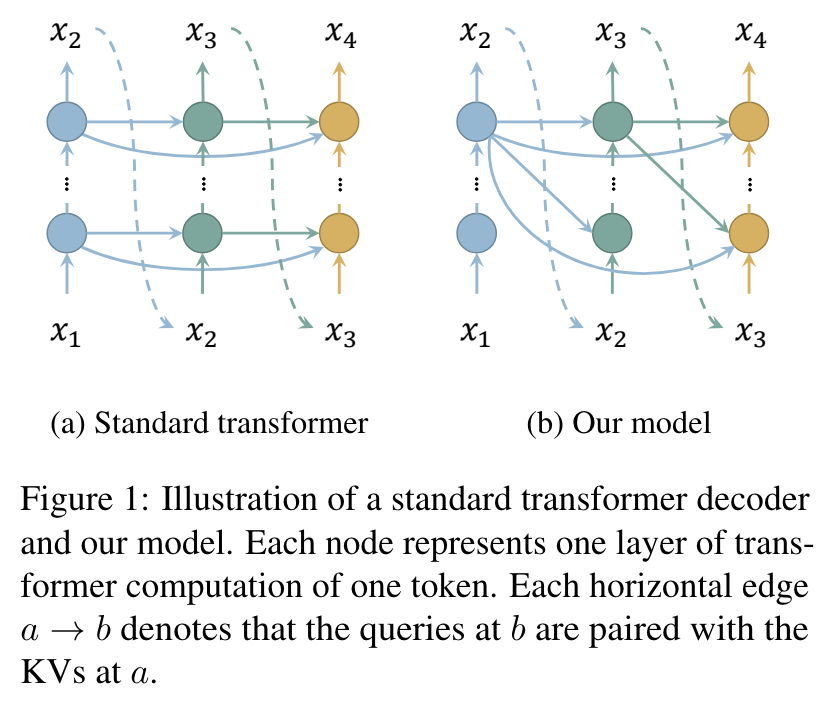
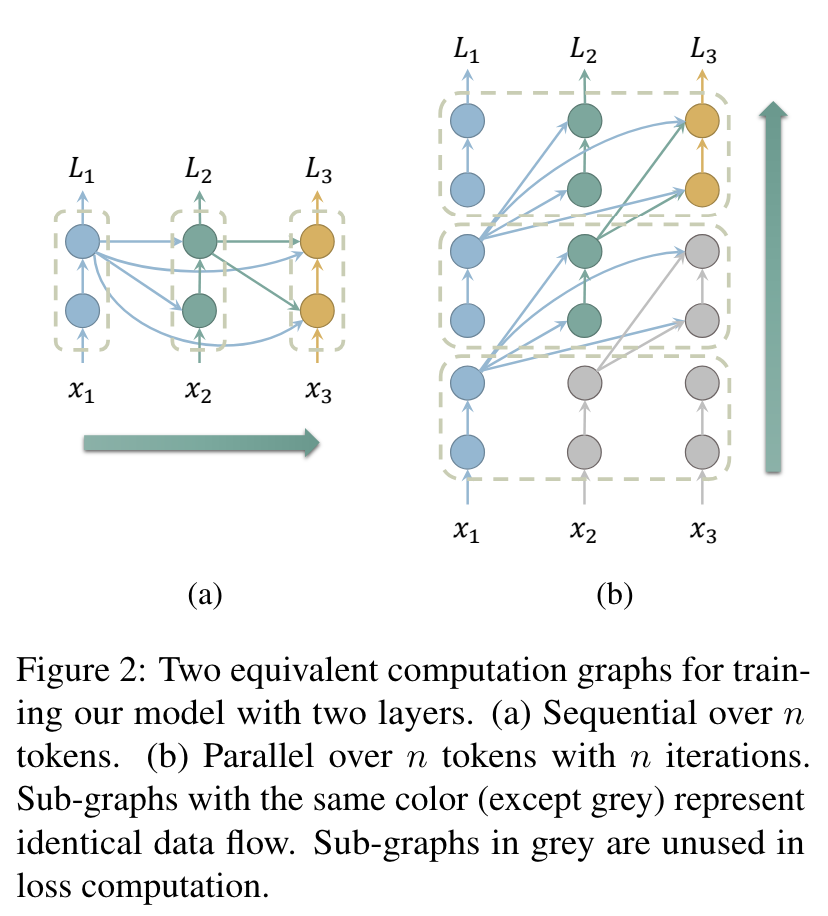
- 학습
- perform $n$ iterations of bottom-up transformer computation on all tokens in parallel
- in each iteration, pair the queries of all layers with KVs of the top layer from the previous iteration
