(논문 요약) Hogwild! Inference: Parallel LLM Generation via Concurrent Attention (Paper)
핵심 내용
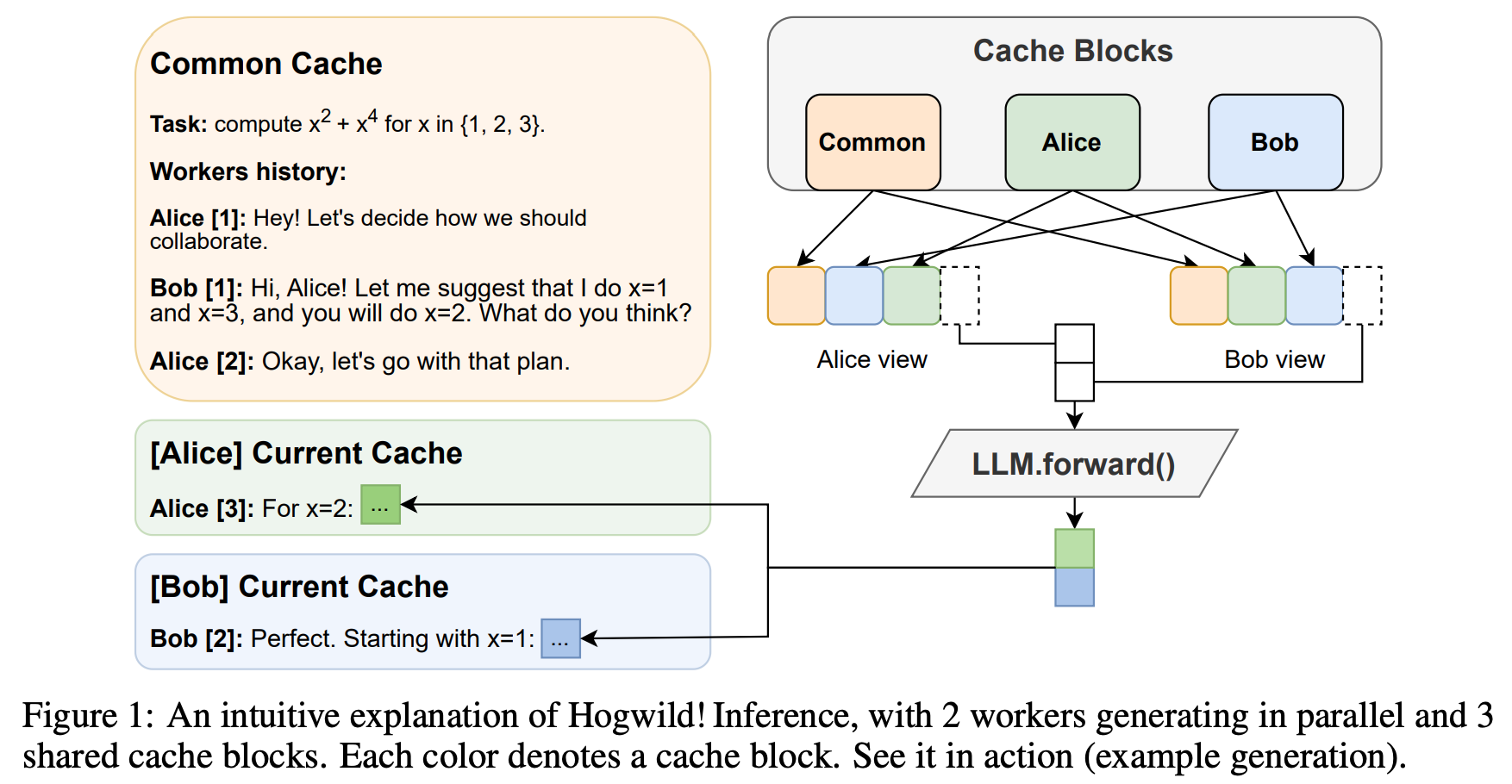
- run LLM “workers” in parallel, allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate
- 개별 worker 가 symmetric 하게 비슷한 양의 tokens 생성하여 실험함.
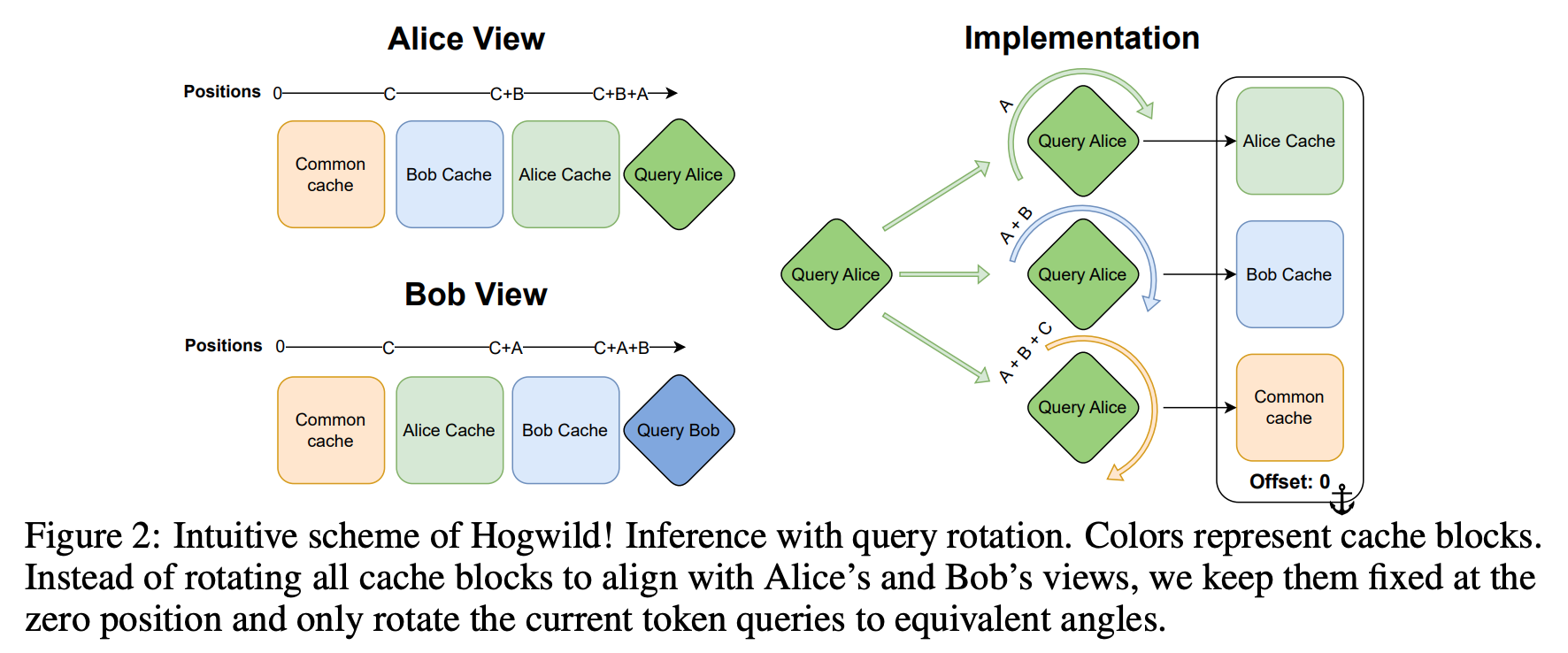
- position embedding 은 필요에 맞게 더해서 계산.