(논문 요약) Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search (Paper)
핵심 내용
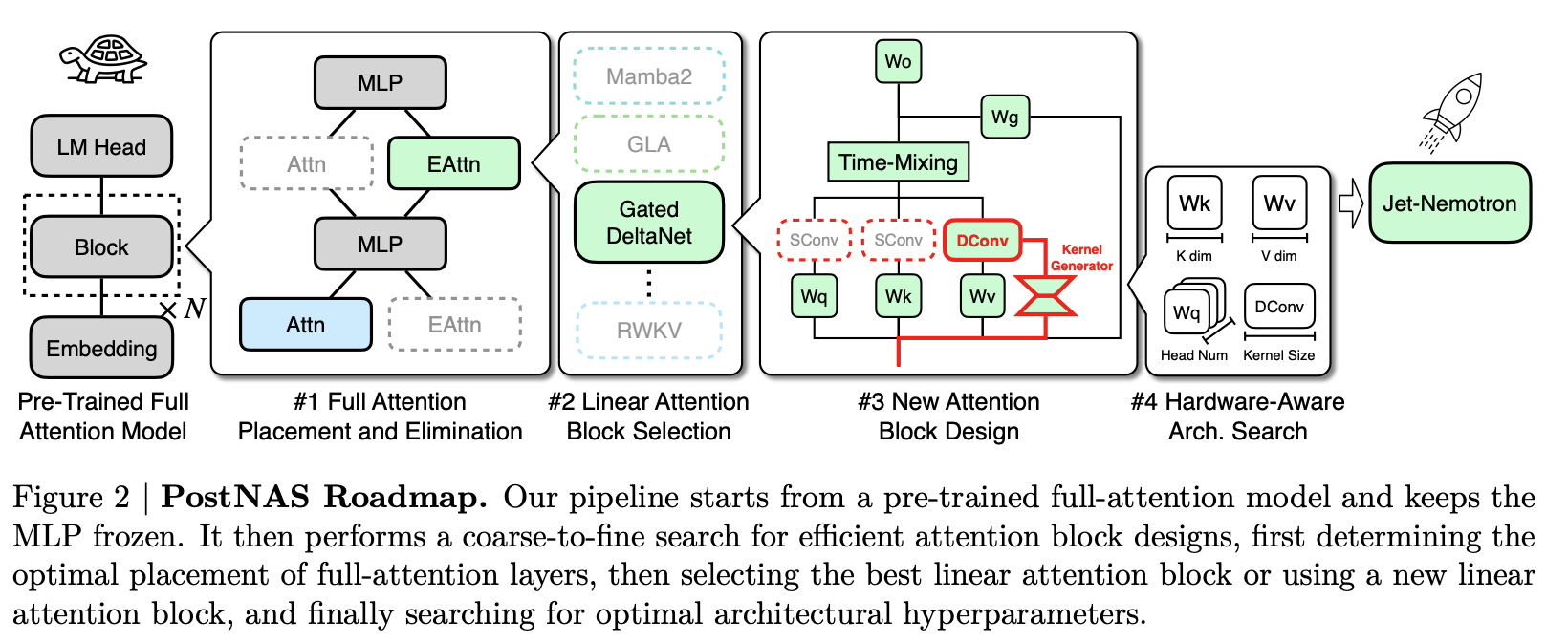
- PostNAS
- full-attention layer placement and elimination (MLP 는 고정)
- linear attention block selection (여러 linear attention block 을 일괄적으로 사용하여 성능 비교)
- designing new attention blocks (static conv -> dynamic conv)
- hardware-aware hyperparameter search
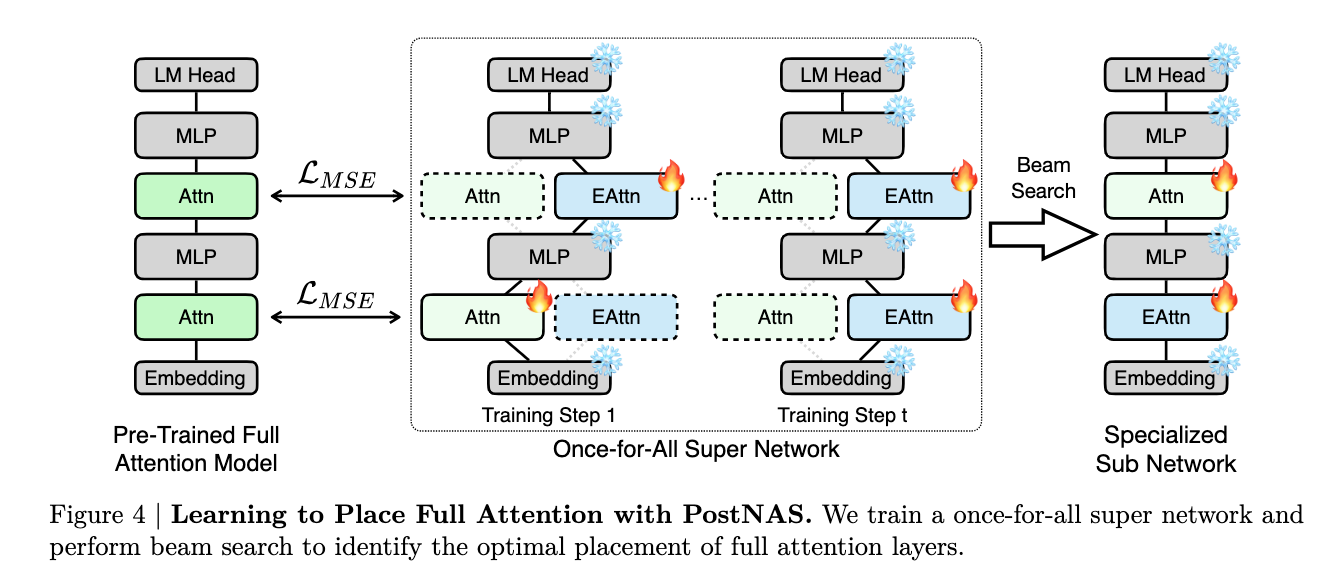
- full-attention layer placement and elimination 상세 내용
- 각 attention 을 full-attention, linearn-attention (efficient) 를 추가하여 Supernetwork 생성
- feature distillation 학습
dynamic conv: kernel generator network 로 input 을 바탕으로 conv kernel weights 를 생성하여 conv 를 수행.