- compute the cross entropy loss only after the last iteration
실험 결과
- throughput 비교 (w==n_standard_attention_layers)
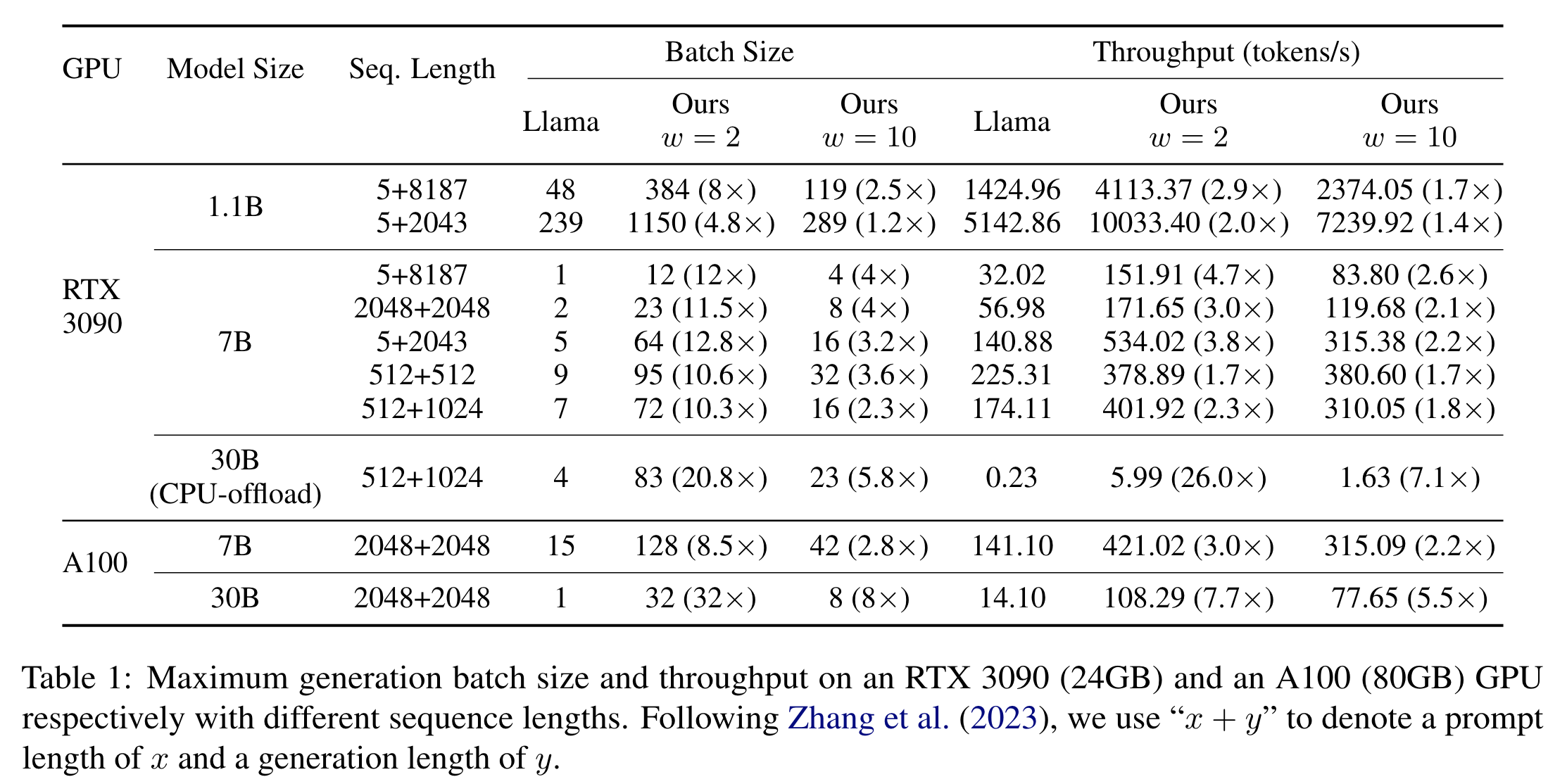
- scratch 학습 with TinyLlama on a 100B subset of the SlimPajama dataset