hardware-aware hyperparameter search 상세 내용
- KV cache size is the most critical factor influencing long-context and long-generation throughput. When the KV cache size is constant, models with different parameter counts exhibit similar generation throughput. This is because the decoding stage is typically memory-bandwidth-bound rather than compute-bound.
- KV cache size 고정 후, K,V dimensions, attention heads 숫자를 grid search
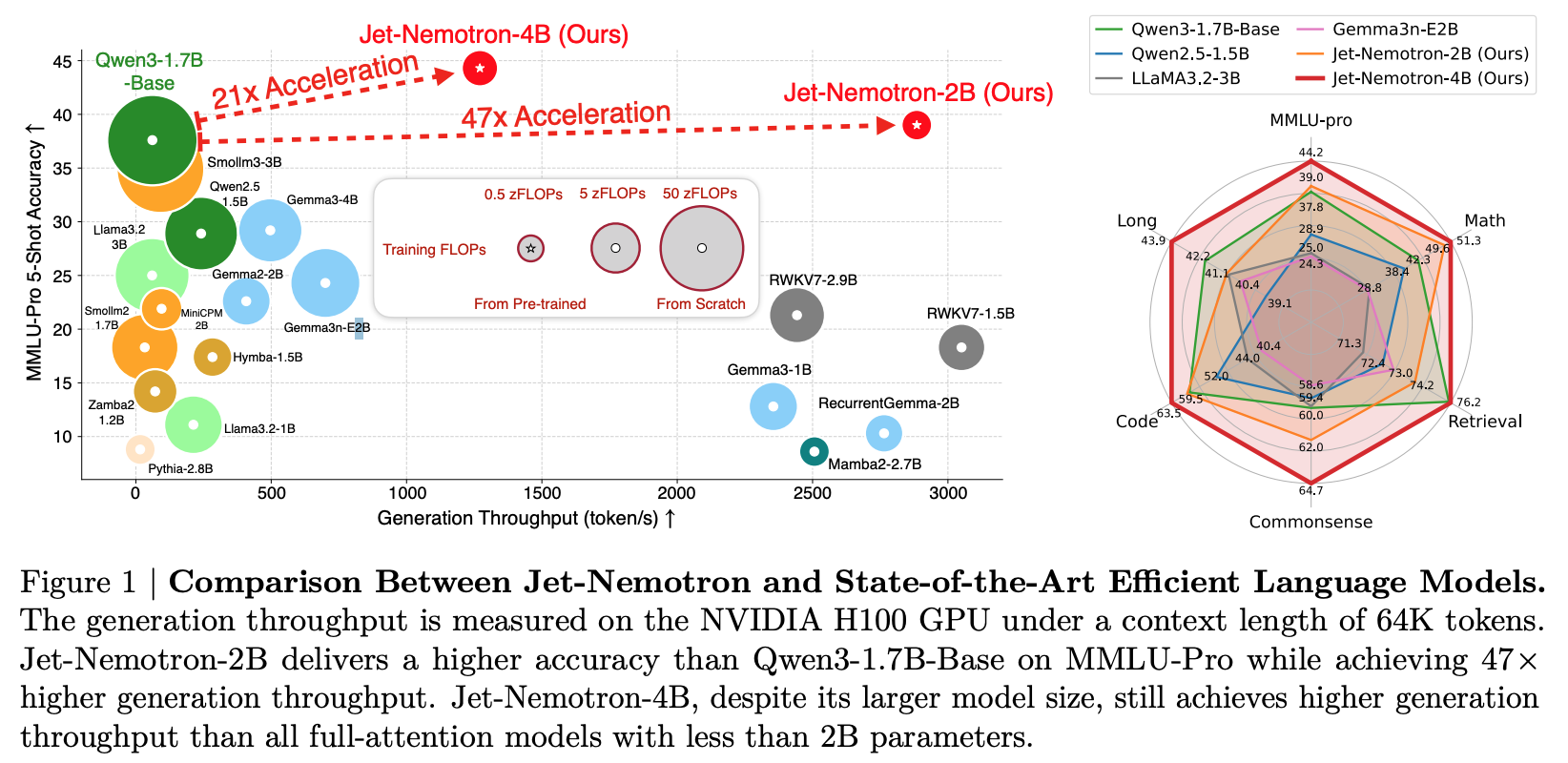
실험 결과